 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo-Grounding for Personalized Question-Answering in Egocentric Videos
Apr 02, 2026We present the first systematic analysis of multimodal large language models (MLLMs) in personalized question-answering requiring ego-grounding - the ability to understand the camera-wearer in egocentric videos. To this end, we introduce MyEgo, the first egocentric VideoQA dataset designed to evaluate MLLMs' ability to understand, remember, and reason about the camera wearer. MyEgo comprises 541 long videos and 5K personalized questions asking about "my things", "my activities", and "my past". Benchmarking reveals that competitive MLLMs across variants, including open-source vs. proprietary, thinking vs. non-thinking, small vs. large scales all struggle on MyEgo. Top closed- and open-source models (e.g., GPT-5 and Qwen3-VL) achieve only~46% and 36% accuracy, trailing human performance by near 40% and 50% respectively. Surprisingly, neither explicit reasoning nor model scaling yield consistent improvements. Models improve when relevant evidence is explicitly provided, but gains drop over time, indicating limitations in tracking and remembering "me" and "my past". These findings collectively highlight the crucial role of ego-grounding and long-range memory in enabling personalized QA in egocentric videos. We hope MyEgo and our analyses catalyze further progress in these areas for egocentric personalized assistance. Data and code are available at https://github.com/Ryougetsu3606/MyEgo
MiroEval: Benchmarking Multimodal Deep Research Agents in Process and Outcome
Mar 30, 2026Recent progress in deep research systems has been impressive, but evaluation still lags behind real user needs. Existing benchmarks predominantly assess final reports using fixed rubrics, failing to evaluate the underlying research process. Most also offer limited multimodal coverage, rely on synthetic tasks that do not reflect real-world query complexity, and cannot be refreshed as knowledge evolves. To address these gaps, we introduce MiroEval, a benchmark and evaluation framework for deep research systems. The benchmark comprises 100 tasks (70 text-only, 30 multimodal), all grounded in real user needs and constructed via a dual-path pipeline that supports periodic updates, enabling a live and evolving setting. The proposed evaluation suite assesses deep research systems along three complementary dimensions: adaptive synthesis quality evaluation with task-specific rubrics, agentic factuality verification via active retrieval and reasoning over both web sources and multimodal attachments, and process-centric evaluation audits how the system searches, reasons, and refines throughout its investigation. Evaluation across 13 systems yields three principal findings: the three evaluation dimensions capture complementary aspects of system capability, with each revealing distinct strengths and weaknesses across systems; process quality serves as a reliable predictor of overall outcome while revealing weaknesses invisible to output-level metrics; and multimodal tasks pose substantially greater challenges, with most systems declining by 3 to 10 points. The MiroThinker series achieves the most balanced performance, with MiroThinker-H1 ranking the highest overall in both settings. Human verification and robustness results confirm the reliability of the benchmark and evaluation framework. MiroEval provides a holistic diagnostic tool for the next generation of deep research agents.
MiroFlow: Towards High-Performance and Robust Open-Source Agent Framework for General Deep Research Tasks
Feb 26, 2026Despite the remarkable progress of large language models (LLMs), the capabilities of standalone LLMs have begun to plateau when tackling real-world, complex tasks that require interaction with external tools and dynamic environments. Although recent agent frameworks aim to enhance model autonomy through tool integration and external interaction, they still suffer from naive workflows, unstable performance, limited support across diverse benchmarks and tasks, and heavy reliance on costly commercial APIs. In this work, we propose a high-performance and robust open-source agent framework, termed MiroFlow, which incorporates an agent graph for flexible orchestration, an optional deep reasoning mode to enhance performance, and a robust workflow execution to ensure stable and reproducible performance. Extensive experiments demonstrate that MiroFlow consistently achieves state-of-the-art performance across multiple agent benchmarks, including GAIA, BrowseComp-EN/ZH, HLE, xBench-DeepSearch, and notably FutureX. We hope it could serve as an easily accessible, reproducible, and comparable baseline for the deep research community.
NeRF-VIO: Map-Based Visual-Inertial Odometry with Initialization Leveraging Neural Radiance Fields
Mar 11, 2025A prior map serves as a foundational reference for localization in context-aware applications such as augmented reality (AR). Providing valuable contextual information about the environment, the prior map is a vital tool for mitigating drift. In this paper, we propose a map-based visual-inertial localization algorithm (NeRF-VIO) with initialization using neural radiance fields (NeRF). Our algorithm utilizes a multilayer perceptron model and redefines the loss function as the geodesic distance on \(SE(3)\), ensuring the invariance of the initialization model under a frame change within \(\mathfrak{se}(3)\). The evaluation demonstrates that our model outperforms existing NeRF-based initialization solution in both accuracy and efficiency. By integrating a two-stage update mechanism within a multi-state constraint Kalman filter (MSCKF) framework, the state of NeRF-VIO is constrained by both captured images from an onboard camera and rendered images from a pre-trained NeRF model. The proposed algorithm is validated using a real-world AR dataset, the results indicate that our two-stage update pipeline outperforms MSCKF across all data sequences.
Multi-view Hand Reconstruction with a Point-Embedded Transformer
Aug 20, 2024



This work introduces a novel and generalizable multi-view Hand Mesh Reconstruction (HMR) model, named POEM, designed for practical use in real-world hand motion capture scenarios. The advances of the POEM model consist of two main aspects. First, concerning the modeling of the problem, we propose embedding a static basis point within the multi-view stereo space. A point represents a natural form of 3D information and serves as an ideal medium for fusing features across different views, given its varied projections across these views. Consequently, our method harnesses a simple yet effective idea: a complex 3D hand mesh can be represented by a set of 3D basis points that 1) are embedded in the multi-view stereo, 2) carry features from the multi-view images, and 3) encompass the hand in it. The second advance lies in the training strategy. We utilize a combination of five large-scale multi-view datasets and employ randomization in the number, order, and poses of the cameras. By processing such a vast amount of data and a diverse array of camera configurations, our model demonstrates notable generalizability in the real-world applications. As a result, POEM presents a highly practical, plug-and-play solution that enables user-friendly, cost-effective multi-view motion capture for both left and right hands. The model and source codes are available at https://github.com/JubSteven/POEM-v2.
Distributed Invariant Kalman Filter for Cooperative Localization using Matrix Lie Groups
May 07, 2024



This paper studies the problem of Cooperative Localization (CL) for multi-robot systems, where a group of mobile robots jointly localize themselves by using measurements from onboard sensors and shared information from other robots. We propose a novel distributed invariant Kalman Filter (DInEKF) based on the Lie group theory, to solve the CL problem in a 3-D environment. Unlike the standard EKF which computes the Jacobians based on the linearization at the state estimate, DInEKF defines the robots' motion model on matrix Lie groups and offers the advantage of state estimate-independent Jacobians. This significantly improves the consistency of the estimator. Moreover, the proposed algorithm is fully distributed, relying solely on each robot's ego-motion measurements and information received from its one-hop communication neighbors. The effectiveness of the proposed algorithm is validated in both Monte-Carlo simulations and real-world experiments. The results show that the proposed DInEKF outperforms the standard distributed EKF in terms of both accuracy and consistency.
PL-CVIO: Point-Line Cooperative Visual-Inertial Odometry
Nov 09, 2023



Low-feature environments are one of the main Achilles' heels of geometric computer vision (CV) algorithms. In most human-built scenes often with low features, lines can be considered complements to points. In this paper, we present a multi-robot cooperative visual-inertial navigation system (VINS) using both point and line features. By utilizing the covariance intersection (CI) update within the multi-state constraint Kalman filter (MSCKF) framework, each robot exploits not only its own point and line measurements, but also constraints of common point and common line features observed by its neighbors. The line features are parameterized and updated by utilizing the Closest Point representation. The proposed algorithm is validated extensively in both Monte-Carlo simulations and a real-world dataset. The results show that the point-line cooperative visual-inertial odometry (PL-CVIO) outperforms the independent MSCKF and our previous work CVIO in both low-feature and rich-feature environments.
Distributed Visual-Inertial Cooperative Localization
Mar 23, 2021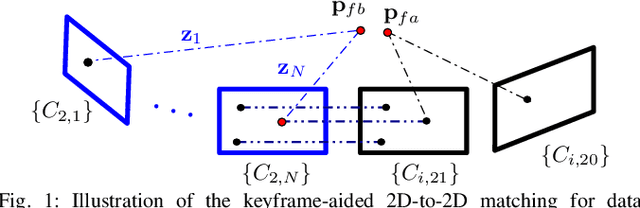
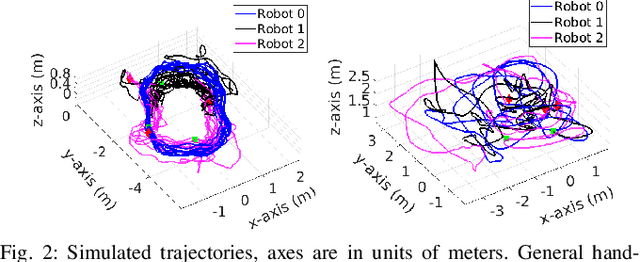
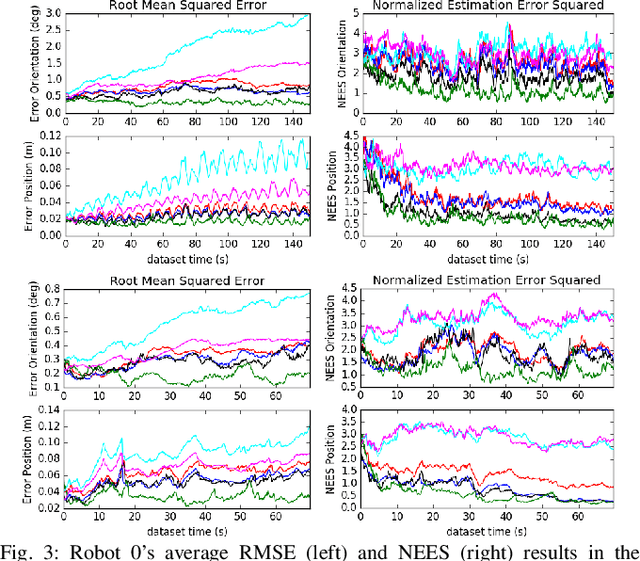
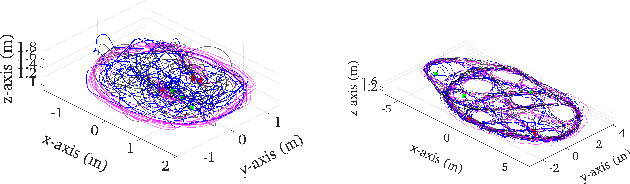
In this paper we present a consistent and distributed state estimator for multi-robot cooperative localization (CL) which efficiently fuses environmental features and loop-closure constraints across time and robots. In particular, we leverage covariance intersection (CI) to allow each robot to only track its own state and autocovariance and compensate for the unknown correlations between robots. Two novel different methods for utilizing common environmental temporal SLAM features are introduced and evaluated in terms of accuracy and efficiency. Moreover, we adapt CI to enable drift-free estimation through the use of loop-closure measurement constraints to other robots' historical poses without a significant increase in computational cost. The proposed distributed CL estimator is validated against its naive non-realtime centralized counterpart extensively in both simulations and real-world experiments.