 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurveys Considered Harmful? Reflecting on the Use of Surveys in AI Research, Development, and Governance
Jul 26, 2024

Calls for engagement with the public in Artificial Intelligence (AI) research, development, and governance are increasing, leading to the use of surveys to capture people's values, perceptions, and experiences related to AI. In this paper, we critically examine the state of human participant surveys associated with these topics. Through both a reflexive analysis of a survey pilot spanning six countries and a systematic literature review of 44 papers featuring public surveys related to AI, we explore prominent perspectives and methodological nuances associated with surveys to date. We find that public surveys on AI topics are vulnerable to specific Western knowledge, values, and assumptions in their design, including in their positioning of ethical concepts and societal values, lack sufficient critical discourse surrounding deployment strategies, and demonstrate inconsistent forms of transparency in their reporting. Based on our findings, we distill provocations and heuristic questions for our community, to recognize the limitations of surveys for meeting the goals of engagement, and to cultivate shared principles to design, deploy, and interpret surveys cautiously and responsibly.
Design Principles for Generative AI Applications
Jan 25, 2024



Generative AI applications present unique design challenges. As generative AI technologies are increasingly being incorporated into mainstream applications, there is an urgent need for guidance on how to design user experiences that foster effective and safe use. We present six principles for the design of generative AI applications that address unique characteristics of generative AI UX and offer new interpretations and extensions of known issues in the design of AI applications. Each principle is coupled with a set of design strategies for implementing that principle via UX capabilities or through the design process. The principles and strategies were developed through an iterative process involving literature review, feedback from design practitioners, validation against real-world generative AI applications, and incorporation into the design process of two generative AI applications. We anticipate the principles to usefully inform the design of generative AI applications by driving actionable design recommendations.
Human-Centered Responsible Artificial Intelligence: Current & Future Trends
Feb 16, 2023
In recent years, the CHI community has seen significant growth in research on Human-Centered Responsible Artificial Intelligence. While different research communities may use different terminology to discuss similar topics, all of this work is ultimately aimed at developing AI that benefits humanity while being grounded in human rights and ethics, and reducing the potential harms of AI. In this special interest group, we aim to bring together researchers from academia and industry interested in these topics to map current and future research trends to advance this important area of research by fostering collaboration and sharing ideas.
A Case Study in Engineering a Conversational Programming Assistant's Persona
Jan 13, 2023The Programmer's Assistant is an experimental prototype software development environment that integrates a chatbot with a code editor. Conversational capability was achieved by using an existing code-fluent Large Language Model and providing it with a prompt that establishes a conversational interaction pattern, a set of conventions, and a style of interaction appropriate for the application. A discussion of the evolution of the prompt provides a case study in how to coax an existing foundation model to behave in a desirable manner for a particular application.
Toward General Design Principles for Generative AI Applications
Jan 13, 2023
Generative AI technologies are growing in power, utility, and use. As generative technologies are being incorporated into mainstream applications, there is a need for guidance on how to design those applications to foster productive and safe use. Based on recent research on human-AI co-creation within the HCI and AI communities, we present a set of seven principles for the design of generative AI applications. These principles are grounded in an environment of generative variability. Six principles are focused on designing for characteristics of generative AI: multiple outcomes & imperfection; exploration & control; and mental models & explanations. In addition, we urge designers to design against potential harms that may be caused by a generative model's hazardous output, misuse, or potential for human displacement. We anticipate these principles to usefully inform design decisions made in the creation of novel human-AI applications, and we invite the community to apply, revise, and extend these principles to their own work.
Investigating Explainability of Generative AI for Code through Scenario-based Design
Feb 10, 2022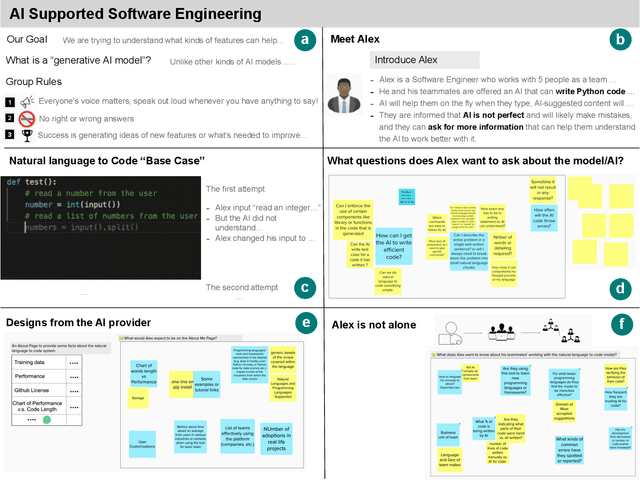
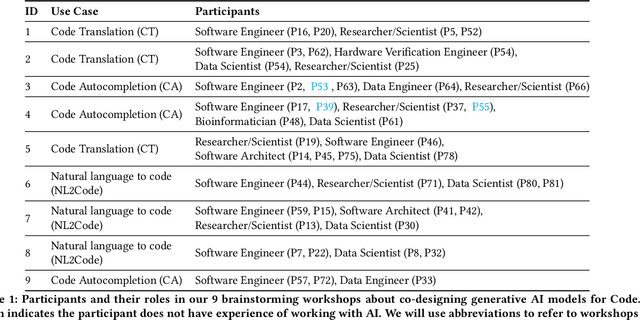

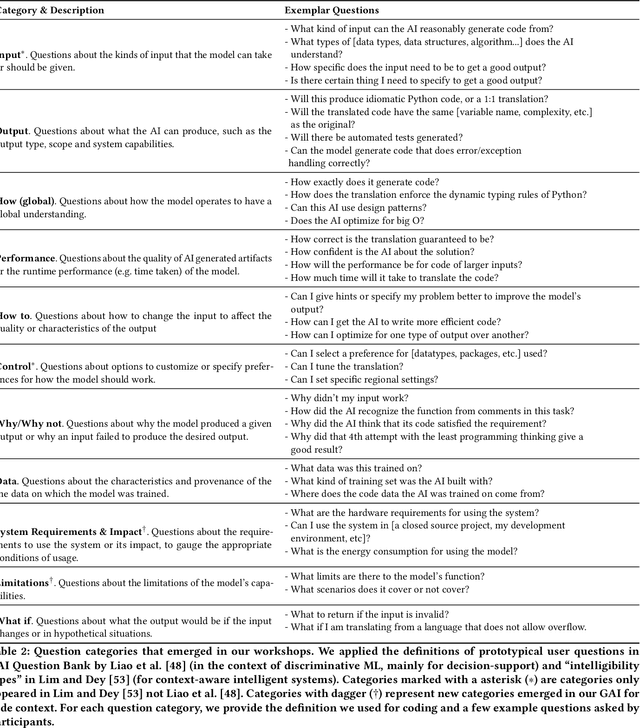
What does it mean for a generative AI model to be explainable? The emergent discipline of explainable AI (XAI) has made great strides in helping people understand discriminative models. Less attention has been paid to generative models that produce artifacts, rather than decisions, as output. Meanwhile, generative AI (GenAI) technologies are maturing and being applied to application domains such as software engineering. Using scenario-based design and question-driven XAI design approaches, we explore users' explainability needs for GenAI in three software engineering use cases: natural language to code, code translation, and code auto-completion. We conducted 9 workshops with 43 software engineers in which real examples from state-of-the-art generative AI models were used to elicit users' explainability needs. Drawing from prior work, we also propose 4 types of XAI features for GenAI for code and gathered additional design ideas from participants. Our work explores explainability needs for GenAI for code and demonstrates how human-centered approaches can drive the technical development of XAI in novel domains.
Using Document Similarity Methods to create Parallel Datasets for Code Translation
Oct 11, 2021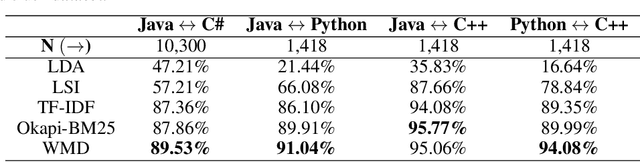
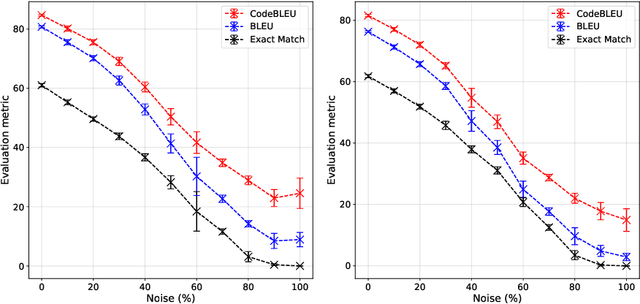
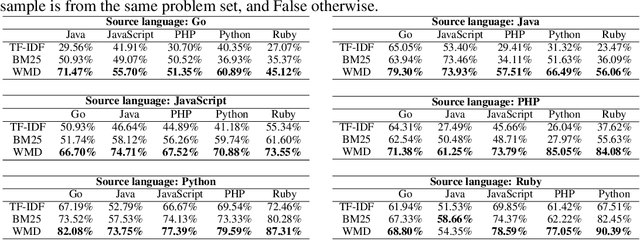
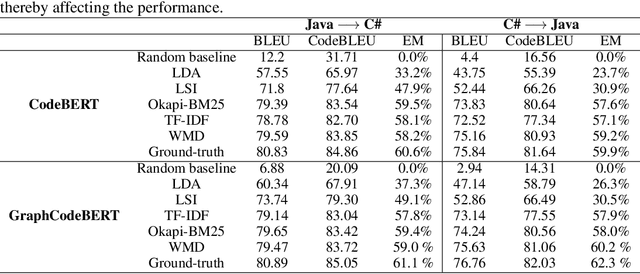
Translating source code from one programming language to another is a critical, time-consuming task in modernizing legacy applications and codebases. Recent work in this space has drawn inspiration from the software naturalness hypothesis by applying natural language processing techniques towards automating the code translation task. However, due to the paucity of parallel data in this domain, supervised techniques have only been applied to a limited set of popular programming languages. To bypass this limitation, unsupervised neural machine translation techniques have been proposed to learn code translation using only monolingual corpora. In this work, we propose to use document similarity methods to create noisy parallel datasets of code, thus enabling supervised techniques to be applied for automated code translation without having to rely on the availability or expensive curation of parallel code datasets. We explore the noise tolerance of models trained on such automatically-created datasets and show that these models perform comparably to models trained on ground truth for reasonable levels of noise. Finally, we exhibit the practical utility of the proposed method by creating parallel datasets for languages beyond the ones explored in prior work, thus expanding the set of programming languages for automated code translation.
The Who in Explainable AI: How AI Background Shapes Perceptions of AI Explanations
Jul 28, 2021
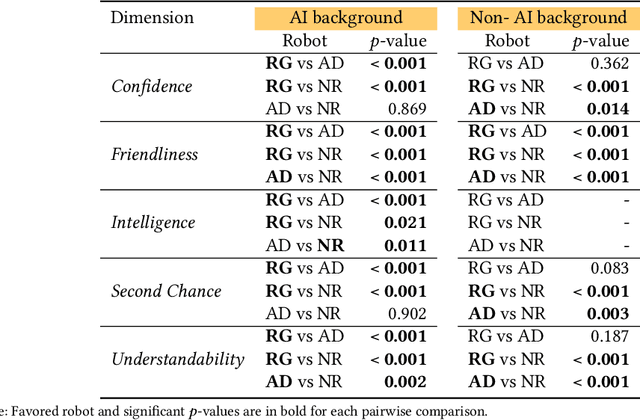
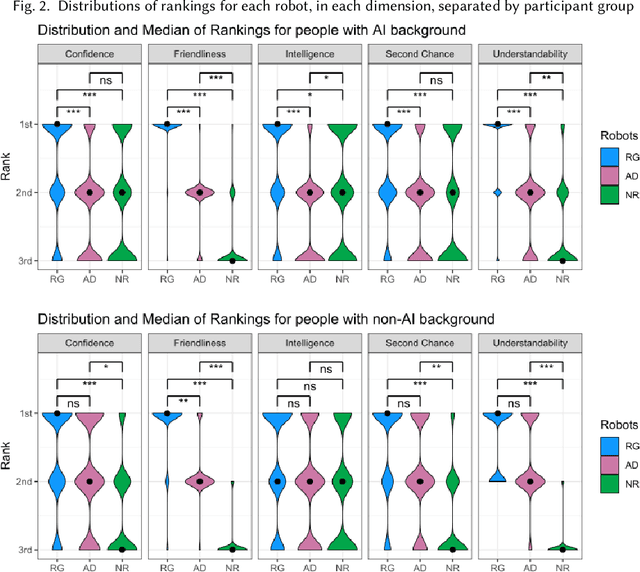
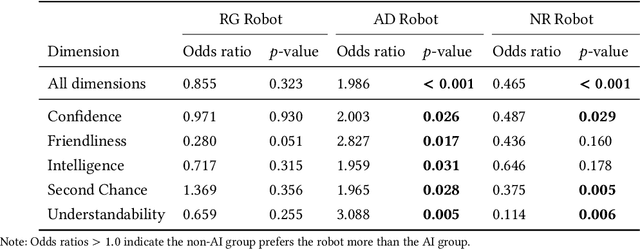
Explainability of AI systems is critical for users to take informed actions and hold systems accountable. While "opening the opaque box" is important, understanding who opens the box can govern if the Human-AI interaction is effective. In this paper, we conduct a mixed-methods study of how two different groups of whos--people with and without a background in AI--perceive different types of AI explanations. These groups were chosen to look at how disparities in AI backgrounds can exacerbate the creator-consumer gap. We quantitatively share what the perceptions are along five dimensions: confidence, intelligence, understandability, second chance, and friendliness. Qualitatively, we highlight how the AI background influences each group's interpretations and elucidate why the differences might exist through the lenses of appropriation and cognitive heuristics. We find that (1) both groups had unwarranted faith in numbers, to different extents and for different reasons, (2) each group found explanatory values in different explanations that went beyond the usage we designed them for, and (3) each group had different requirements of what counts as humanlike explanations. Using our findings, we discuss potential negative consequences such as harmful manipulation of user trust and propose design interventions to mitigate them. By bringing conscious awareness to how and why AI backgrounds shape perceptions of potential creators and consumers in XAI, our work takes a formative step in advancing a pluralistic Human-centered Explainable AI discourse.
How AI Developers Overcome Communication Challenges in a Multidisciplinary Team: A Case Study
Jan 13, 2021
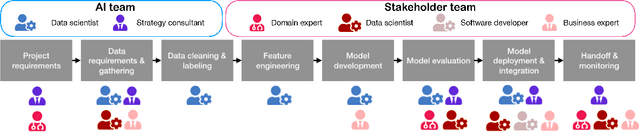
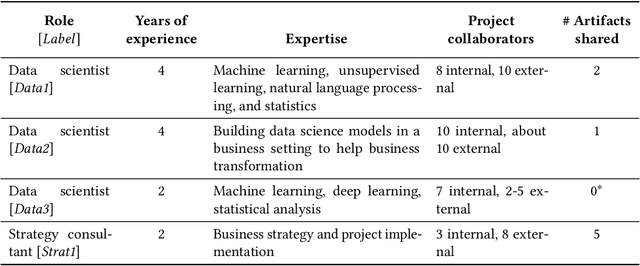
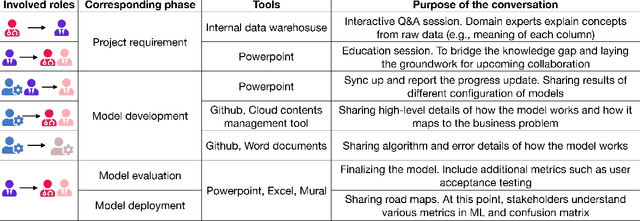
The development of AI applications is a multidisciplinary effort, involving multiple roles collaborating with the AI developers, an umbrella term we use to include data scientists and other AI-adjacent roles on the same team. During these collaborations, there is a knowledge mismatch between AI developers, who are skilled in data science, and external stakeholders who are typically not. This difference leads to communication gaps, and the onus falls on AI developers to explain data science concepts to their collaborators. In this paper, we report on a study including analyses of both interviews with AI developers and artifacts they produced for communication. Using the analytic lens of shared mental models, we report on the types of communication gaps that AI developers face, how AI developers communicate across disciplinary and organizational boundaries, and how they simultaneously manage issues regarding trust and expectations.
Expanding Explainability: Towards Social Transparency in AI systems
Jan 12, 2021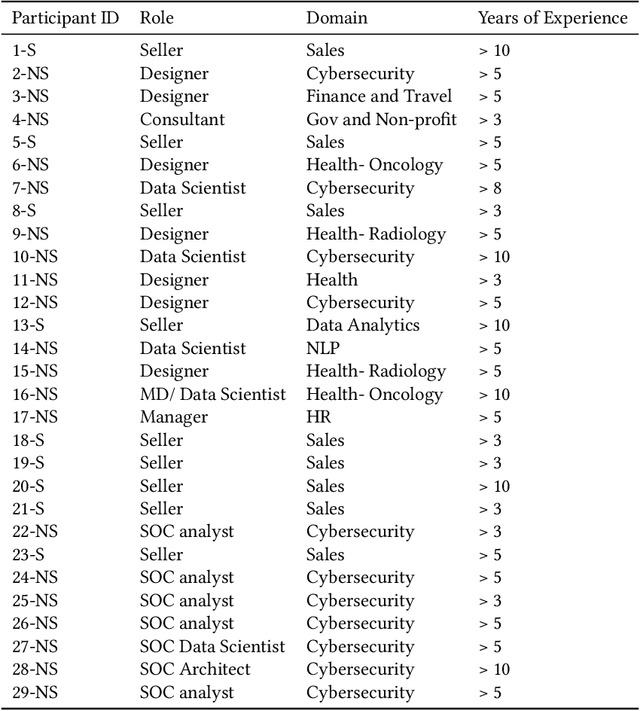
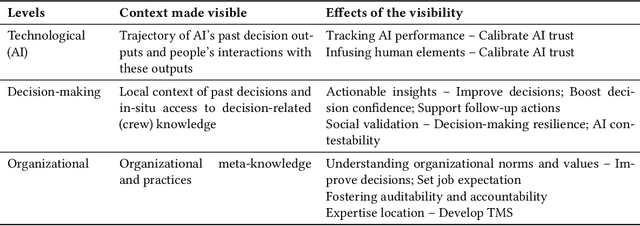

As AI-powered systems increasingly mediate consequential decision-making, their explainability is critical for end-users to take informed and accountable actions. Explanations in human-human interactions are socially-situated. AI systems are often socio-organizationally embedded. However, Explainable AI (XAI) approaches have been predominantly algorithm-centered. We take a developmental step towards socially-situated XAI by introducing and exploring Social Transparency (ST), a sociotechnically informed perspective that incorporates the socio-organizational context into explaining AI-mediated decision-making. To explore ST conceptually, we conducted interviews with 29 AI users and practitioners grounded in a speculative design scenario. We suggested constitutive design elements of ST and developed a conceptual framework to unpack ST's effect and implications at the technical, decision-making, and organizational level. The framework showcases how ST can potentially calibrate trust in AI, improve decision-making, facilitate organizational collective actions, and cultivate holistic explainability. Our work contributes to the discourse of Human-Centered XAI by expanding the design space of XAI.