 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Is a picture of a bird a bird": Policy recommendations for dealing with ambiguity in machine vision models
Jun 27, 2023



Many questions that we ask about the world do not have a single clear answer, yet typical human annotation set-ups in machine learning assume there must be a single ground truth label for all examples in every task. The divergence between reality and practice is stark, especially in cases with inherent ambiguity and where the range of different subjective judgments is wide. Here, we examine the implications of subjective human judgments in the behavioral task of labeling images used to train machine vision models. We identify three primary sources of ambiguity arising from (i) depictions of labels in the images, (ii) raters' backgrounds, and (iii) the task definition. On the basis of the empirical results, we suggest best practices for handling label ambiguity in machine learning datasets.
Adversarial Nibbler: A Data-Centric Challenge for Improving the Safety of Text-to-Image Models
May 22, 2023


The generative AI revolution in recent years has been spurred by an expansion in compute power and data quantity, which together enable extensive pre-training of powerful text-to-image (T2I) models. With their greater capabilities to generate realistic and creative content, these T2I models like DALL-E, MidJourney, Imagen or Stable Diffusion are reaching ever wider audiences. Any unsafe behaviors inherited from pretraining on uncurated internet-scraped datasets thus have the potential to cause wide-reaching harm, for example, through generated images which are violent, sexually explicit, or contain biased and derogatory stereotypes. Despite this risk of harm, we lack systematic and structured evaluation datasets to scrutinize model behavior, especially adversarial attacks that bypass existing safety filters. A typical bottleneck in safety evaluation is achieving a wide coverage of different types of challenging examples in the evaluation set, i.e., identifying 'unknown unknowns' or long-tail problems. To address this need, we introduce the Adversarial Nibbler challenge. The goal of this challenge is to crowdsource a diverse set of failure modes and reward challenge participants for successfully finding safety vulnerabilities in current state-of-the-art T2I models. Ultimately, we aim to provide greater awareness of these issues and assist developers in improving the future safety and reliability of generative AI models. Adversarial Nibbler is a data-centric challenge, part of the DataPerf challenge suite, organized and supported by Kaggle and MLCommons.
Human-Centered Responsible Artificial Intelligence: Current & Future Trends
Feb 16, 2023In recent years, the CHI community has seen significant growth in research on Human-Centered Responsible Artificial Intelligence. While different research communities may use different terminology to discuss similar topics, all of this work is ultimately aimed at developing AI that benefits humanity while being grounded in human rights and ethics, and reducing the potential harms of AI. In this special interest group, we aim to bring together researchers from academia and industry interested in these topics to map current and future research trends to advance this important area of research by fostering collaboration and sharing ideas.
DataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022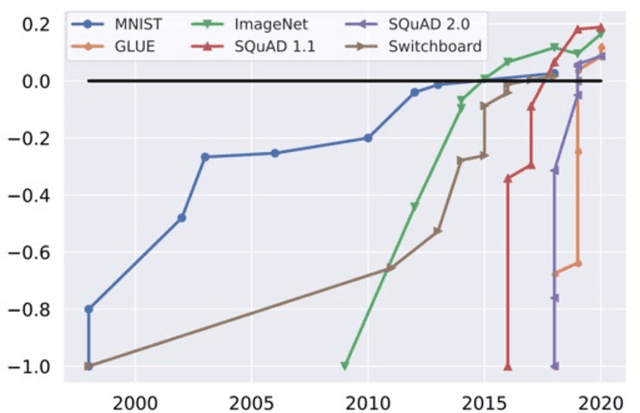
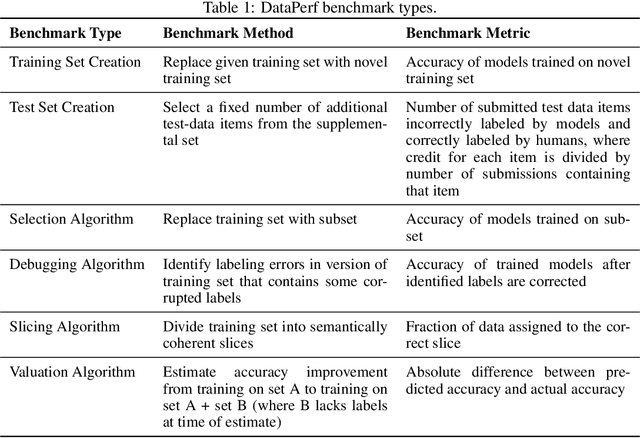
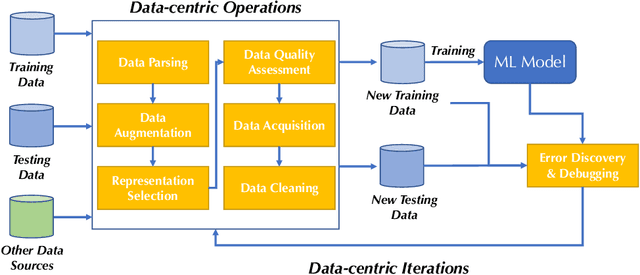
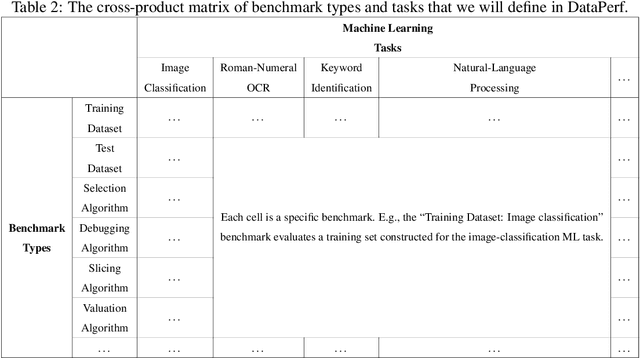
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.
LaMDA: Language Models for Dialog Applications
Feb 10, 2022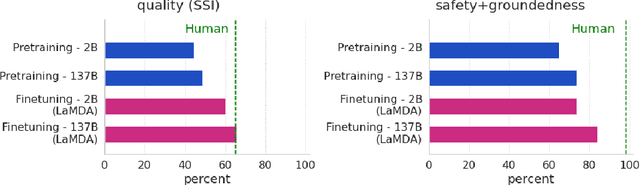
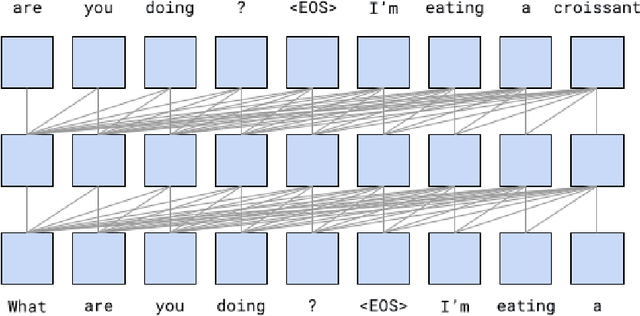

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.
Data Excellence for AI: Why Should You Care
Nov 19, 2021

The efficacy of machine learning (ML) models depends on both algorithms and data. Training data defines what we want our models to learn, and testing data provides the means by which their empirical progress is measured. Benchmark datasets define the entire world within which models exist and operate, yet research continues to focus on critiquing and improving the algorithmic aspect of the models rather than critiquing and improving the data with which our models operate. If "data is the new oil," we are still missing work on the refineries by which the data itself could be optimized for more effective use.
* To appear in ACM Interactions, 29(2) March-April, 2022. 4 pages
Cross-replication Reliability -- An Empirical Approach to Interpreting Inter-rater Reliability
Jun 11, 2021
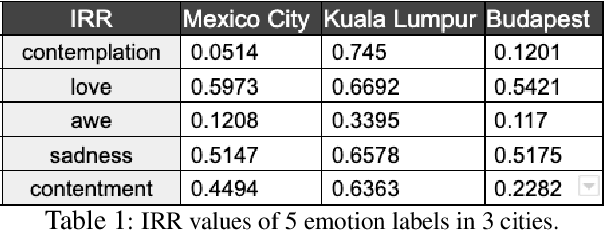
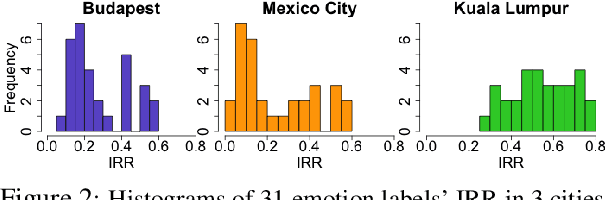
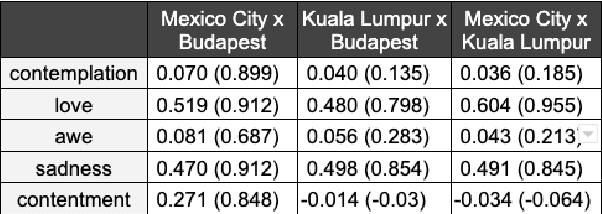
We present a new approach to interpreting IRR that is empirical and contextualized. It is based upon benchmarking IRR against baseline measures in a replication, one of which is a novel cross-replication reliability (xRR) measure based on Cohen's kappa. We call this approach the xRR framework. We opensource a replication dataset of 4 million human judgements of facial expressions and analyze it with the proposed framework. We argue this framework can be used to measure the quality of crowdsourced datasets.
Metrology for AI: From Benchmarks to Instruments
Nov 05, 2019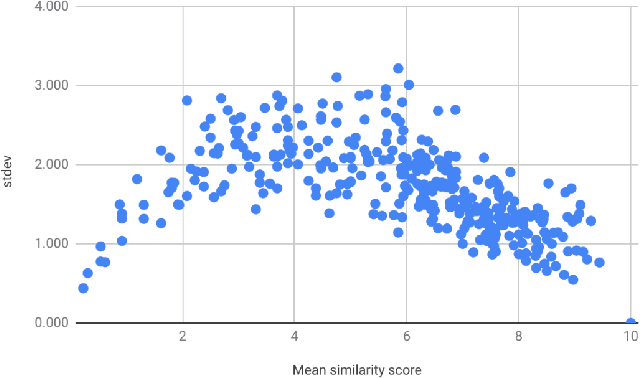
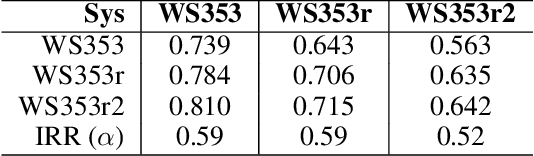
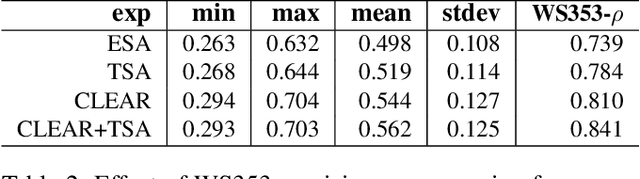
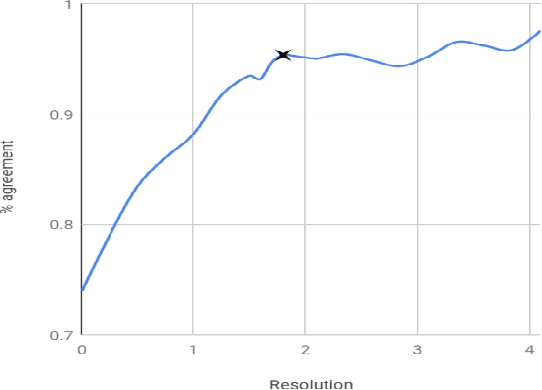
In this paper we present the first steps towards hardening the science of measuring AI systems, by adopting metrology, the science of measurement and its application, and applying it to human (crowd) powered evaluations. We begin with the intuitive observation that evaluating the performance of an AI system is a form of measurement. In all other science and engineering disciplines, the devices used to measure are called instruments, and all measurements are recorded with respect to the characteristics of the instruments used. One does not report mass, speed, or length, for example, of a studied object without disclosing the precision (measurement variance) and resolution (smallest detectable change) of the instrument used. It is extremely common in the AI literature to compare the performance of two systems by using a crowd-sourced dataset as an instrument, but failing to report if the performance difference lies within the capability of that instrument to measure. To illustrate the adoption of metrology to benchmark datasets we use the word similarity benchmark WS353 and several previously published experiments that use it for evaluation.
A Crowdsourced Frame Disambiguation Corpus with Ambiguity
Apr 12, 2019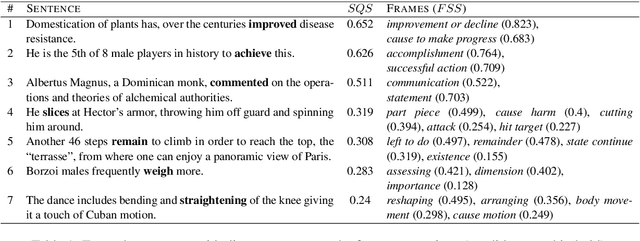
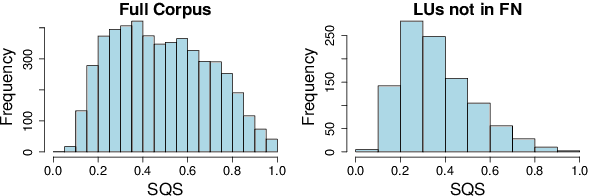
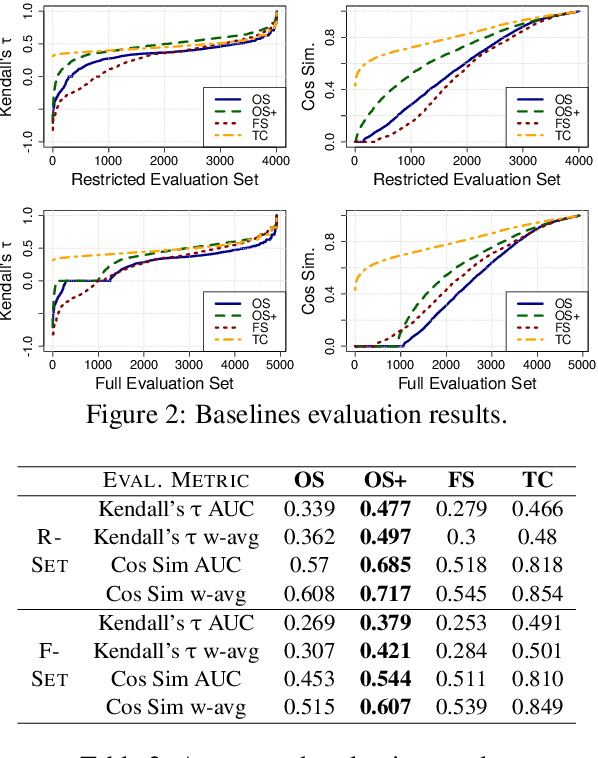
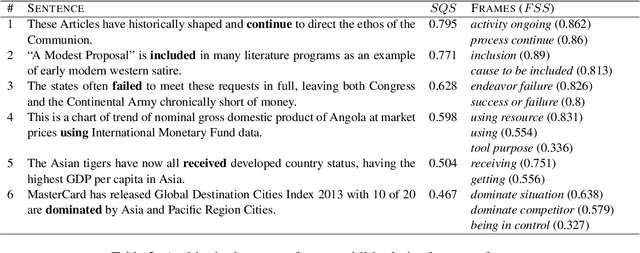
We present a resource for the task of FrameNet semantic frame disambiguation of over 5,000 word-sentence pairs from the Wikipedia corpus. The annotations were collected using a novel crowdsourcing approach with multiple workers per sentence to capture inter-annotator disagreement. In contrast to the typical approach of attributing the best single frame to each word, we provide a list of frames with disagreement-based scores that express the confidence with which each frame applies to the word. This is based on the idea that inter-annotator disagreement is at least partly caused by ambiguity that is inherent to the text and frames. We have found many examples where the semantics of individual frames overlap sufficiently to make them acceptable alternatives for interpreting a sentence. We have argued that ignoring this ambiguity creates an overly arbitrary target for training and evaluating natural language processing systems - if humans cannot agree, why would we expect the correct answer from a machine to be any different? To process this data we also utilized an expanded lemma-set provided by the Framester system, which merges FN with WordNet to enhance coverage. Our dataset includes annotations of 1,000 sentence-word pairs whose lemmas are not part of FN. Finally we present metrics for evaluating frame disambiguation systems that account for ambiguity.
Crowdsourcing Semantic Label Propagation in Relation Classification
Sep 03, 2018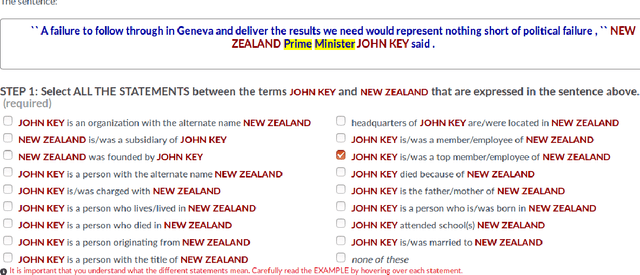
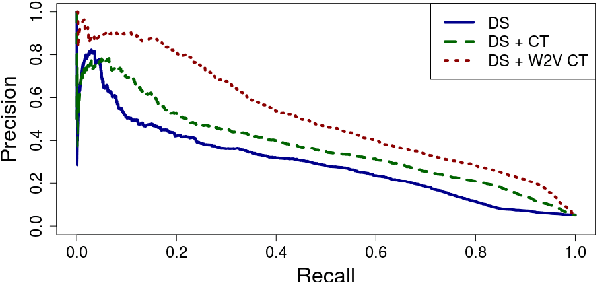
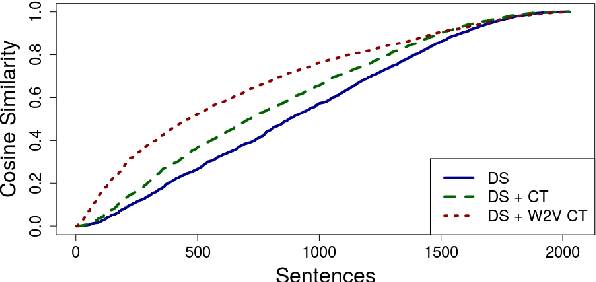
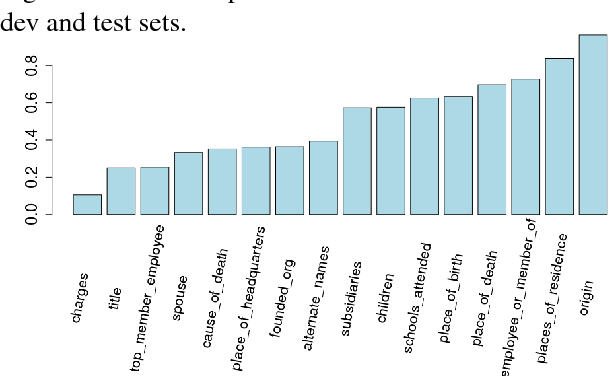
Distant supervision is a popular method for performing relation extraction from text that is known to produce noisy labels. Most progress in relation extraction and classification has been made with crowdsourced corrections to distant-supervised labels, and there is evidence that indicates still more would be better. In this paper, we explore the problem of propagating human annotation signals gathered for open-domain relation classification through the CrowdTruth methodology for crowdsourcing, that captures ambiguity in annotations by measuring inter-annotator disagreement. Our approach propagates annotations to sentences that are similar in a low dimensional embedding space, expanding the number of labels by two orders of magnitude. Our experiments show significant improvement in a sentence-level multi-class relation classifier.