 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Visual Tracking with Exemplar Transformers
Dec 17, 2021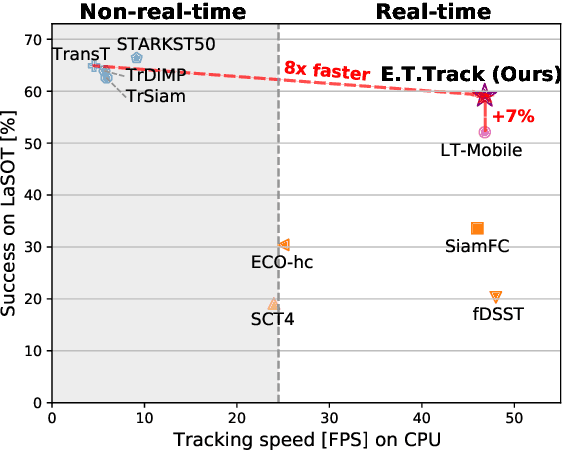
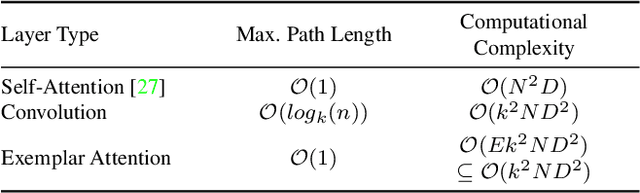
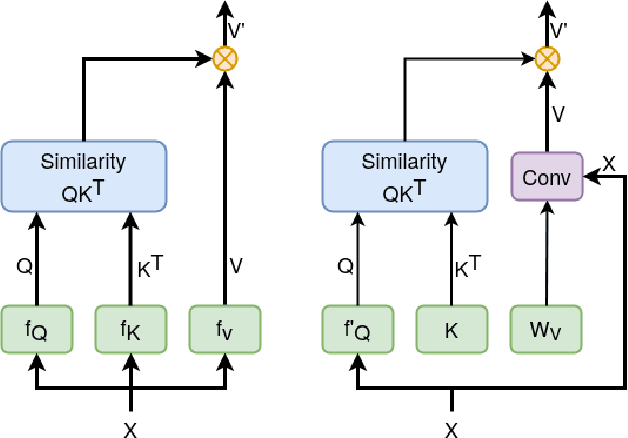

The design of more complex and powerful neural network models has significantly advanced the state-of-the-art in visual object tracking. These advances can be attributed to deeper networks, or to the introduction of new building blocks, such as transformers. However, in the pursuit of increased tracking performance, efficient tracking architectures have received surprisingly little attention. In this paper, we introduce the Exemplar Transformer, an efficient transformer for real-time visual object tracking. E.T.Track, our visual tracker that incorporates Exemplar Transformer layers, runs at 47 fps on a CPU. This is up to 8 times faster than other transformer-based models, making it the only real-time transformer-based tracker. When compared to lightweight trackers that can operate in real-time on standard CPUs, E.T.Track consistently outperforms all other methods on the LaSOT, OTB-100, NFS, TrackingNet and VOT-ST2020 datasets. The code will soon be released on https://github.com/visionml/pytracking.
MEFNet: Multi-scale Event Fusion Network for Motion Deblurring
Nov 30, 2021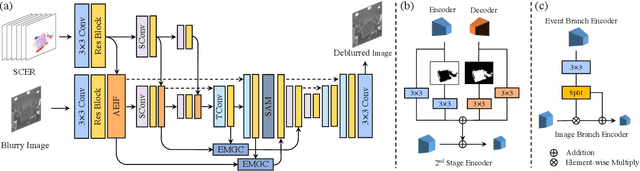
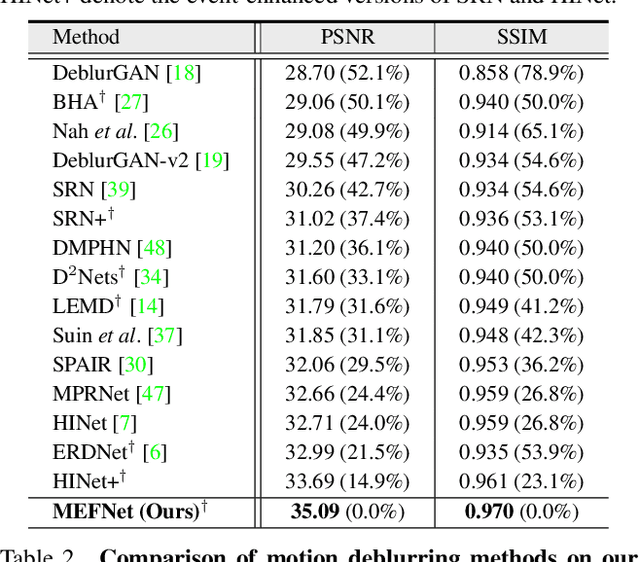
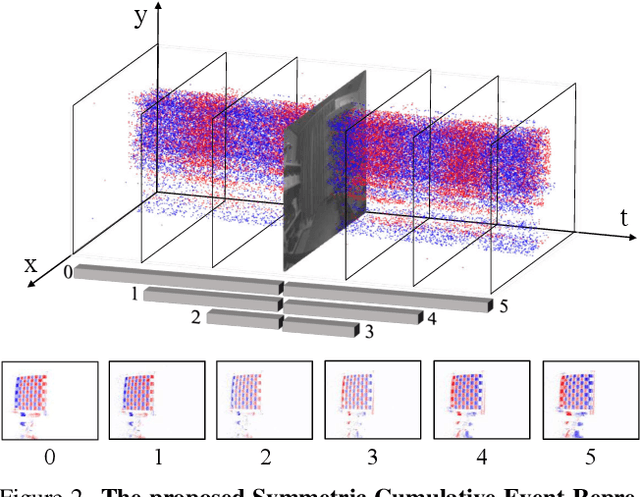
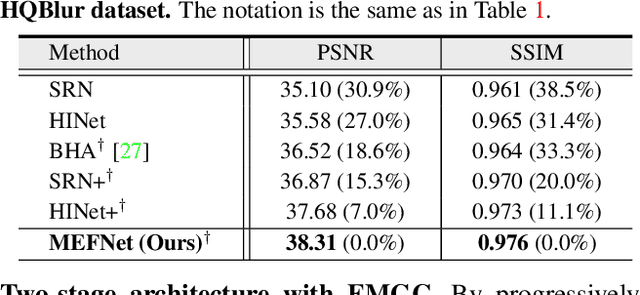
Traditional frame-based cameras inevitably suffer from motion blur due to long exposure times. As a kind of bio-inspired camera, the event camera records the intensity changes in an asynchronous way with high temporal resolution, providing valid image degradation information within the exposure time. In this paper, we rethink the event-based image deblurring problem and unfold it into an end-to-end two-stage image restoration network. To effectively utilize event information, we design (i) a novel symmetric cumulative event representation specifically for image deblurring, and (ii) an affine event-image fusion module applied at multiple levels of our network. We also propose an event mask gated connection between the two stages of the network so as to avoid information loss. At the dataset level, to foster event-based motion deblurring and to facilitate evaluation on challenging real-world images, we introduce the High-Quality Blur (HQBlur) dataset, captured with an event camera in an illumination-controlled optical laboratory. Our Multi-Scale Event Fusion Network (MEFNet) sets the new state of the art for motion deblurring, surpassing both the prior best-performing image-based method and all event-based methods with public implementations on the GoPro (by up to 2.38dB) and HQBlur datasets, even in extreme blurry conditions. Source code and dataset will be made publicly available.
DAFormer: Improving Network Architectures and Training Strategies for Domain-Adaptive Semantic Segmentation
Nov 29, 2021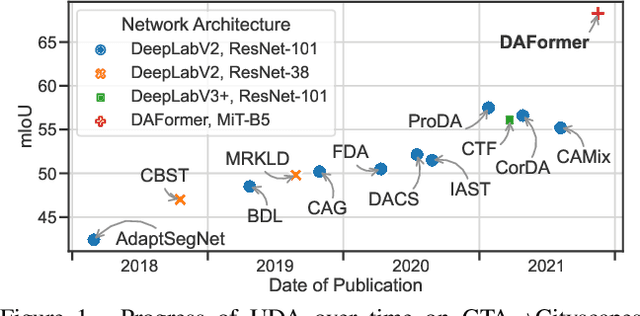
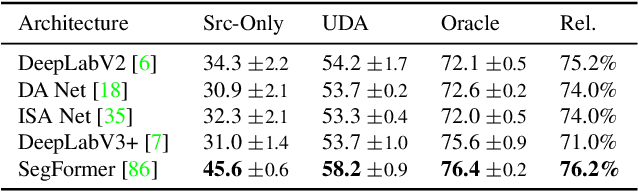

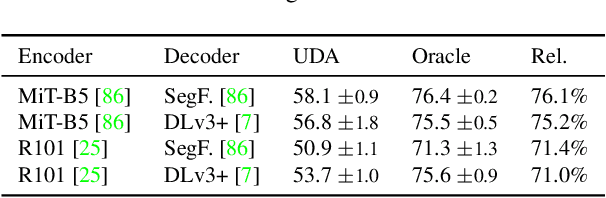
As acquiring pixel-wise annotations of real-world images for semantic segmentation is a costly process, a model can instead be trained with more accessible synthetic data and adapted to real images without requiring their annotations. This process is studied in unsupervised domain adaptation (UDA). Even though a large number of methods propose new adaptation strategies, they are mostly based on outdated network architectures. As the influence of recent network architectures has not been systematically studied, we first benchmark different network architectures for UDA and then propose a novel UDA method, DAFormer, based on the benchmark results. The DAFormer network consists of a Transformer encoder and a multi-level context-aware feature fusion decoder. It is enabled by three simple but crucial training strategies to stabilize the training and to avoid overfitting DAFormer to the source domain: While the Rare Class Sampling on the source domain improves the quality of pseudo-labels by mitigating the confirmation bias of self-training towards common classes, the Thing-Class ImageNet Feature Distance and a learning rate warmup promote feature transfer from ImageNet pretraining. DAFormer significantly improves the state-of-the-art performance by 10.8 mIoU for GTA->Cityscapes and 5.4 mIoU for Synthia->Cityscapes and enables learning even difficult classes such as train, bus, and truck well. The implementation is available at https://github.com/lhoyer/DAFormer.
3D Compositional Zero-shot Learning with DeCompositional Consensus
Nov 29, 2021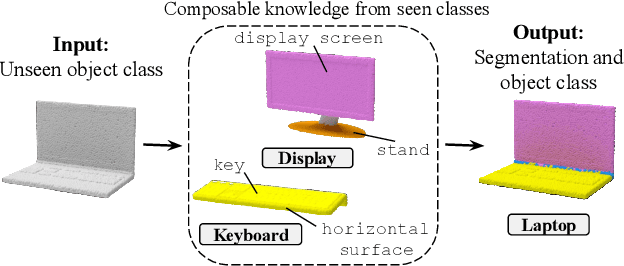
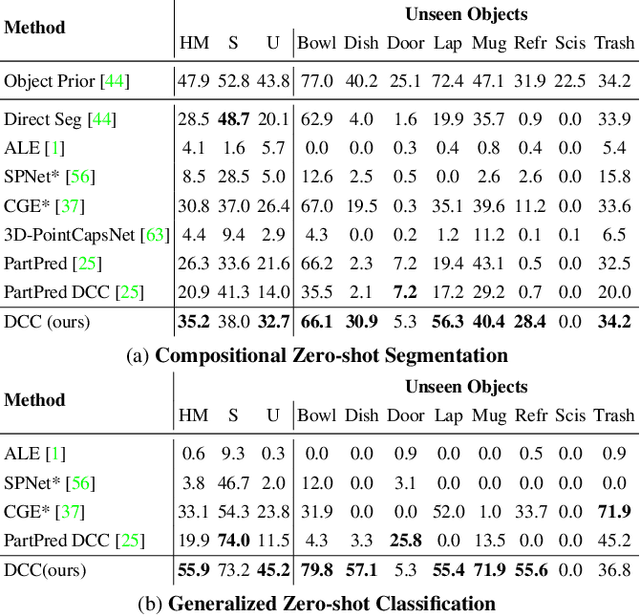
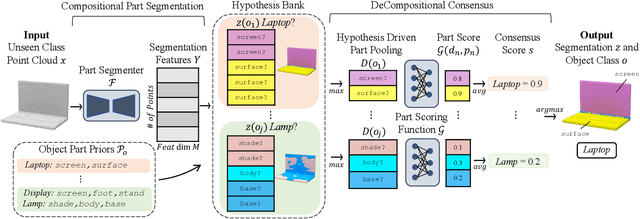
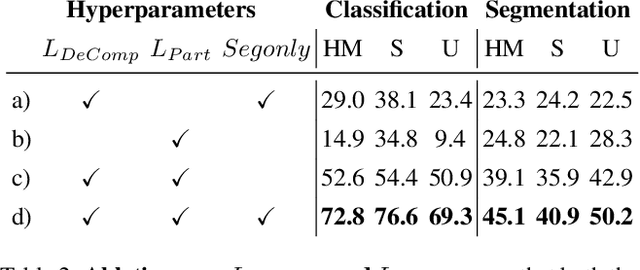
Parts represent a basic unit of geometric and semantic similarity across different objects. We argue that part knowledge should be composable beyond the observed object classes. Towards this, we present 3D Compositional Zero-shot Learning as a problem of part generalization from seen to unseen object classes for semantic segmentation. We provide a structured study through benchmarking the task with the proposed Compositional-PartNet dataset. This dataset is created by processing the original PartNet to maximize part overlap across different objects. The existing point cloud part segmentation methods fail to generalize to unseen object classes in this setting. As a solution, we propose DeCompositional Consensus, which combines a part segmentation network with a part scoring network. The key intuition to our approach is that a segmentation mask over some parts should have a consensus with its part scores when each part is taken apart. The two networks reason over different part combinations defined in a per-object part prior to generate the most suitable segmentation mask. We demonstrate that our method allows compositional zero-shot segmentation and generalized zero-shot classification, and establishes the state of the art on both tasks.
Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-Language Model
Nov 26, 2021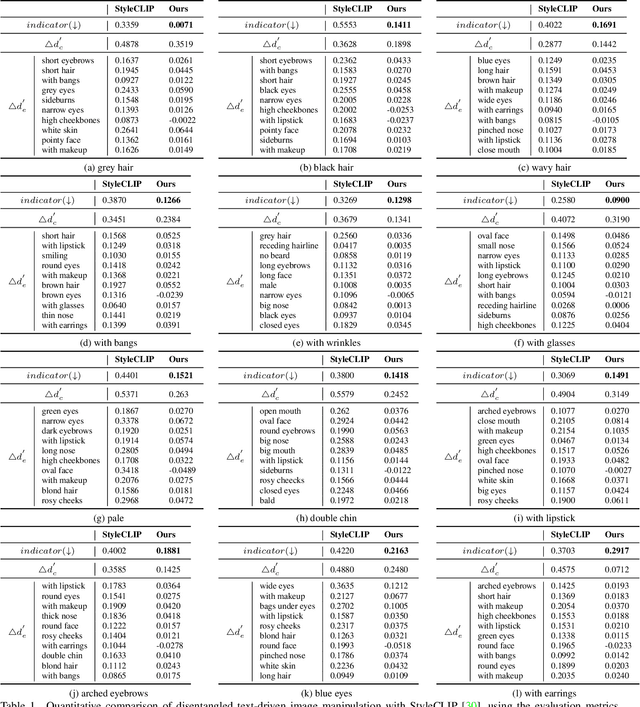
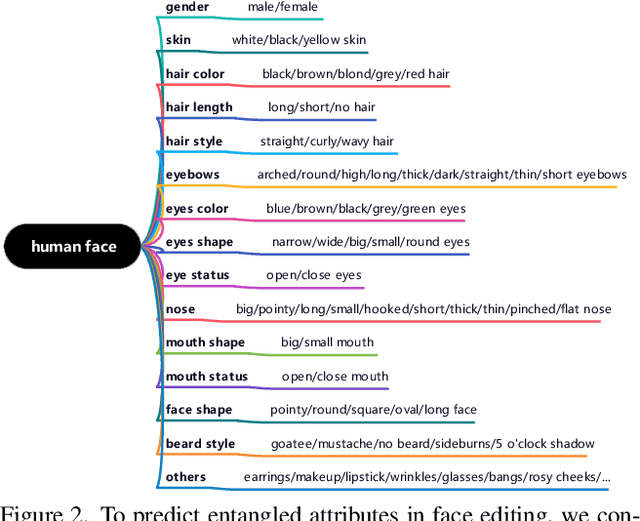
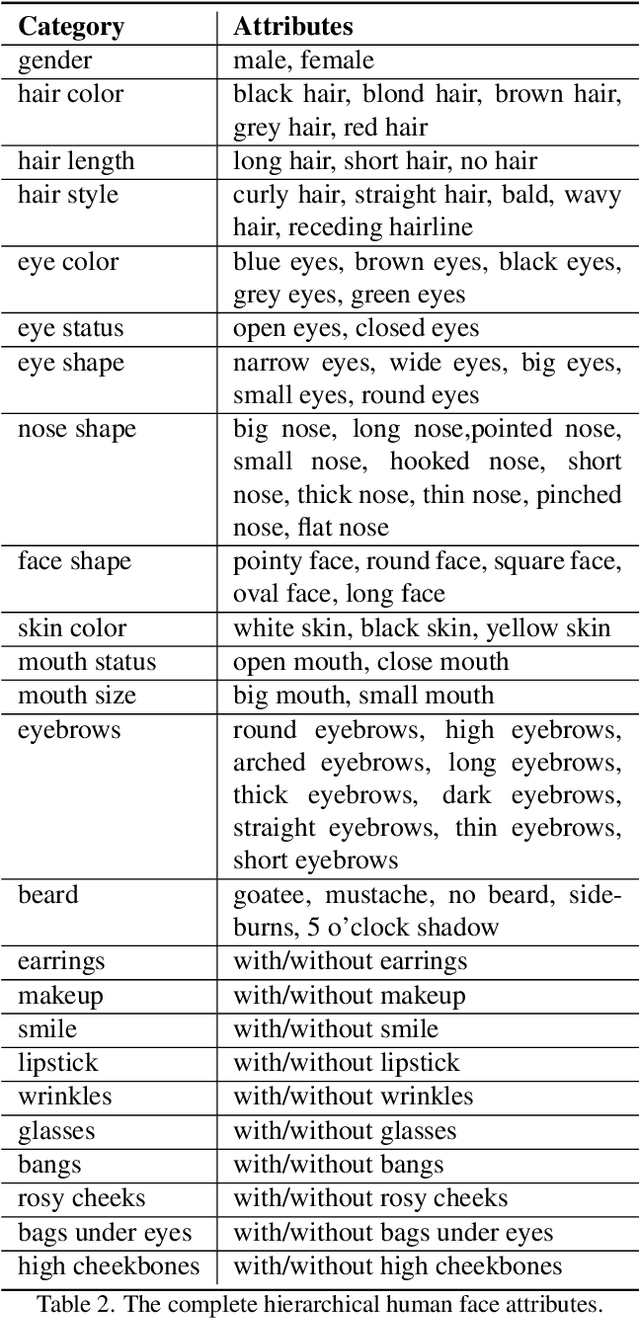

To achieve disentangled image manipulation, previous works depend heavily on manual annotation. Meanwhile, the available manipulations are limited to a pre-defined set the models were trained for. In this paper, we propose a novel framework, i.e., Predict, Prevent, and Evaluate (PPE), for disentangled text-driven image manipulation, which does not need manual annotation and thus is not limited to fixed manipulations. Our method approaches the targets by deeply exploiting the power of the large scale pre-trained vision-language model CLIP. Concretely, we firstly Predict the possibly entangled attributes for a given text command. Then, based on the predicted attributes, we introduce an entanglement loss to Prevent entanglements during training. Finally, we propose a new evaluation metric to Evaluate the disentangled image manipulation. We verify the effectiveness of our method on the challenging face editing task. Extensive experiments show that the proposed PPE framework achieves much better quantitative and qualitative results than the up-to-date StyleCLIP baseline.
MHFormer: Multi-Hypothesis Transformer for 3D Human Pose Estimation
Nov 24, 2021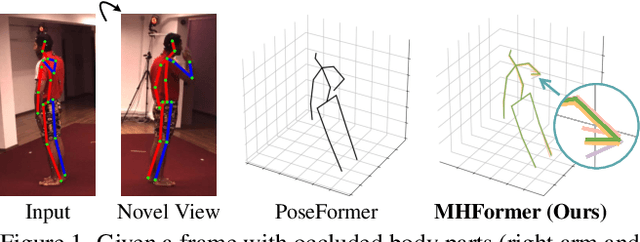
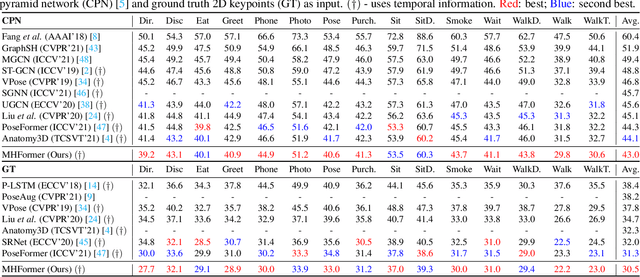
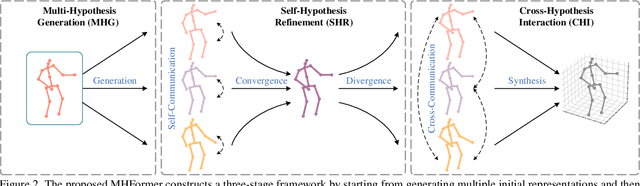

Estimating 3D human poses from monocular videos is a challenging task due to depth ambiguity and self-occlusion. Most existing works attempt to solve both issues by exploiting spatial and temporal relationships. However, those works ignore the fact that it is an inverse problem where multiple feasible solutions (i.e., hypotheses) exist. To relieve this limitation, we propose a Multi-Hypothesis Transformer (MHFormer) that learns spatio-temporal representations of multiple plausible pose hypotheses. In order to effectively model multi-hypothesis dependencies and build strong relationships across hypothesis features, the task is decomposed into three stages: (i) Generate multiple initial hypothesis representations; (ii) Model self-hypothesis communication, merge multiple hypotheses into a single converged representation and then partition it into several diverged hypotheses; (iii) Learn cross-hypothesis communication and aggregate the multi-hypothesis features to synthesize the final 3D pose. Through the above processes, the final representation is enhanced and the synthesized pose is much more accurate. Extensive experiments show that MHFormer achieves state-of-the-art results on two challenging datasets: Human3.6M and MPI-INF-3DHP. Without bells and whistles, its performance surpasses the previous best result by a large margin of 3% on Human3.6M. Code and models are available at https://github.com/Vegetebird/MHFormer.
Global and Local Alignment Networks for Unpaired Image-to-Image Translation
Nov 19, 2021
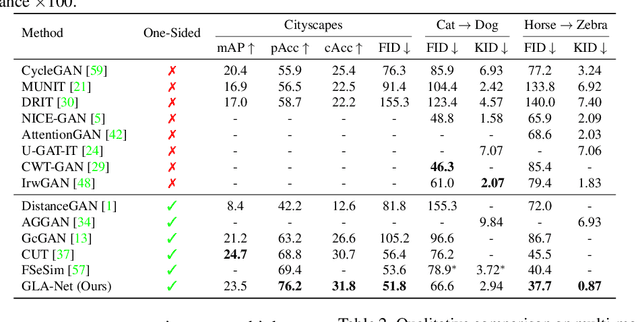
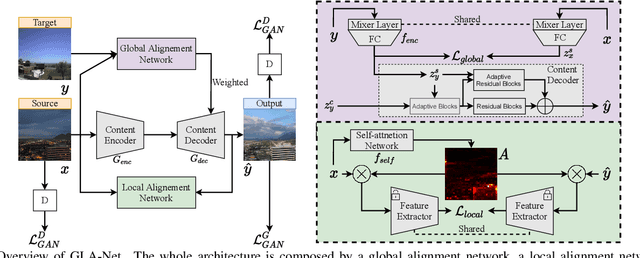
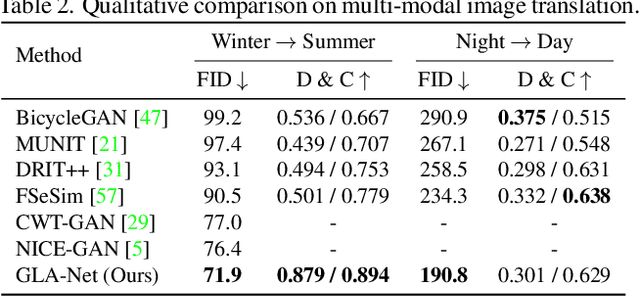
The goal of unpaired image-to-image translation is to produce an output image reflecting the target domain's style while keeping unrelated contents of the input source image unchanged. However, due to the lack of attention to the content change in existing methods, the semantic information from source images suffers from degradation during translation. In the paper, to address this issue, we introduce a novel approach, Global and Local Alignment Networks (GLA-Net). The global alignment network aims to transfer the input image from the source domain to the target domain. To effectively do so, we learn the parameters (mean and standard deviation) of multivariate Gaussian distributions as style features by using an MLP-Mixer based style encoder. To transfer the style more accurately, we employ an adaptive instance normalization layer in the encoder, with the parameters of the target multivariate Gaussian distribution as input. We also adopt regularization and likelihood losses to further reduce the domain gap and produce high-quality outputs. Additionally, we introduce a local alignment network, which employs a pretrained self-supervised model to produce an attention map via a novel local alignment loss, ensuring that the translation network focuses on relevant pixels. Extensive experiments conducted on five public datasets demonstrate that our method effectively generates sharper and more realistic images than existing approaches. Our code is available at https://github.com/ygjwd12345/GLANet.
Mask-guided Spectral-wise Transformer for Efficient Hyperspectral Image Reconstruction
Nov 15, 2021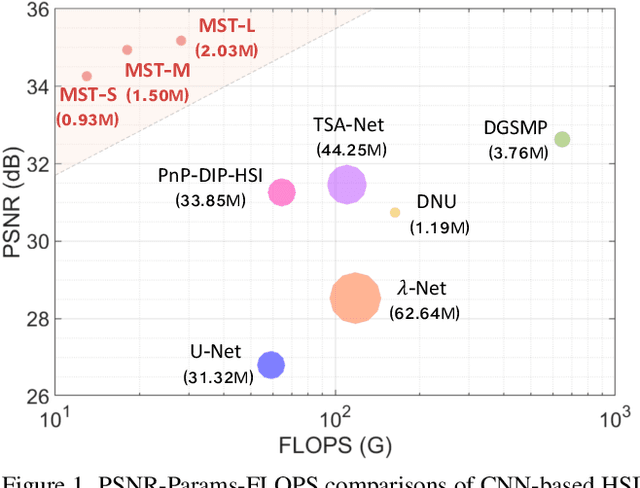
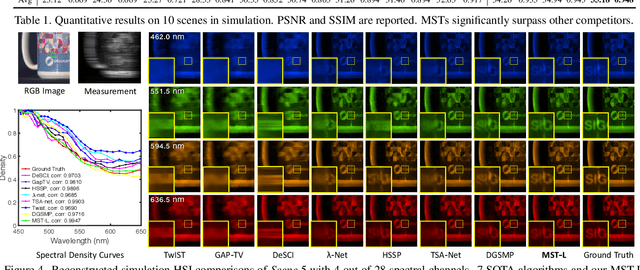
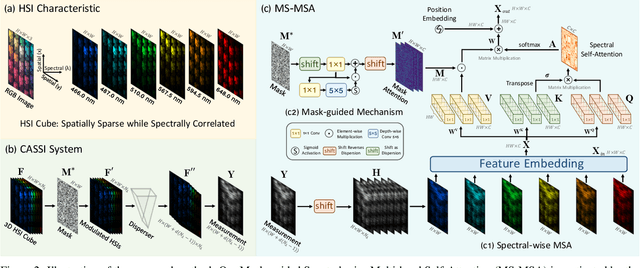
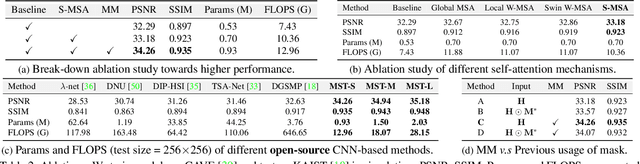
Hyperspectral image (HSI) reconstruction aims to recover the 3D spatial-spectral signal from a 2D measurement in the coded aperture snapshot spectral imaging (CASSI) system. The HSI representations are highly similar and correlated across the spectral dimension. Modeling the inter-spectra interactions is beneficial for HSI reconstruction. However, existing CNN-based methods show limitations in capturing spectral-wise similarity and long-range dependencies. Besides, the HSI information is modulated by a coded aperture (physical mask) in CASSI. Nonetheless, current algorithms have not fully explored the guidance effect of the mask for HSI restoration. In this paper, we propose a novel framework, Mask-guided Spectral-wise Transformer (MST), for HSI reconstruction. Specifically, we present a Spectral-wise Multi-head Self-Attention (S-MSA) that treats each spectral feature as a token and calculates self-attention along the spectral dimension. In addition, we customize a Mask-guided Mechanism (MM) that directs S-MSA to pay attention to spatial regions with high-fidelity spectral representations. Extensive experiments show that our MST significantly outperforms state-of-the-art (SOTA) methods on simulation and real HSI datasets while requiring dramatically cheaper computational and memory costs.
Normalizing Flow as a Flexible Fidelity Objective for Photo-Realistic Super-resolution
Nov 05, 2021
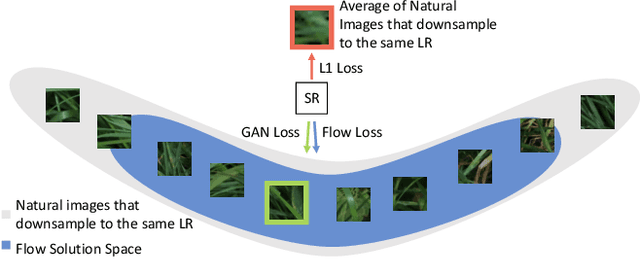
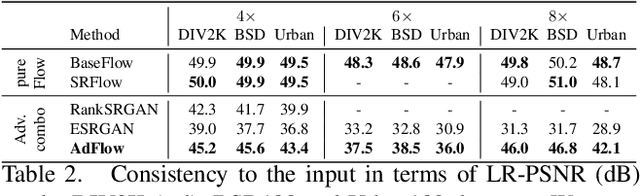
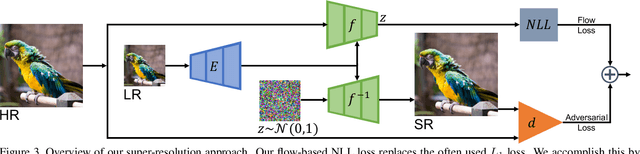
Super-resolution is an ill-posed problem, where a ground-truth high-resolution image represents only one possibility in the space of plausible solutions. Yet, the dominant paradigm is to employ pixel-wise losses, such as L_1, which drive the prediction towards a blurry average. This leads to fundamentally conflicting objectives when combined with adversarial losses, which degrades the final quality. We address this issue by revisiting the L_1 loss and show that it corresponds to a one-layer conditional flow. Inspired by this relation, we explore general flows as a fidelity-based alternative to the L_1 objective. We demonstrate that the flexibility of deeper flows leads to better visual quality and consistency when combined with adversarial losses. We conduct extensive user studies for three datasets and scale factors, where our approach is shown to outperform state-of-the-art methods for photo-realistic super-resolution. Code and trained models will be available at: git.io/AdFlow
Neural Architecture Search for Efficient Uncalibrated Deep Photometric Stereo
Oct 11, 2021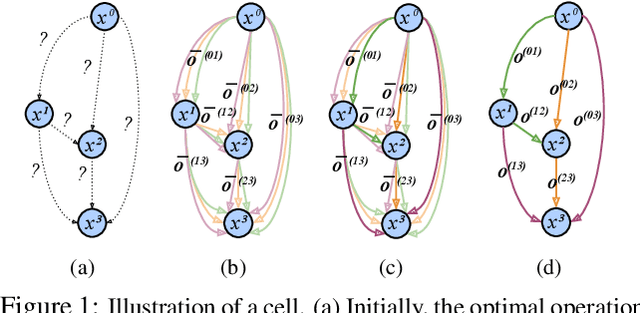

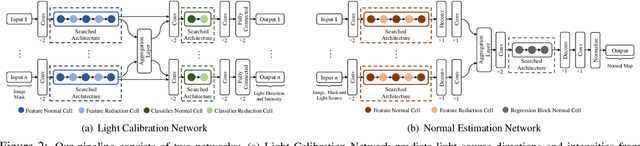

We present an automated machine learning approach for uncalibrated photometric stereo (PS). Our work aims at discovering lightweight and computationally efficient PS neural networks with excellent surface normal accuracy. Unlike previous uncalibrated deep PS networks, which are handcrafted and carefully tuned, we leverage differentiable neural architecture search (NAS) strategy to find uncalibrated PS architecture automatically. We begin by defining a discrete search space for a light calibration network and a normal estimation network, respectively. We then perform a continuous relaxation of this search space and present a gradient-based optimization strategy to find an efficient light calibration and normal estimation network. Directly applying the NAS methodology to uncalibrated PS is not straightforward as certain task-specific constraints must be satisfied, which we impose explicitly. Moreover, we search for and train the two networks separately to account for the Generalized Bas-Relief (GBR) ambiguity. Extensive experiments on the DiLiGenT dataset show that the automatically searched neural architectures performance compares favorably with the state-of-the-art uncalibrated PS methods while having a lower memory footprint.