 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Language Agent Algorithms with Graph-based Orchestration Engine for Reproducible Agent Research
May 30, 2025



Language agents powered by large language models (LLMs) have demonstrated remarkable capabilities in understanding, reasoning, and executing complex tasks. However, developing robust agents presents significant challenges: substantial engineering overhead, lack of standardized components, and insufficient evaluation frameworks for fair comparison. We introduce Agent Graph-based Orchestration for Reasoning and Assessment (AGORA), a flexible and extensible framework that addresses these challenges through three key contributions: (1) a modular architecture with a graph-based workflow engine, efficient memory management, and clean component abstraction; (2) a comprehensive suite of reusable agent algorithms implementing state-of-the-art reasoning approaches; and (3) a rigorous evaluation framework enabling systematic comparison across multiple dimensions. Through extensive experiments on mathematical reasoning and multimodal tasks, we evaluate various agent algorithms across different LLMs, revealing important insights about their relative strengths and applicability. Our results demonstrate that while sophisticated reasoning approaches can enhance agent capabilities, simpler methods like Chain-of-Thought often exhibit robust performance with significantly lower computational overhead. AGORA not only simplifies language agent development but also establishes a foundation for reproducible agent research through standardized evaluation protocols.
OmChat: A Recipe to Train Multimodal Language Models with Strong Long Context and Video Understanding
Jul 06, 2024



We introduce OmChat, a model designed to excel in handling long contexts and video understanding tasks. OmChat's new architecture standardizes how different visual inputs are processed, making it more efficient and adaptable. It uses a dynamic vision encoding process to effectively handle images of various resolutions, capturing fine details across a range of image qualities. OmChat utilizes an active progressive multimodal pretraining strategy, which gradually increases the model's capacity for long contexts and enhances its overall abilities. By selecting high-quality data during training, OmChat learns from the most relevant and informative data points. With support for a context length of up to 512K, OmChat demonstrates promising performance in tasks involving multiple images and videos, outperforming most open-source models in these benchmarks. Additionally, OmChat proposes a prompting strategy for unifying complex multimodal inputs including single image text, multi-image text and videos, and achieving competitive performance on single-image benchmarks. To further evaluate the model's capabilities, we proposed a benchmark dataset named Temporal Visual Needle in a Haystack. This dataset assesses OmChat's ability to comprehend temporal visual details within long videos. Our analysis highlights several key factors contributing to OmChat's success: support for any-aspect high image resolution, the active progressive pretraining strategy, and high-quality supervised fine-tuning datasets. This report provides a detailed overview of OmChat's capabilities and the strategies that enhance its performance in visual understanding.
OmAgent: A Multi-modal Agent Framework for Complex Video Understanding with Task Divide-and-Conquer
Jun 25, 2024



Recent advancements in Large Language Models (LLMs) have expanded their capabilities to multimodal contexts, including comprehensive video understanding. However, processing extensive videos such as 24-hour CCTV footage or full-length films presents significant challenges due to the vast data and processing demands. Traditional methods, like extracting key frames or converting frames to text, often result in substantial information loss. To address these shortcomings, we develop OmAgent, efficiently stores and retrieves relevant video frames for specific queries, preserving the detailed content of videos. Additionally, it features an Divide-and-Conquer Loop capable of autonomous reasoning, dynamically invoking APIs and tools to enhance query processing and accuracy. This approach ensures robust video understanding, significantly reducing information loss. Experimental results affirm OmAgent's efficacy in handling various types of videos and complex tasks. Moreover, we have endowed it with greater autonomy and a robust tool-calling system, enabling it to accomplish even more intricate tasks.
Preserving Knowledge in Large Language Model: A Model-Agnostic Self-Decompression Approach
Jun 17, 2024



Humans can retain old knowledge while learning new information, but Large Language Models (LLMs) often suffer from catastrophic forgetting when post-pretrained or supervised fine-tuned (SFT) on domain-specific data. Moreover, for Multimodal Large Language Models (MLLMs) which are composed of the LLM base and visual projector (e.g. LLaVA), a significant decline in performance on language benchmarks was observed compared to their single-modality counterparts. To address these challenges, we introduce a novel model-agnostic self-decompression method, Tree Generation (TG), that decompresses knowledge within LLMs into the training corpus. This paper focuses on TG-SFT, which can synthetically generate SFT data for the instruction tuning steps. By incorporating the dumped corpus during SFT for MLLMs, we significantly reduce the forgetting problem.
Real-time Transformer-based Open-Vocabulary Detection with Efficient Fusion Head
Mar 11, 2024



End-to-end transformer-based detectors (DETRs) have shown exceptional performance in both closed-set and open-vocabulary object detection (OVD) tasks through the integration of language modalities. However, their demanding computational requirements have hindered their practical application in real-time object detection (OD) scenarios. In this paper, we scrutinize the limitations of two leading models in the OVDEval benchmark, OmDet and Grounding-DINO, and introduce OmDet-Turbo. This novel transformer-based real-time OVD model features an innovative Efficient Fusion Head (EFH) module designed to alleviate the bottlenecks observed in OmDet and Grounding-DINO. Notably, OmDet-Turbo-Base achieves a 100.2 frames per second (FPS) with TensorRT and language cache techniques applied. Notably, in zero-shot scenarios on COCO and LVIS datasets, OmDet-Turbo achieves performance levels nearly on par with current state-of-the-art supervised models. Furthermore, it establishes new state-of-the-art benchmarks on ODinW and OVDEval, boasting an AP of 30.1 and an NMS-AP of 26.86, respectively. The practicality of OmDet-Turbo in industrial applications is underscored by its exceptional performance on benchmark datasets and superior inference speed, positioning it as a compelling choice for real-time object detection tasks. Code: \url{https://github.com/om-ai-lab/OmDet}
How to Evaluate the Generalization of Detection? A Benchmark for Comprehensive Open-Vocabulary Detection
Aug 25, 2023



Object detection (OD) in computer vision has made significant progress in recent years, transitioning from closed-set labels to open-vocabulary detection (OVD) based on large-scale vision-language pre-training (VLP). However, current evaluation methods and datasets are limited to testing generalization over object types and referral expressions, which do not provide a systematic, fine-grained, and accurate benchmark of OVD models' abilities. In this paper, we propose a new benchmark named OVDEval, which includes 9 sub-tasks and introduces evaluations on commonsense knowledge, attribute understanding, position understanding, object relation comprehension, and more. The dataset is meticulously created to provide hard negatives that challenge models' true understanding of visual and linguistic input. Additionally, we identify a problem with the popular Average Precision (AP) metric when benchmarking models on these fine-grained label datasets and propose a new metric called Non-Maximum Suppression Average Precision (NMS-AP) to address this issue. Extensive experimental results show that existing top OVD models all fail on the new tasks except for simple object types, demonstrating the value of the proposed dataset in pinpointing the weakness of current OVD models and guiding future research. Furthermore, the proposed NMS-AP metric is verified by experiments to provide a much more truthful evaluation of OVD models, whereas traditional AP metrics yield deceptive results. Data is available at \url{https://github.com/om-ai-lab/OVDEval}
OmDet: Language-Aware Object Detection with Large-scale Vision-Language Multi-dataset Pre-training
Sep 10, 2022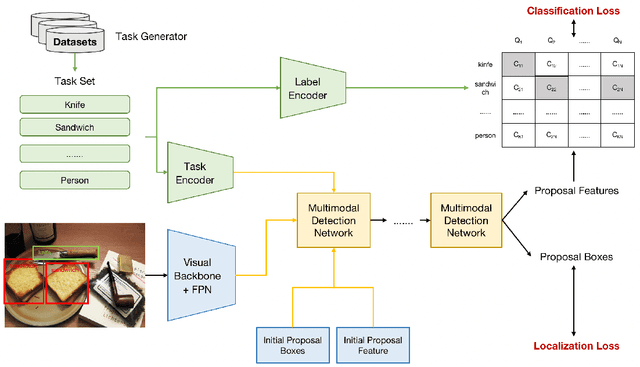


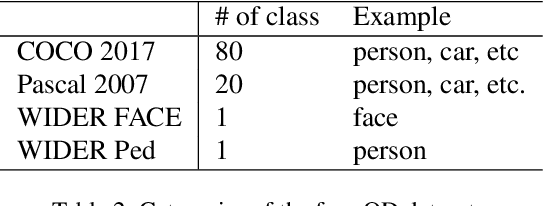
Advancing object detection to open-vocabulary and few-shot transfer has long been a challenge for computer vision research. This work explores a continual learning approach that enables a detector to expand its zero/few-shot capabilities via multi-dataset vision-language pre-training. Using natural language as knowledge representation, we explore methods to accumulate "visual vocabulary" from different training datasets and unify the task as a language-conditioned detection framework. Specifically, we propose a novel language-aware detector OmDet and a novel training mechanism. The proposed multimodal detection network can resolve the technical challenges in multi-dataset joint training and it can generalize to arbitrary number of training datasets without the requirements for manual label taxonomy merging. Experiment results on COCO, Pascal VOC, and Wider Face/Pedestrian confirmed the efficacy by achieving on par or higher scores in joint training compared to training separately. Moreover, we pre-train on more than 20 million images with 4 million unique object vocabulary, and the resulting model is evaluated on 35 downstream tasks of ODinW. Results show that OmDet is able to achieve the state-of-the-art fine-tuned performance on ODinW. And analysis shows that by scaling up the proposed pre-training method, OmDet continues to improve its zero/few-shot tuning performance, suggesting a promising way for further scaling.
VL-CheckList: Evaluating Pre-trained Vision-Language Models with Objects, Attributes and Relations
Jul 01, 2022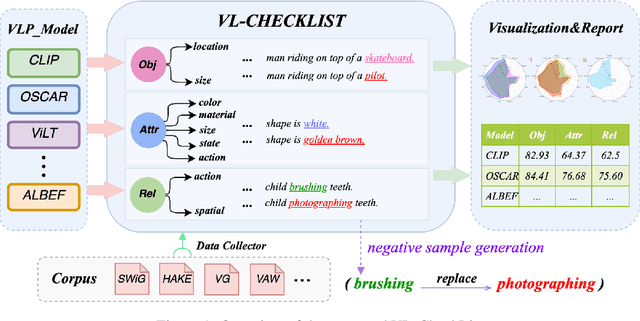
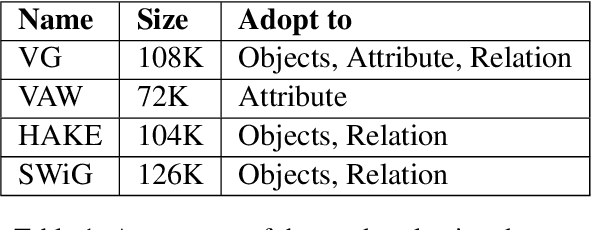
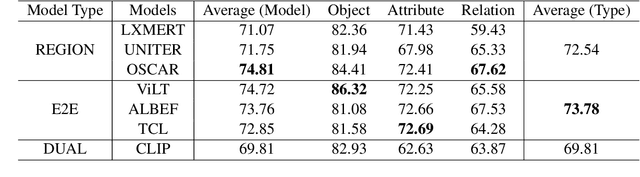
Vision-Language Pretraining (VLP) models have recently successfully facilitated many cross-modal downstream tasks. Most existing works evaluated their systems by comparing the fine-tuned downstream task performance. However, only average downstream task accuracy provides little information about the pros and cons of each VLP method, let alone provides insights on how the community can improve the systems in the future. Inspired by the CheckList for testing natural language processing, we introduce VL-CheckList, a novel framework to understand the capabilities of VLP models. The proposed method divides the image-texting ability of a VLP model into three categories: objects, attributes, and relations, and uses a novel taxonomy to further break down these three aspects. We conduct comprehensive studies to analyze seven recently popular VLP models via the proposed framework. Results confirm the effectiveness of the proposed method by revealing fine-grained differences among the compared models that were not visible from downstream task-only evaluation. Further results show promising research direction in building better VLP models. Data and Code: https://github.com/om-ai-lab/VL-CheckList
When is it permissible for artificial intelligence to lie? A trust-based approach
Mar 14, 2021Conversational Artificial Intelligence (AI) used in industry settings can be trained to closely mimic human behaviors, including lying and deception. However, lying is often a necessary part of negotiation. To address this, we develop a normative framework for when it is ethical or unethical for a conversational AI to lie to humans, based on whether there is what we call "invitation of trust" in a particular scenario. Importantly, cultural norms play an important role in determining whether there is invitation of trust across negotiation settings, and thus an AI trained in one culture may not be generalizable to others. Moreover, individuals may have different expectations regarding the invitation of trust and propensity to lie for human vs. AI negotiators, and these expectations may vary across cultures as well. Finally, we outline how a conversational chatbot can be trained to negotiate ethically by applying autoregressive models to large dialog and negotiations datasets.
SF-QA: Simple and Fair Evaluation Library for Open-domain Question Answering
Jan 06, 2021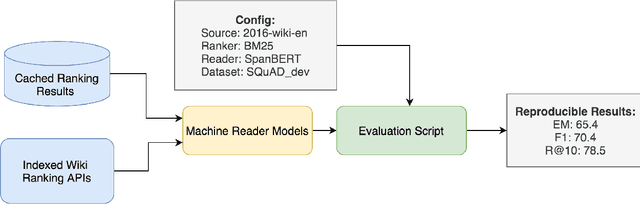
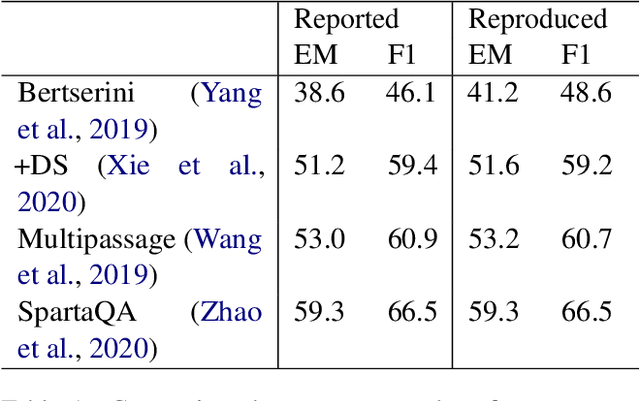
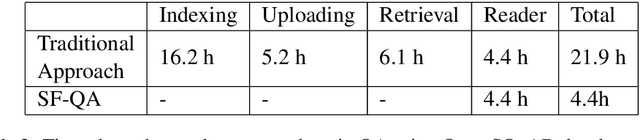

Although open-domain question answering (QA) draws great attention in recent years, it requires large amounts of resources for building the full system and is often difficult to reproduce previous results due to complex configurations. In this paper, we introduce SF-QA: simple and fair evaluation framework for open-domain QA. SF-QA framework modularizes the pipeline open-domain QA system, which makes the task itself easily accessible and reproducible to research groups without enough computing resources. The proposed evaluation framework is publicly available and anyone can contribute to the code and evaluations.