 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe AnIML Ontology: Enabling Semantic Interoperability for Large-Scale Experimental Data in Interconnected Scientific Labs
Apr 02, 2026Achieving semantic interoperability across heterogeneous experimental data systems remains a major barrier to data-driven scientific discovery. The Analytical Information Markup Language (AnIML), a flexible XML-based standard for analytical chemistry and biology, is increasingly used in industrial R&D labs for managing and exchanging experimental data. However, the expressivity of the XML schema permits divergent interpretations across stakeholders, introducing inconsistencies that undermine the interoperability the AnIML schema was designed to support. In this paper, we present the AnIML Ontology, an OWL 2 ontology that formalises the semantics of AnIML and aligns it with the Allotrope Data Format to support future cross-system and cross-lab interoperability. The ontology was developed using an expert-in-the-loop approach combining LLM-assisted requirement elicitation with collaborative ontology engineering. We validate the ontology through a multi-layered approach: data-driven transformation of real-world AnIML files into knowledge graphs, competency question verification via SPARQL, and a novel validation protocol based on adversarial negative competency questions mapped to established ontological anti-patterns and enforced via SHACL constraints.
IDEA2: Expert-in-the-loop competency question elicitation for collaborative ontology engineering
Apr 01, 2026Competency question (CQ) elicitation represents a critical but resource-intensive bottleneck in ontology engineering. This foundational phase is often hampered by the communication gap between domain experts, who possess the necessary knowledge, and ontology engineers, who formalise it. This paper introduces IDEA2, a novel, semi-automated workflow that integrates Large Language Models (LLMs) within a collaborative, expert-in-the-loop process to address this challenge. The methodology is characterised by a core iterative loop: an initial LLM-based extraction of CQs from requirement documents, a co-creational review and feedback phase by domain experts on an accessible collaborative platform, and an iterative, feedback-driven reformulation of rejected CQs by an LLM until consensus is achieved. To ensure transparency and reproducibility, the entire lifecycle of each CQ is tracked using a provenance model that captures the full lineage of edits, anonymised feedback, and generation parameters. The workflow was validated in 2 real-world scenarios (scientific data, cultural heritage), demonstrating that IDEA2 can accelerate the requirements engineering process, improve the acceptance and relevance of the resulting CQs, and exhibit high usability and effectiveness among domain experts. We release all code and experiments at https://github.com/KE-UniLiv/IDEA2
Evaluating and Improving the Effectiveness of Synthetic Chest X-Rays for Medical Image Analysis
Nov 27, 2024Purpose: To explore best-practice approaches for generating synthetic chest X-ray images and augmenting medical imaging datasets to optimize the performance of deep learning models in downstream tasks like classification and segmentation. Materials and Methods: We utilized a latent diffusion model to condition the generation of synthetic chest X-rays on text prompts and/or segmentation masks. We explored methods like using a proxy model and using radiologist feedback to improve the quality of synthetic data. These synthetic images were then generated from relevant disease information or geometrically transformed segmentation masks and added to ground truth training set images from the CheXpert, CANDID-PTX, SIIM, and RSNA Pneumonia datasets to measure improvements in classification and segmentation model performance on the test sets. F1 and Dice scores were used to evaluate classification and segmentation respectively. One-tailed t-tests with Bonferroni correction assessed the statistical significance of performance improvements with synthetic data. Results: Across all experiments, the synthetic data we generated resulted in a maximum mean classification F1 score improvement of 0.150453 (CI: 0.099108-0.201798; P=0.0031) compared to using only real data. For segmentation, the maximum Dice score improvement was 0.14575 (CI: 0.108267-0.183233; P=0.0064). Conclusion: Best practices for generating synthetic chest X-ray images for downstream tasks include conditioning on single-disease labels or geometrically transformed segmentation masks, as well as potentially using proxy modeling for fine-tuning such generations.
Auto-Generating Weak Labels for Real & Synthetic Data to Improve Label-Scarce Medical Image Segmentation
Apr 25, 2024



The high cost of creating pixel-by-pixel gold-standard labels, limited expert availability, and presence of diverse tasks make it challenging to generate segmentation labels to train deep learning models for medical imaging tasks. In this work, we present a new approach to overcome the hurdle of costly medical image labeling by leveraging foundation models like Segment Anything Model (SAM) and its medical alternate MedSAM. Our pipeline has the ability to generate weak labels for any unlabeled medical image and subsequently use it to augment label-scarce datasets. We perform this by leveraging a model trained on a few gold-standard labels and using it to intelligently prompt MedSAM for weak label generation. This automation eliminates the manual prompting step in MedSAM, creating a streamlined process for generating labels for both real and synthetic images, regardless of quantity. We conduct experiments on label-scarce settings for multiple tasks pertaining to modalities ranging from ultrasound, dermatology, and X-rays to demonstrate the usefulness of our pipeline. The code is available at https://github.com/stanfordmlgroup/Auto-Generate-WLs/.
Unlocking Robust Segmentation Across All Age Groups via Continual Learning
Apr 19, 2024


Most deep learning models in medical imaging are trained on adult data with unclear performance on pediatric images. In this work, we aim to address this challenge in the context of automated anatomy segmentation in whole-body Computed Tomography (CT). We evaluate the performance of CT organ segmentation algorithms trained on adult data when applied to pediatric CT volumes and identify substantial age-dependent underperformance. We subsequently propose and evaluate strategies, including data augmentation and continual learning approaches, to achieve good segmentation accuracy across all age groups. Our best-performing model, trained using continual learning, achieves high segmentation accuracy on both adult and pediatric data (Dice scores of 0.90 and 0.84 respectively).
LymphoML: An interpretable artificial intelligence-based method identifies morphologic features that correlate with lymphoma subtype
Nov 20, 2023



The accurate classification of lymphoma subtypes using hematoxylin and eosin (H&E)-stained tissue is complicated by the wide range of morphological features these cancers can exhibit. We present LymphoML - an interpretable machine learning method that identifies morphologic features that correlate with lymphoma subtypes. Our method applies steps to process H&E-stained tissue microarray cores, segment nuclei and cells, compute features encompassing morphology, texture, and architecture, and train gradient-boosted models to make diagnostic predictions. LymphoML's interpretable models, developed on a limited volume of H&E-stained tissue, achieve non-inferior diagnostic accuracy to pathologists using whole-slide images and outperform black box deep-learning on a dataset of 670 cases from Guatemala spanning 8 lymphoma subtypes. Using SHapley Additive exPlanation (SHAP) analysis, we assess the impact of each feature on model prediction and find that nuclear shape features are most discriminative for DLBCL (F1-score: 78.7%) and classical Hodgkin lymphoma (F1-score: 74.5%). Finally, we provide the first demonstration that a model combining features from H&E-stained tissue with features from a standardized panel of 6 immunostains results in a similar diagnostic accuracy (85.3%) to a 46-stain panel (86.1%).
How to Train Your CheXDragon: Training Chest X-Ray Models for Transfer to Novel Tasks and Healthcare Systems
May 13, 2023



Self-supervised learning (SSL) enables label efficient training for machine learning models. This is essential for domains such as medical imaging, where labels are costly and time-consuming to curate. However, the most effective supervised or SSL strategy for transferring models to different healthcare systems or novel tasks is not well understood. In this work, we systematically experiment with a variety of supervised and self-supervised pretraining strategies using multimodal datasets of medical images (chest X-rays) and text (radiology reports). We then evaluate their performance on data from two external institutions with diverse sets of tasks. In addition, we experiment with different transfer learning strategies to effectively adapt these pretrained models to new tasks and healthcare systems. Our empirical results suggest that multimodal SSL gives substantial gains over unimodal SSL in performance across new healthcare systems and tasks, comparable to models pretrained with full supervision. We demonstrate additional performance gains with models further adapted to the new dataset and task, using multimodal domain-adaptive pretraining (DAPT), linear probing then finetuning (LP-FT), and both methods combined. We offer suggestions for alternative models to use in scenarios where not all of these additions are feasible. Our results provide guidance for improving the generalization of medical image interpretation models to new healthcare systems and novel tasks.
DataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022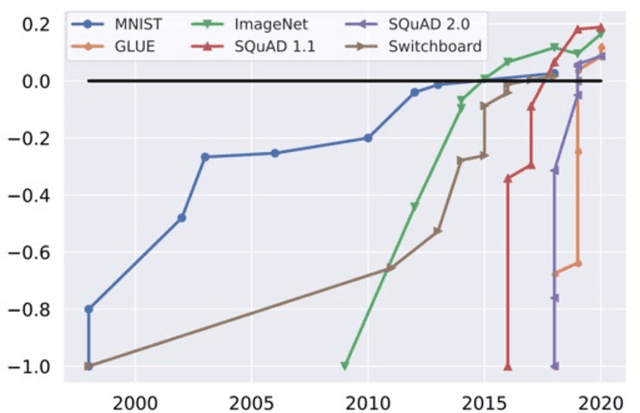
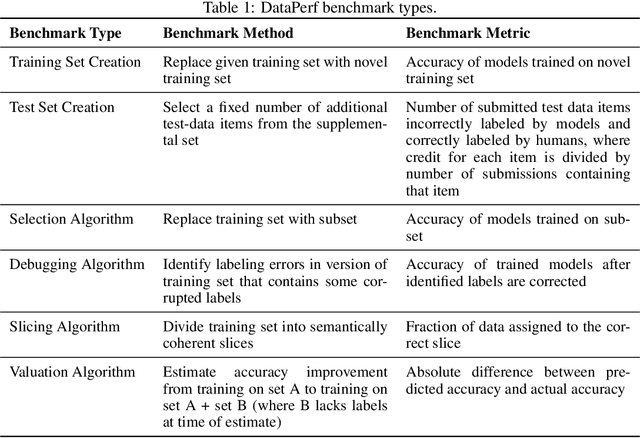
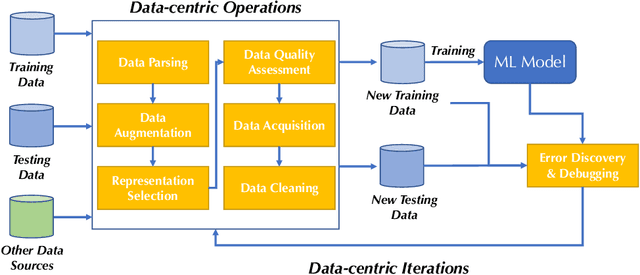
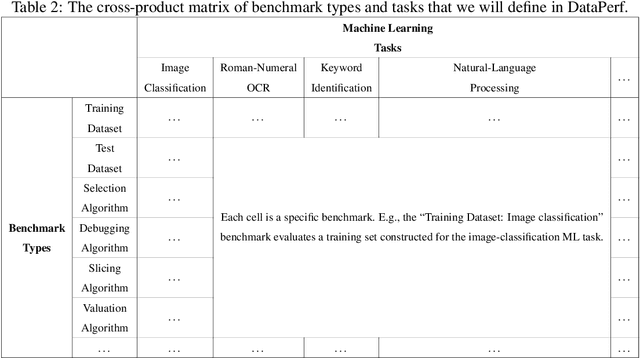
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.
Effective Data Fusion with Generalized Vegetation Index: Evidence from Land Cover Segmentation in Agriculture
May 07, 2020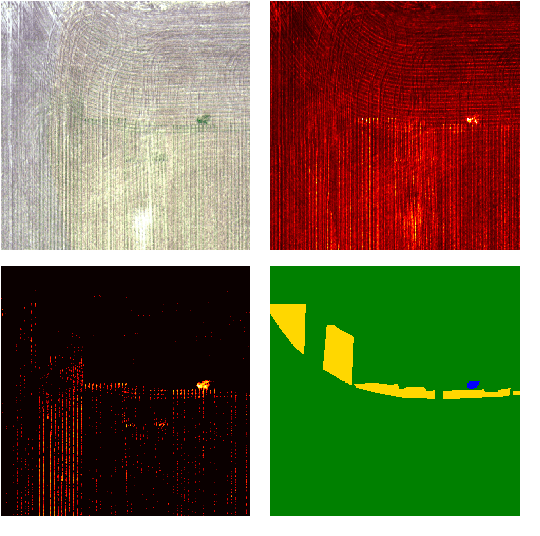

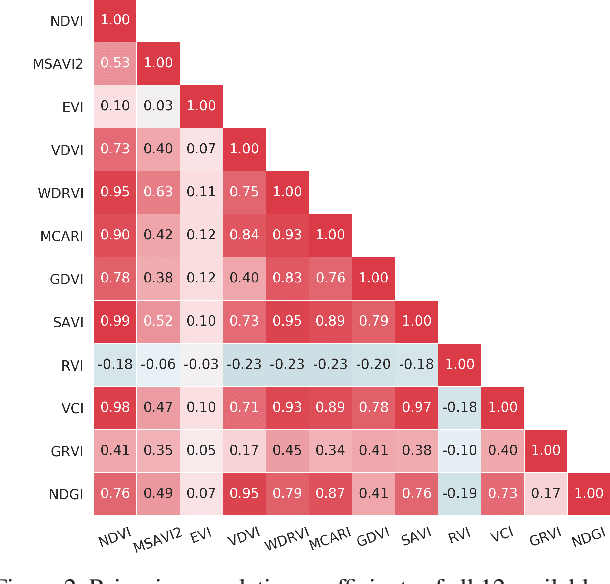
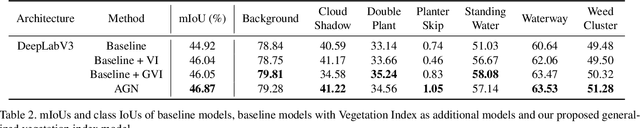
How can we effectively leverage the domain knowledge from remote sensing to better segment agriculture land cover from satellite images? In this paper, we propose a novel, model-agnostic, data-fusion approach for vegetation-related computer vision tasks. Motivated by the various Vegetation Indices (VIs), which are introduced by domain experts, we systematically reviewed the VIs that are widely used in remote sensing and their feasibility to be incorporated in deep neural networks. To fully leverage the Near-Infrared channel, the traditional Red-Green-Blue channels, and Vegetation Index or its variants, we propose a Generalized Vegetation Index (GVI), a lightweight module that can be easily plugged into many neural network architectures to serve as an additional information input. To smoothly train models with our GVI, we developed an Additive Group Normalization (AGN) module that does not require extra parameters of the prescribed neural networks. Our approach has improved the IoUs of vegetation-related classes by 0.9-1.3 percent and consistently improves the overall mIoU by 2 percent on our baseline.
The 1st Agriculture-Vision Challenge: Methods and Results
Apr 23, 2020
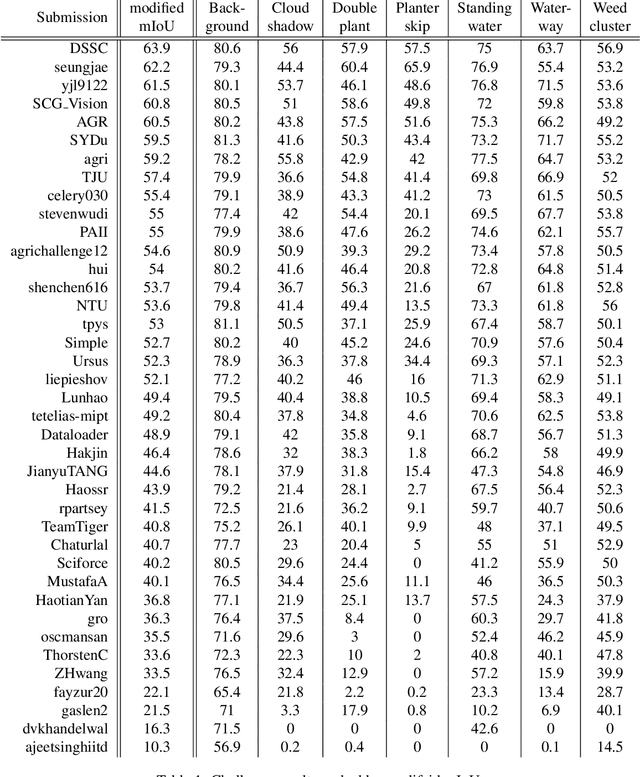
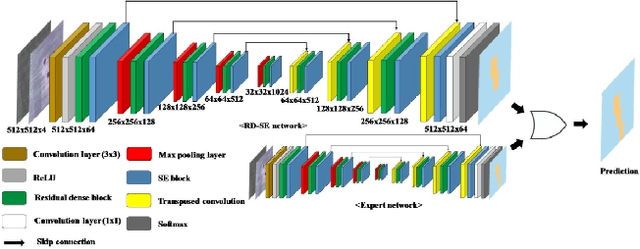
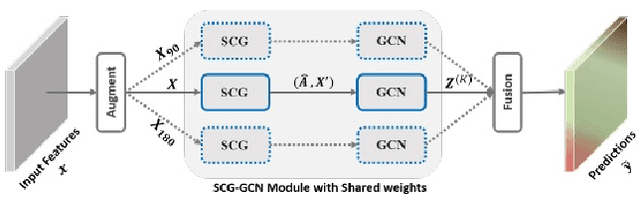
The first Agriculture-Vision Challenge aims to encourage research in developing novel and effective algorithms for agricultural pattern recognition from aerial images, especially for the semantic segmentation task associated with our challenge dataset. Around 57 participating teams from various countries compete to achieve state-of-the-art in aerial agriculture semantic segmentation. The Agriculture-Vision Challenge Dataset was employed, which comprises of 21,061 aerial and multi-spectral farmland images. This paper provides a summary of notable methods and results in the challenge. Our submission server and leaderboard will continue to open for researchers that are interested in this challenge dataset and task; the link can be found here.