 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustifying the Multi-Scale Representation of Neural Radiance Fields
Oct 09, 2022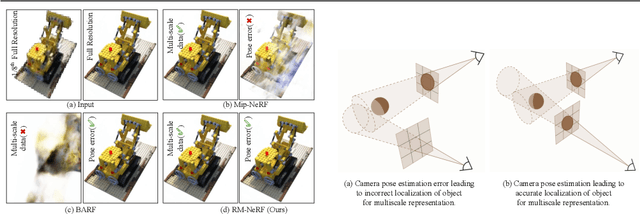
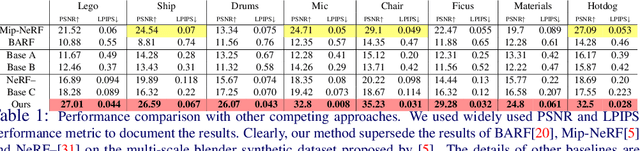
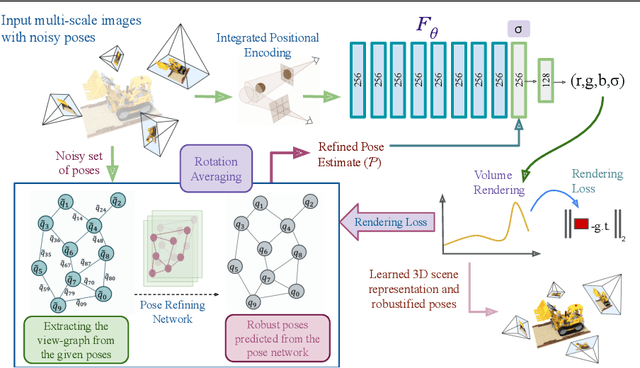
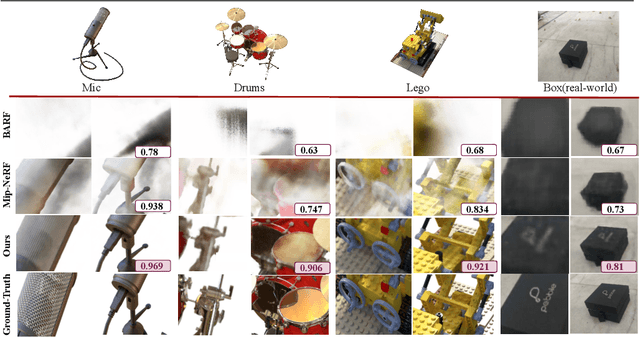
Neural Radiance Fields (NeRF) recently emerged as a new paradigm for object representation from multi-view (MV) images. Yet, it cannot handle multi-scale (MS) images and camera pose estimation errors, which generally is the case with multi-view images captured from a day-to-day commodity camera. Although recently proposed Mip-NeRF could handle multi-scale imaging problems with NeRF, it cannot handle camera pose estimation error. On the other hand, the newly proposed BARF can solve the camera pose problem with NeRF but fails if the images are multi-scale in nature. This paper presents a robust multi-scale neural radiance fields representation approach to simultaneously overcome both real-world imaging issues. Our method handles multi-scale imaging effects and camera-pose estimation problems with NeRF-inspired approaches by leveraging the fundamentals of scene rigidity. To reduce unpleasant aliasing artifacts due to multi-scale images in the ray space, we leverage Mip-NeRF multi-scale representation. For joint estimation of robust camera pose, we propose graph-neural network-based multiple motion averaging in the neural volume rendering framework. We demonstrate, with examples, that for an accurate neural representation of an object from day-to-day acquired multi-view images, it is crucial to have precise camera-pose estimates. Without considering robustness measures in the camera pose estimation, modeling for multi-scale aliasing artifacts via conical frustum can be counterproductive. We present extensive experiments on the benchmark datasets to demonstrate that our approach provides better results than the recent NeRF-inspired approaches for such realistic settings.
Exploiting Instance-based Mixed Sampling via Auxiliary Source Domain Supervision for Domain-adaptive Action Detection
Oct 06, 2022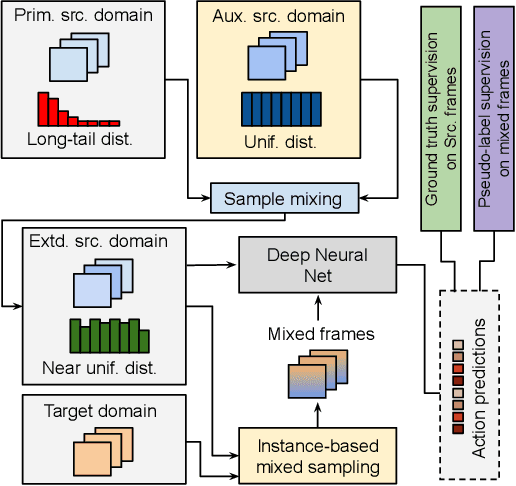
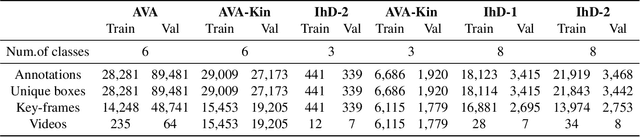
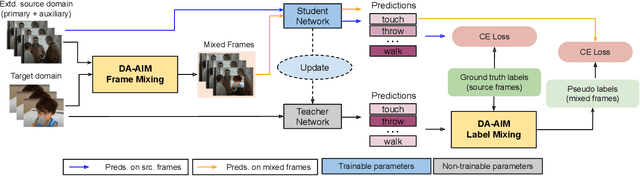
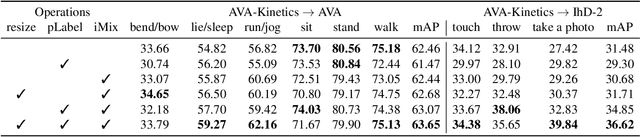
We propose a novel domain adaptive action detection approach and a new adaptation protocol that leverages the recent advancements in image-level unsupervised domain adaptation (UDA) techniques and handle vagaries of instance-level video data. Self-training combined with cross-domain mixed sampling has shown remarkable performance gain in semantic segmentation in UDA (unsupervised domain adaptation) context. Motivated by this fact, we propose an approach for human action detection in videos that transfers knowledge from the source domain (annotated dataset) to the target domain (unannotated dataset) using mixed sampling and pseudo-label-based selftraining. The existing UDA techniques follow a ClassMix algorithm for semantic segmentation. However, simply adopting ClassMix for action detection does not work, mainly because these are two entirely different problems, i.e., pixel-label classification vs. instance-label detection. To tackle this, we propose a novel action instance mixed sampling technique that combines information across domains based on action instances instead of action classes. Moreover, we propose a new UDA training protocol that addresses the long-tail sample distribution and domain shift problem by using supervision from an auxiliary source domain (ASD). For the ASD, we propose a new action detection dataset with dense frame-level annotations. We name our proposed framework as domain-adaptive action instance mixing (DA-AIM). We demonstrate that DA-AIM consistently outperforms prior works on challenging domain adaptation benchmarks. The source code is available at https://github.com/wwwfan628/DA-AIM.
Basic Binary Convolution Unit for Binarized Image Restoration Network
Oct 02, 2022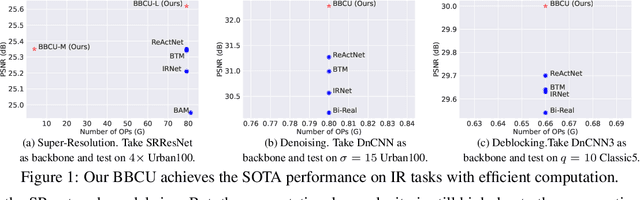
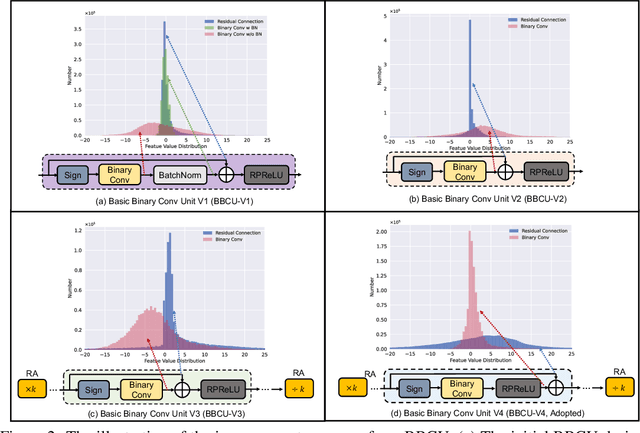
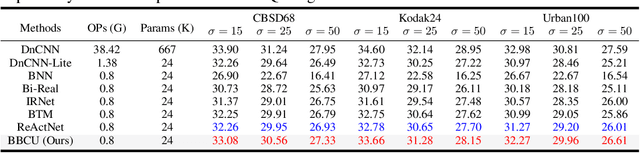
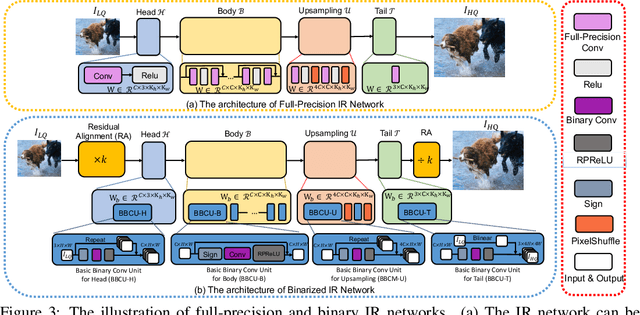
Lighter and faster image restoration (IR) models are crucial for the deployment on resource-limited devices. Binary neural network (BNN), one of the most promising model compression methods, can dramatically reduce the computations and parameters of full-precision convolutional neural networks (CNN). However, there are different properties between BNN and full-precision CNN, and we can hardly use the experience of designing CNN to develop BNN. In this study, we reconsider components in binary convolution, such as residual connection, BatchNorm, activation function, and structure, for IR tasks. We conduct systematic analyses to explain each component's role in binary convolution and discuss the pitfalls. Specifically, we find that residual connection can reduce the information loss caused by binarization; BatchNorm can solve the value range gap between residual connection and binary convolution; The position of the activation function dramatically affects the performance of BNN. Based on our findings and analyses, we design a simple yet efficient basic binary convolution unit (BBCU). Furthermore, we divide IR networks into four parts and specially design variants of BBCU for each part to explore the benefit of binarizing these parts. We conduct experiments on different IR tasks, and our BBCU significantly outperforms other BNNs and lightweight models, which shows that BBCU can serve as a basic unit for binarized IR networks. All codes and models will be released.
TT-NF: Tensor Train Neural Fields
Sep 30, 2022
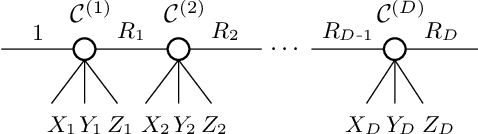
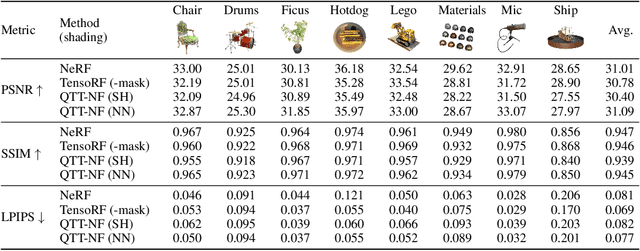
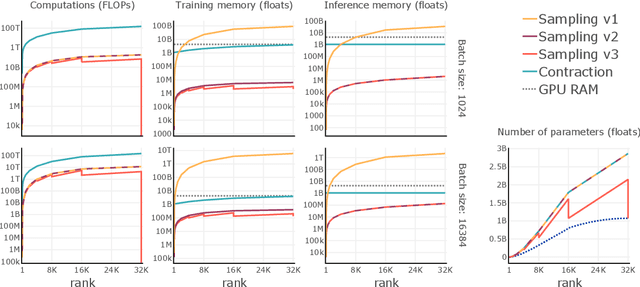
Learning neural fields has been an active topic in deep learning research, focusing, among other issues, on finding more compact and easy-to-fit representations. In this paper, we introduce a novel low-rank representation termed Tensor Train Neural Fields (TT-NF) for learning neural fields on dense regular grids and efficient methods for sampling from them. Our representation is a TT parameterization of the neural field, trained with backpropagation to minimize a non-convex objective. We analyze the effect of low-rank compression on the downstream task quality metrics in two settings. First, we demonstrate the efficiency of our method in a sandbox task of tensor denoising, which admits comparison with SVD-based schemes designed to minimize reconstruction error. Furthermore, we apply the proposed approach to Neural Radiance Fields, where the low-rank structure of the field corresponding to the best quality can be discovered only through learning.
I2DFormer: Learning Image to Document Attention for Zero-Shot Image Classification
Sep 21, 2022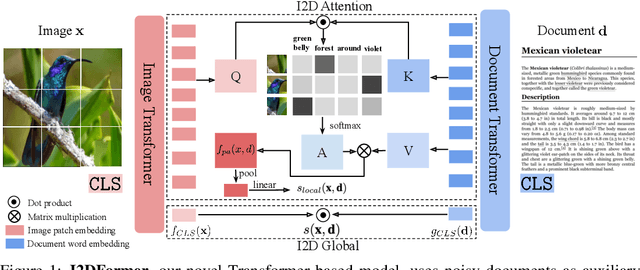
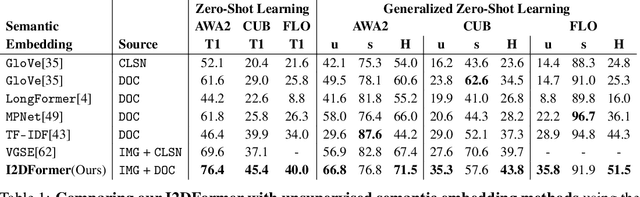
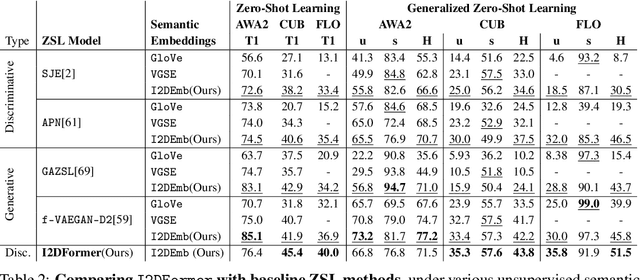

Despite the tremendous progress in zero-shot learning(ZSL), the majority of existing methods still rely on human-annotated attributes, which are difficult to annotate and scale. An unsupervised alternative is to represent each class using the word embedding associated with its semantic class name. However, word embeddings extracted from pre-trained language models do not necessarily capture visual similarities, resulting in poor zero-shot performance. In this work, we argue that online textual documents, e.g., Wikipedia, contain rich visual descriptions about object classes, therefore can be used as powerful unsupervised side information for ZSL. To this end, we propose I2DFormer, a novel transformer-based ZSL framework that jointly learns to encode images and documents by aligning both modalities in a shared embedding space. In order to distill discriminative visual words from noisy documents, we introduce a new cross-modal attention module that learns fine-grained interactions between image patches and document words. Consequently, our I2DFormer not only learns highly discriminative document embeddings that capture visual similarities but also gains the ability to localize visually relevant words in image regions. Quantitatively, we demonstrate that our I2DFormer significantly outperforms previous unsupervised semantic embeddings under both zero-shot and generalized zero-shot learning settings on three public datasets. Qualitatively, we show that our method leads to highly interpretable results where document words can be grounded in the image regions.
Spatio-Temporal Action Detection Under Large Motion
Sep 06, 2022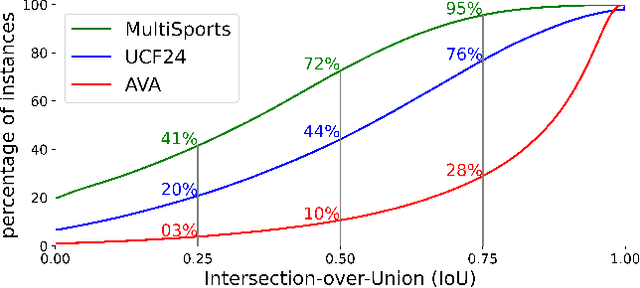
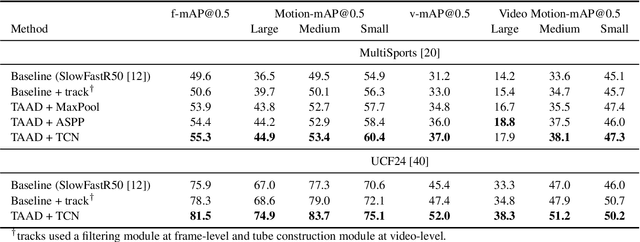

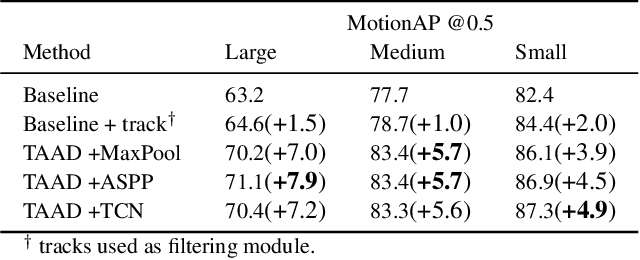
Current methods for spatiotemporal action tube detection often extend a bounding box proposal at a given keyframe into a 3D temporal cuboid and pool features from nearby frames. However, such pooling fails to accumulate meaningful spatiotemporal features if the position or shape of the actor shows large 2D motion and variability through the frames, due to large camera motion, large actor shape deformation, fast actor action and so on. In this work, we aim to study the performance of cuboid-aware feature aggregation in action detection under large action. Further, we propose to enhance actor feature representation under large motion by tracking actors and performing temporal feature aggregation along the respective tracks. We define the actor motion with intersection-over-union (IoU) between the boxes of action tubes/tracks at various fixed time scales. The action having a large motion would result in lower IoU over time, and slower actions would maintain higher IoU. We find that track-aware feature aggregation consistently achieves a large improvement in action detection performance, especially for actions under large motion compared to the cuboid-aware baseline. As a result, we also report state-of-the-art on the large-scale MultiSports dataset.
Practical Real Video Denoising with Realistic Degradation Model
Aug 25, 2022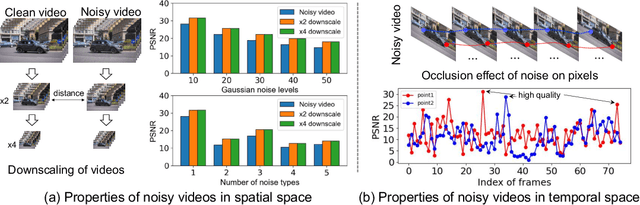
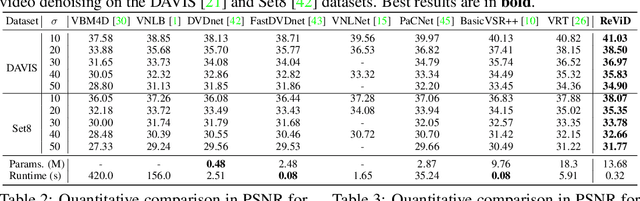
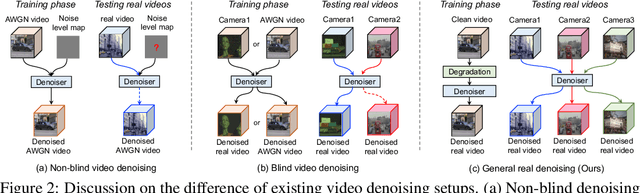
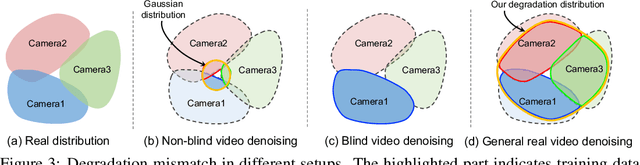
Existing video denoising methods typically assume noisy videos are degraded from clean videos by adding Gaussian noise. However, deep models trained on such a degradation assumption will inevitably give rise to poor performance for real videos due to degradation mismatch. Although some studies attempt to train deep models on noisy and noise-free video pairs captured by cameras, such models can only work well for specific cameras and do not generalize well for other videos. In this paper, we propose to lift this limitation and focus on the problem of general real video denoising with the aim to generalize well on unseen real-world videos. We tackle this problem by firstly investigating the common behaviors of video noises and observing two important characteristics: 1) downscaling helps to reduce the noise level in spatial space and 2) the information from the adjacent frames help to remove the noise of current frame in temporal space. Motivated by these two observations, we propose a multi-scale recurrent architecture by making full use of the above two characteristics. Secondly, we propose a synthetic real noise degradation model by randomly shuffling different noise types to train the denoising model. With a synthesized and enriched degradation space, our degradation model can help to bridge the distribution gap between training data and real-world data. Extensive experiments demonstrate that our proposed method achieves the state-of-the-art performance and better generalization ability than existing methods on both synthetic Gaussian denoising and practical real video denoising.
ManiFlow: Implicitly Representing Manifolds with Normalizing Flows
Aug 18, 2022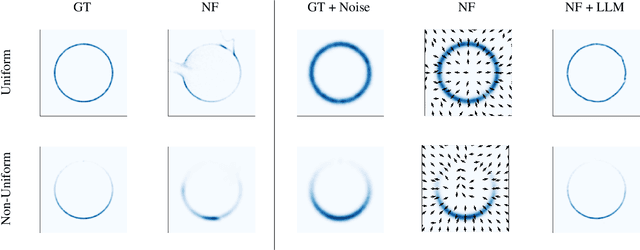
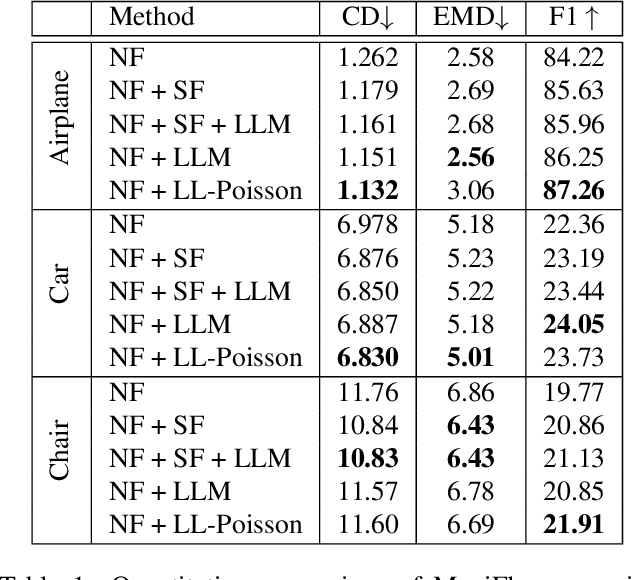

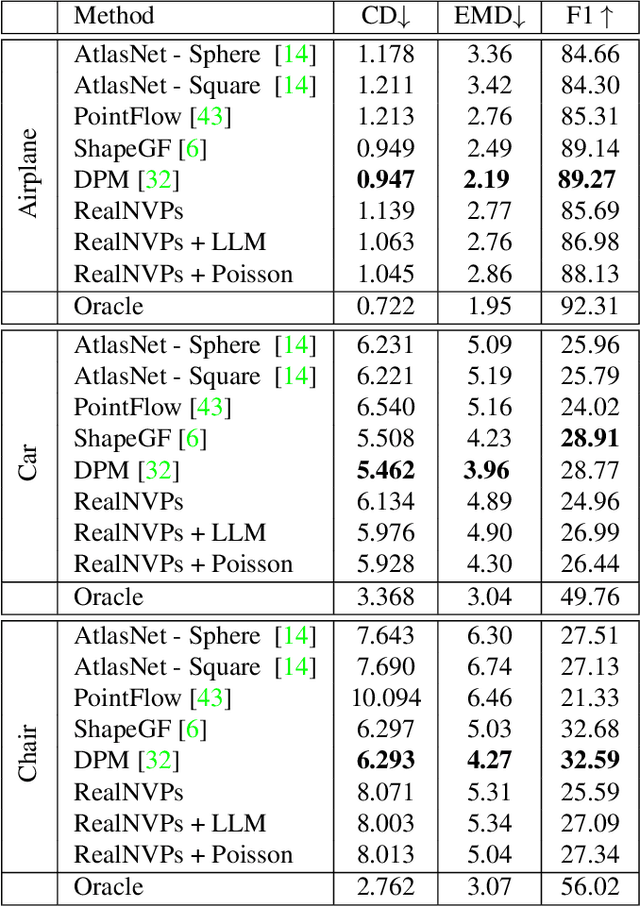
Normalizing Flows (NFs) are flexible explicit generative models that have been shown to accurately model complex real-world data distributions. However, their invertibility constraint imposes limitations on data distributions that reside on lower dimensional manifolds embedded in higher dimensional space. Practically, this shortcoming is often bypassed by adding noise to the data which impacts the quality of the generated samples. In contrast to prior work, we approach this problem by generating samples from the original data distribution given full knowledge about the perturbed distribution and the noise model. To this end, we establish that NFs trained on perturbed data implicitly represent the manifold in regions of maximum likelihood. Then, we propose an optimization objective that recovers the most likely point on the manifold given a sample from the perturbed distribution. Finally, we focus on 3D point clouds for which we utilize the explicit nature of NFs, i.e. surface normals extracted from the gradient of the log-likelihood and the log-likelihood itself, to apply Poisson surface reconstruction to refine generated point sets.
AVisT: A Benchmark for Visual Object Tracking in Adverse Visibility
Aug 14, 2022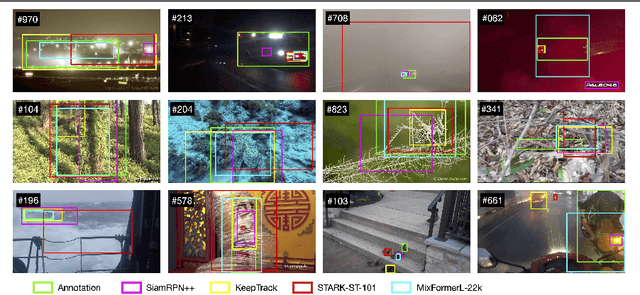

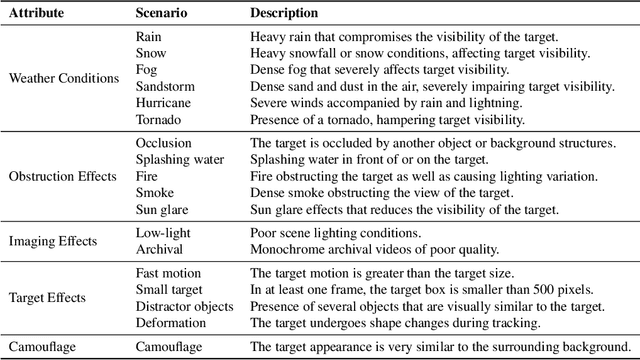
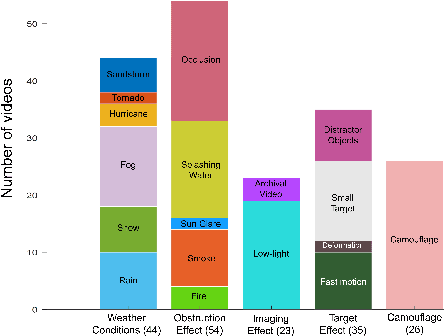
One of the key factors behind the recent success in visual tracking is the availability of dedicated benchmarks. While being greatly benefiting to the tracking research, existing benchmarks do not pose the same difficulty as before with recent trackers achieving higher performance mainly due to (i) the introduction of more sophisticated transformers-based methods and (ii) the lack of diverse scenarios with adverse visibility such as, severe weather conditions, camouflage and imaging effects. We introduce AVisT, a dedicated benchmark for visual tracking in diverse scenarios with adverse visibility. AVisT comprises 120 challenging sequences with 80k annotated frames, spanning 18 diverse scenarios broadly grouped into five attributes with 42 object categories. The key contribution of AVisT is diverse and challenging scenarios covering severe weather conditions such as, dense fog, heavy rain and sandstorm; obstruction effects including, fire, sun glare and splashing water; adverse imaging effects such as, low-light; target effects including, small targets and distractor objects along with camouflage. We further benchmark 17 popular and recent trackers on AVisT with detailed analysis of their tracking performance across attributes, demonstrating a big room for improvement in performance. We believe that AVisT can greatly benefit the tracking community by complementing the existing benchmarks, in developing new creative tracking solutions in order to continue pushing the boundaries of the state-of-the-art. Our dataset along with the complete tracking performance evaluation is available at: https://github.com/visionml/pytracking
Reference-based Image Super-Resolution with Deformable Attention Transformer
Aug 04, 2022
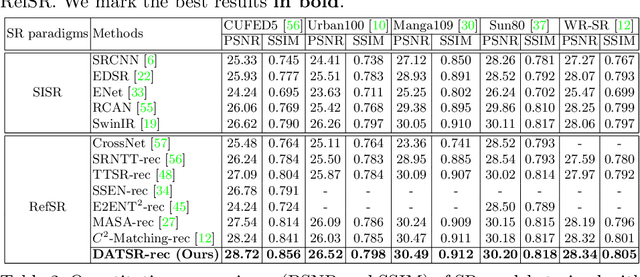
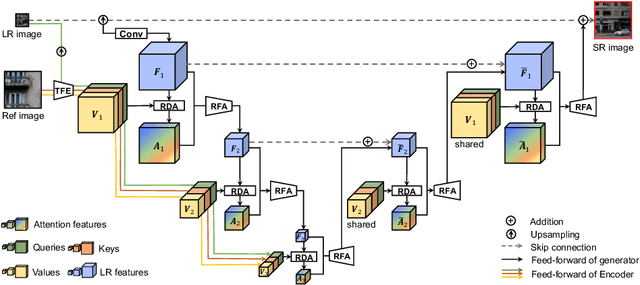
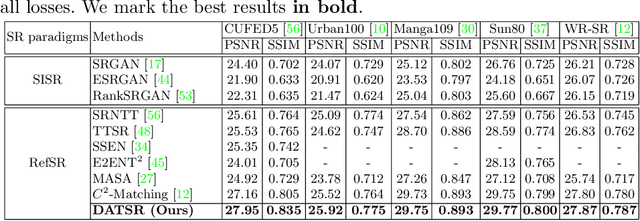
Reference-based image super-resolution (RefSR) aims to exploit auxiliary reference (Ref) images to super-resolve low-resolution (LR) images. Recently, RefSR has been attracting great attention as it provides an alternative way to surpass single image SR. However, addressing the RefSR problem has two critical challenges: (i) It is difficult to match the correspondence between LR and Ref images when they are significantly different; (ii) How to transfer the relevant texture from Ref images to compensate the details for LR images is very challenging. To address these issues of RefSR, this paper proposes a deformable attention Transformer, namely DATSR, with multiple scales, each of which consists of a texture feature encoder (TFE) module, a reference-based deformable attention (RDA) module and a residual feature aggregation (RFA) module. Specifically, TFE first extracts image transformation (e.g., brightness) insensitive features for LR and Ref images, RDA then can exploit multiple relevant textures to compensate more information for LR features, and RFA lastly aggregates LR features and relevant textures to get a more visually pleasant result. Extensive experiments demonstrate that our DATSR achieves state-of-the-art performance on benchmark datasets quantitatively and qualitatively.