 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Alignment of Behavioral Dispositions in LLMs
Feb 11, 2026As LLMs integrate into our daily lives, understanding their behavior becomes essential. In this work, we focus on behavioral dispositions$-$the underlying tendencies that shape responses in social contexts$-$and introduce a framework to study how closely the dispositions expressed by LLMs align with those of humans. Our approach is grounded in established psychological questionnaires but adapts them for LLMs by transforming human self-report statements into Situational Judgment Tests (SJTs). These SJTs assess behavior by eliciting natural recommendations in realistic user-assistant scenarios. We generate 2,500 SJTs, each validated by three human annotators, and collect preferred actions from 10 annotators per SJT, from a large pool of 550 participants. In a comprehensive study involving 25 LLMs, we find that models often do not reflect the distribution of human preferences: (1) in scenarios with low human consensus, LLMs consistently exhibit overconfidence in a single response; (2) when human consensus is high, smaller models deviate significantly, and even some frontier models do not reflect the consensus in 15-20% of cases; (3) traits can exhibit cross-LLM patterns, e.g., LLMs may encourage emotion expression in contexts where human consensus favors composure. Lastly, mapping psychometric statements directly to behavioral scenarios presents a unique opportunity to evaluate the predictive validity of self-reports, revealing considerable gaps between LLMs' stated values and their revealed behavior.
LaMDA: Language Models for Dialog Applications
Feb 10, 2022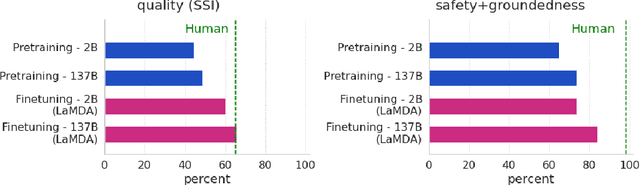
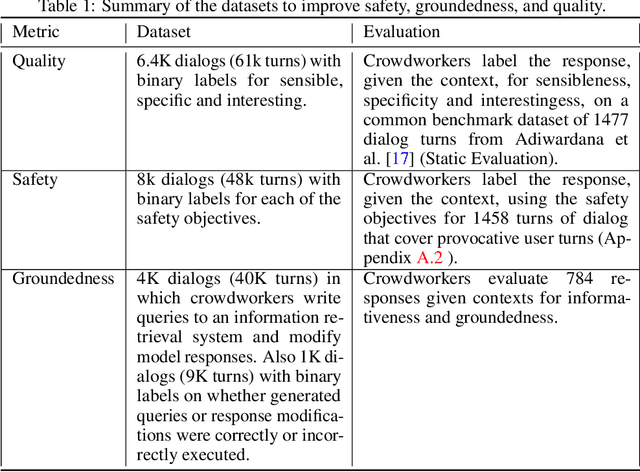
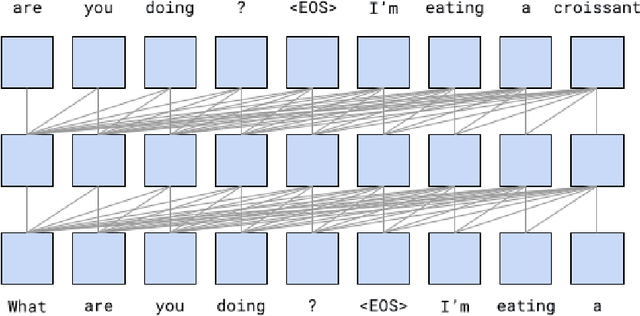

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.