 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Model Safety by Targeted Error Correction
May 04, 2026The widespread adoption of machine learning in critical applications demands techniques to mitigate high-consequence errors. Our method utilizes a dual-classifier GBDT pipeline to distinguish routine human-like errors from high-risk non-human misclassifications. Evaluated across three domains, animal breed classification, skin lesion diagnosis (ISIC 2018), and prostate histopathology (SICAPv2), our framework demonstrates robust safety improvements. To address real-world deployment concerns, our results confirm the pipeline introduces negligible inference latency (1.60% overhead for the animal dataset, 1.84% for ISIC, and 1.70% for SICAPv2) while outperforming traditional Maximum Class Probability (MCP) baselines in correction precision. Our conservative correction strategy successfully reduced dangerous non-human errors by 34.1% in ISIC and 12.57% in SICAPv2, improving super-class diagnostic safety to 90.41% and 92.13% respectively. This proves that safety-critical reliability can be substantially enhanced post-hoc without expensive model retraining. keywords: Error Analysis, Post-hoc Correction, Trustworthy AI.
Face Density as a Proxy for Data Complexity: Quantifying the Hardness of Instance Count
Apr 14, 2026Machine learning progress has historically prioritized model-centric innovations, yet achievable performance is frequently capped by the intrinsic complexity of the data itself. In this work, we isolate and quantify the impact of instance density (measured by face count) as a primary driver of data complexity. Rather than simply observing that ``crowded scenes are harder,'' we rigorously control for class imbalance to measure the precise degradation caused by density alone. Controlled experiments on the WIDER FACE and Open Images datasets, restricted to exactly 1 to 18 faces per image with perfectly balanced sampling, reveal that model performance degrades monotonically with increasing face count. This trend holds across classification, regression, and detection paradigms, even when models are fully exposed to the entire density range. Furthermore, we demonstrate that models trained on low-density regimes fail to generalize to higher densities, exhibiting a systematic under-counting bias, with error rates increasing by up to 4.6x, which suggests density acts as a domain shift. These findings establish instance density as an intrinsic, quantifiable dimension of data hardness and motivate specific interventions in curriculum learning and density-stratified evaluation.
Risk-Calibrated Learning: Minimizing Fatal Errors in Medical AI
Apr 14, 2026Deep learning models often achieve expert-level accuracy in medical image classification but suffer from a critical flaw: semantic incoherence. These high-confidence mistakes that are semantically incoherent (e.g., classifying a malignant tumor as benign) fundamentally differ from acceptable errors which stem from visual ambiguity. Unlike safe, fine-grained disagreements, these fatal failures erode clinical trust. To address this, we propose Risk-Calibrated Learning, a technique that explicitly distinguishes between visual ambiguity (fine-grained errors) and catastrophic structural errors. By embedding a confusion-aware clinical severity matrix M into the optimization landscape, our method suppresses critical errors (false negatives) without requiring complex architectural changes. We validate our approach in four different imaging modalities: Brain Tumor MRI, ISIC 2018 (Dermoscopy), BreaKHis (Breast Histopathology), and SICAPv2 (Prostate Histopathology). Extensive experiments demonstrate that our Risk-Calibrated Loss consistently reduces the Critical Error Rate (CER) for all four datasets, achieving relative safety improvements ranging from 20.0% (on breast histopathology) to 92.4% (on prostate histopathology) compared to state-of-the-art baselines such as Focal Loss. These results confirm that our method offers a superior safety-accuracy trade-off across both CNN and Transformer architectures.
Graph-Linguistic Fusion: Using Language Models for Wikidata Vandalism Detection
May 23, 2025


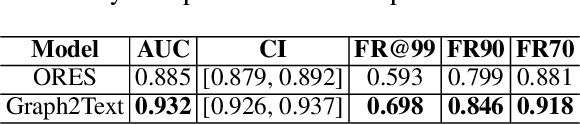
We introduce a next-generation vandalism detection system for Wikidata, one of the largest open-source structured knowledge bases on the Web. Wikidata is highly complex: its items incorporate an ever-expanding universe of factual triples and multilingual texts. While edits can alter both structured and textual content, our approach converts all edits into a single space using a method we call Graph2Text. This allows for evaluating all content changes for potential vandalism using a single multilingual language model. This unified approach improves coverage and simplifies maintenance. Experiments demonstrate that our solution outperforms the current production system. Additionally, we are releasing the code under an open license along with a large dataset of various human-generated knowledge alterations, enabling further research.
Characterizing Knowledge Manipulation in a Russian Wikipedia Fork
Apr 14, 2025Wikipedia is powered by MediaWiki, a free and open-source software that is also the infrastructure for many other wiki-based online encyclopedias. These include the recently launched website Ruwiki, which has copied and modified the original Russian Wikipedia content to conform to Russian law. To identify practices and narratives that could be associated with different forms of knowledge manipulation, this article presents an in-depth analysis of this Russian Wikipedia fork. We propose a methodology to characterize the main changes with respect to the original version. The foundation of this study is a comprehensive comparative analysis of more than 1.9M articles from Russian Wikipedia and its fork. Using meta-information and geographical, temporal, categorical, and textual features, we explore the changes made by Ruwiki editors. Furthermore, we present a classification of the main topics of knowledge manipulation in this fork, including a numerical estimation of their scope. This research not only sheds light on significant changes within Ruwiki, but also provides a methodology that could be applied to analyze other Wikipedia forks and similar collaborative projects.
A Principled Approach for a New Bias Measure
May 20, 2024



The widespread use of machine learning and data-driven algorithms for decision making has been steadily increasing over many years. The areas in which this is happening are diverse: healthcare, employment, finance, education, the legal system to name a few; and the associated negative side effects are being increasingly harmful for society. Negative data \emph{bias} is one of those, which tends to result in harmful consequences for specific groups of people. Any mitigation strategy or effective policy that addresses the negative consequences of bias must start with awareness that bias exists, together with a way to understand and quantify it. However, there is a lack of consensus on how to measure data bias and oftentimes the intended meaning is context dependent and not uniform within the research community. The main contributions of our work are: (1) a general algorithmic framework for defining and efficiently quantifying the bias level of a dataset with respect to a protected group; and (2) the definition of a new bias measure. Our results are experimentally validated using nine publicly available datasets and theoretically analyzed, which provide novel insights about the problem. Based on our approach, we also derive a bias mitigation algorithm that might be useful to policymakers.
Social AI and the Challenges of the Human-AI Ecosystem
Jun 23, 2023


The rise of large-scale socio-technical systems in which humans interact with artificial intelligence (AI) systems (including assistants and recommenders, in short AIs) multiplies the opportunity for the emergence of collective phenomena and tipping points, with unexpected, possibly unintended, consequences. For example, navigation systems' suggestions may create chaos if too many drivers are directed on the same route, and personalised recommendations on social media may amplify polarisation, filter bubbles, and radicalisation. On the other hand, we may learn how to foster the "wisdom of crowds" and collective action effects to face social and environmental challenges. In order to understand the impact of AI on socio-technical systems and design next-generation AIs that team with humans to help overcome societal problems rather than exacerbate them, we propose to build the foundations of Social AI at the intersection of Complex Systems, Network Science and AI. In this perspective paper, we discuss the main open questions in Social AI, outlining possible technical and scientific challenges and suggesting research avenues.
Fair multilingual vandalism detection system for Wikipedia
Jun 02, 2023



This paper presents a novel design of the system aimed at supporting the Wikipedia community in addressing vandalism on the platform. To achieve this, we collected a massive dataset of 47 languages, and applied advanced filtering and feature engineering techniques, including multilingual masked language modeling to build the training dataset from human-generated data. The performance of the system was evaluated through comparison with the one used in production in Wikipedia, known as ORES. Our research results in a significant increase in the number of languages covered, making Wikipedia patrolling more efficient to a wider range of communities. Furthermore, our model outperforms ORES, ensuring that the results provided are not only more accurate but also less biased against certain groups of contributors.
Uncovering Bias in Personal Informatics
Mar 27, 2023Personal informatics (PI) systems, powered by smartphones and wearables, enable people to lead healthier lifestyles by providing meaningful and actionable insights that break down barriers between users and their health information. Today, such systems are used by billions of users for monitoring not only physical activity and sleep but also vital signs and women's and heart health, among others. %Despite their widespread usage, the processing of particularly sensitive personal data, and their proximity to domains known to be susceptible to bias, such as healthcare, bias in PI has not been investigated systematically. Despite their widespread usage, the processing of sensitive PI data may suffer from biases, which may entail practical and ethical implications. In this work, we present the first comprehensive empirical and analytical study of bias in PI systems, including biases in raw data and in the entire machine learning life cycle. We use the most detailed framework to date for exploring the different sources of bias and find that biases exist both in the data generation and the model learning and implementation streams. According to our results, the most affected minority groups are users with health issues, such as diabetes, joint issues, and hypertension, and female users, whose data biases are propagated or even amplified by learning models, while intersectional biases can also be observed.
Human-Centered Responsible Artificial Intelligence: Current & Future Trends
Feb 16, 2023
In recent years, the CHI community has seen significant growth in research on Human-Centered Responsible Artificial Intelligence. While different research communities may use different terminology to discuss similar topics, all of this work is ultimately aimed at developing AI that benefits humanity while being grounded in human rights and ethics, and reducing the potential harms of AI. In this special interest group, we aim to bring together researchers from academia and industry interested in these topics to map current and future research trends to advance this important area of research by fostering collaboration and sharing ideas.