 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Range-View LiDAR Segmentation in Adverse Weather
Jun 10, 2025



LiDAR segmentation has emerged as an important task to enrich multimedia experiences and analysis. Range-view-based methods have gained popularity due to their high computational efficiency and compatibility with real-time deployment. However, their generalized performance under adverse weather conditions remains underexplored, limiting their reliability in real-world environments. In this work, we identify and analyze the unique challenges that affect the generalization of range-view LiDAR segmentation in severe weather. To address these challenges, we propose a modular and lightweight framework that enhances robustness without altering the core architecture of existing models. Our method reformulates the initial stem block of standard range-view networks into two branches to process geometric attributes and reflectance intensity separately. Specifically, a Geometric Abnormality Suppression (GAS) module reduces the influence of weather-induced spatial noise, and a Reflectance Distortion Calibration (RDC) module corrects reflectance distortions through memory-guided adaptive instance normalization. The processed features are then fused and passed to the original segmentation pipeline. Extensive experiments on different benchmarks and baseline models demonstrate that our approach significantly improves generalization to adverse weather with minimal inference overhead, offering a practical and effective solution for real-world LiDAR segmentation.
Unifying Language Agent Algorithms with Graph-based Orchestration Engine for Reproducible Agent Research
May 30, 2025



Language agents powered by large language models (LLMs) have demonstrated remarkable capabilities in understanding, reasoning, and executing complex tasks. However, developing robust agents presents significant challenges: substantial engineering overhead, lack of standardized components, and insufficient evaluation frameworks for fair comparison. We introduce Agent Graph-based Orchestration for Reasoning and Assessment (AGORA), a flexible and extensible framework that addresses these challenges through three key contributions: (1) a modular architecture with a graph-based workflow engine, efficient memory management, and clean component abstraction; (2) a comprehensive suite of reusable agent algorithms implementing state-of-the-art reasoning approaches; and (3) a rigorous evaluation framework enabling systematic comparison across multiple dimensions. Through extensive experiments on mathematical reasoning and multimodal tasks, we evaluate various agent algorithms across different LLMs, revealing important insights about their relative strengths and applicability. Our results demonstrate that while sophisticated reasoning approaches can enhance agent capabilities, simpler methods like Chain-of-Thought often exhibit robust performance with significantly lower computational overhead. AGORA not only simplifies language agent development but also establishes a foundation for reproducible agent research through standardized evaluation protocols.
Step-Wise Formal Verification for LLM-Based Mathematical Problem Solving
May 27, 2025Large Language Models (LLMs) have demonstrated formidable capabilities in solving mathematical problems, yet they may still commit logical reasoning and computational errors during the problem-solving process. Thus, this paper proposes a framework, MATH-VF, which includes a Formalizer and a Critic, for formally verifying the correctness of the solutions generated by large language models. Our framework first utilizes a Formalizer which employs an LLM to translate a natural language solution into a formal context. Afterward, our Critic (which integrates various external tools such as a Computer Algebra System and an SMT solver) evaluates the correctness of each statement within the formal context, and when a statement is incorrect, our Critic provides corrective feedback. We empirically investigate the effectiveness of MATH-VF in two scenarios: 1) Verification: MATH-VF is utilized to determine the correctness of a solution to a given problem. 2) Refinement: When MATH-VF identifies errors in the solution generated by an LLM-based solution generator for a given problem, it submits the corrective suggestions proposed by the Critic to the solution generator to regenerate the solution. We evaluate our framework on widely used mathematical benchmarks: MATH500 and ProcessBench, demonstrating the superiority of our approach over existing approaches.
Causally Fair Node Classification on Non-IID Graph Data
May 03, 2025Fair machine learning seeks to identify and mitigate biases in predictions against unfavorable populations characterized by demographic attributes, such as race and gender. Recently, a few works have extended fairness to graph data, such as social networks, but most of them neglect the causal relationships among data instances. This paper addresses the prevalent challenge in fairness-aware ML algorithms, which typically assume Independent and Identically Distributed (IID) data. We tackle the overlooked domain of non-IID, graph-based settings where data instances are interconnected, influencing the outcomes of fairness interventions. We base our research on the Network Structural Causal Model (NSCM) framework and posit two main assumptions: Decomposability and Graph Independence, which enable the computation of interventional distributions in non-IID settings using the $do$-calculus. Based on that, we develop the Message Passing Variational Autoencoder for Causal Inference (MPVA) to compute interventional distributions and facilitate causally fair node classification through estimated interventional distributions. Empirical evaluations on semi-synthetic and real-world datasets demonstrate that MPVA outperforms conventional methods by effectively approximating interventional distributions and mitigating bias. The implications of our findings underscore the potential of causality-based fairness in complex ML applications, setting the stage for further research into relaxing the initial assumptions to enhance model fairness.
Antidote: A Unified Framework for Mitigating LVLM Hallucinations in Counterfactual Presupposition and Object Perception
Apr 29, 2025
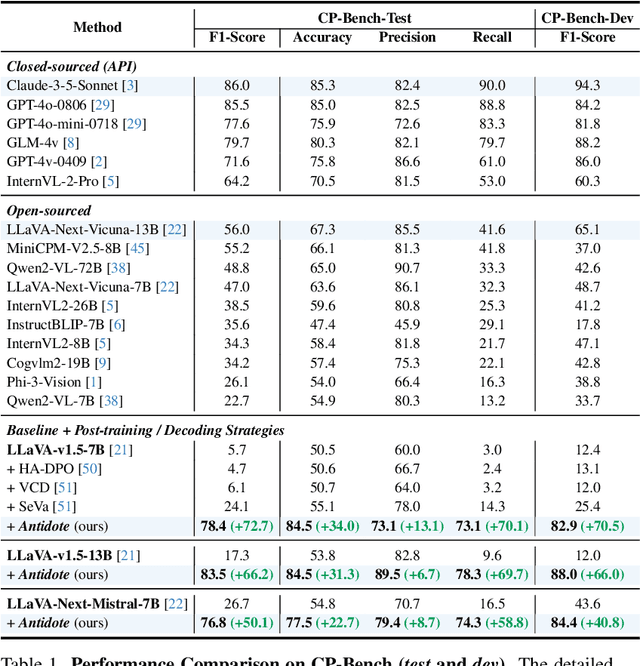

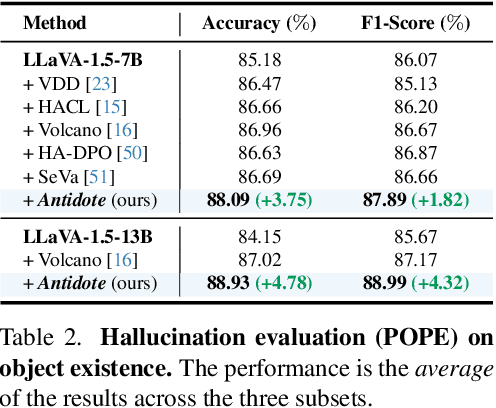
Large Vision-Language Models (LVLMs) have achieved impressive results across various cross-modal tasks. However, hallucinations, i.e., the models generating counterfactual responses, remain a challenge. Though recent studies have attempted to alleviate object perception hallucinations, they focus on the models' response generation, and overlooking the task question itself. This paper discusses the vulnerability of LVLMs in solving counterfactual presupposition questions (CPQs), where the models are prone to accept the presuppositions of counterfactual objects and produce severe hallucinatory responses. To this end, we introduce "Antidote", a unified, synthetic data-driven post-training framework for mitigating both types of hallucination above. It leverages synthetic data to incorporate factual priors into questions to achieve self-correction, and decouple the mitigation process into a preference optimization problem. Furthermore, we construct "CP-Bench", a novel benchmark to evaluate LVLMs' ability to correctly handle CPQs and produce factual responses. Applied to the LLaVA series, Antidote can simultaneously enhance performance on CP-Bench by over 50%, POPE by 1.8-3.3%, and CHAIR & SHR by 30-50%, all without relying on external supervision from stronger LVLMs or human feedback and introducing noticeable catastrophic forgetting issues.
EvMic: Event-based Non-contact sound recovery from effective spatial-temporal modeling
Apr 03, 2025When sound waves hit an object, they induce vibrations that produce high-frequency and subtle visual changes, which can be used for recovering the sound. Early studies always encounter trade-offs related to sampling rate, bandwidth, field of view, and the simplicity of the optical path. Recent advances in event camera hardware show good potential for its application in visual sound recovery, because of its superior ability in capturing high-frequency signals. However, existing event-based vibration recovery methods are still sub-optimal for sound recovery. In this work, we propose a novel pipeline for non-contact sound recovery, fully utilizing spatial-temporal information from the event stream. We first generate a large training set using a novel simulation pipeline. Then we designed a network that leverages the sparsity of events to capture spatial information and uses Mamba to model long-term temporal information. Lastly, we train a spatial aggregation block to aggregate information from different locations to further improve signal quality. To capture event signals caused by sound waves, we also designed an imaging system using a laser matrix to enhance the gradient and collected multiple data sequences for testing. Experimental results on synthetic and real-world data demonstrate the effectiveness of our method.
FEASE: Shallow AutoEncoding Recommender with Cold Start Handling via Side Features
Apr 03, 2025User and item cold starts present significant challenges in industrial applications of recommendation systems. Supplementing user-item interaction data with metadata is a common solution-but often at the cost of introducing additional biases. In this work, we introduce an augmented EASE model, i.e. FEASE, that seamlessly integrates both user and item side information to address these cold start issues. Our straightforward, autoencoder-based method produces a closed-form solution that leverages rich content signals for cold items while refining user representations in data-sparse environments. Importantly, our method strikes a balance by effectively recommending cold start items and handling cold start users without incurring extra bias, and it maintains strong performance in warm settings. Experimental results demonstrate improved recommendation accuracy and robustness compared to previous collaborative filtering approaches. Moreover, our model serves as a strong baseline for future comparative studies.
Towards Interpretable Counterfactual Generation via Multimodal Autoregression
Mar 29, 2025Counterfactual medical image generation enables clinicians to explore clinical hypotheses, such as predicting disease progression, facilitating their decision-making. While existing methods can generate visually plausible images from disease progression prompts, they produce silent predictions that lack interpretation to verify how the generation reflects the hypothesized progression -- a critical gap for medical applications that require traceable reasoning. In this paper, we propose Interpretable Counterfactual Generation (ICG), a novel task requiring the joint generation of counterfactual images that reflect the clinical hypothesis and interpretation texts that outline the visual changes induced by the hypothesis. To enable ICG, we present ICG-CXR, the first dataset pairing longitudinal medical images with hypothetical progression prompts and textual interpretations. We further introduce ProgEmu, an autoregressive model that unifies the generation of counterfactual images and textual interpretations. We demonstrate the superiority of ProgEmu in generating progression-aligned counterfactuals and interpretations, showing significant potential in enhancing clinical decision support and medical education. Project page: https://progemu.github.io.
HyperMAN: Hypergraph-enhanced Meta-learning Adaptive Network for Next POI Recommendation
Mar 27, 2025Next Point-of-Interest (POI) recommendation aims to predict users' next locations by leveraging historical check-in sequences. Although existing methods have shown promising results, they often struggle to capture complex high-order relationships and effectively adapt to diverse user behaviors, particularly when addressing the cold-start issue. To address these challenges, we propose Hypergraph-enhanced Meta-learning Adaptive Network (HyperMAN), a novel framework that integrates heterogeneous hypergraph modeling with a difficulty-aware meta-learning mechanism for next POI recommendation. Specifically, three types of heterogeneous hyperedges are designed to capture high-order relationships: user visit behaviors at specific times (Temporal behavioral hyperedge), spatial correlations among POIs (spatial functional hyperedge), and user long-term preferences (user preference hyperedge). Furthermore, a diversity-aware meta-learning mechanism is introduced to dynamically adjust learning strategies, considering users behavioral diversity. Extensive experiments on real-world datasets demonstrate that HyperMAN achieves superior performance, effectively addressing cold start challenges and significantly enhancing recommendation accuracy.
GyralNet Subnetwork Partitioning via Differentiable Spectral Modularity Optimization
Mar 25, 2025



Understanding the structural and functional organization of the human brain requires a detailed examination of cortical folding patterns, among which the three-hinge gyrus (3HG) has been identified as a key structural landmark. GyralNet, a network representation of cortical folding, models 3HGs as nodes and gyral crests as edges, highlighting their role as critical hubs in cortico-cortical connectivity. However, existing methods for analyzing 3HGs face significant challenges, including the sub-voxel scale of 3HGs at typical neuroimaging resolutions, the computational complexity of establishing cross-subject correspondences, and the oversimplification of treating 3HGs as independent nodes without considering their community-level relationships. To address these limitations, we propose a fully differentiable subnetwork partitioning framework that employs a spectral modularity maximization optimization strategy to modularize the organization of 3HGs within GyralNet. By incorporating topological structural similarity and DTI-derived connectivity patterns as attribute features, our approach provides a biologically meaningful representation of cortical organization. Extensive experiments on the Human Connectome Project (HCP) dataset demonstrate that our method effectively partitions GyralNet at the individual level while preserving the community-level consistency of 3HGs across subjects, offering a robust foundation for understanding brain connectivity.