 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLISA: Learning Implicit Shape and Appearance of Hands
Apr 04, 2022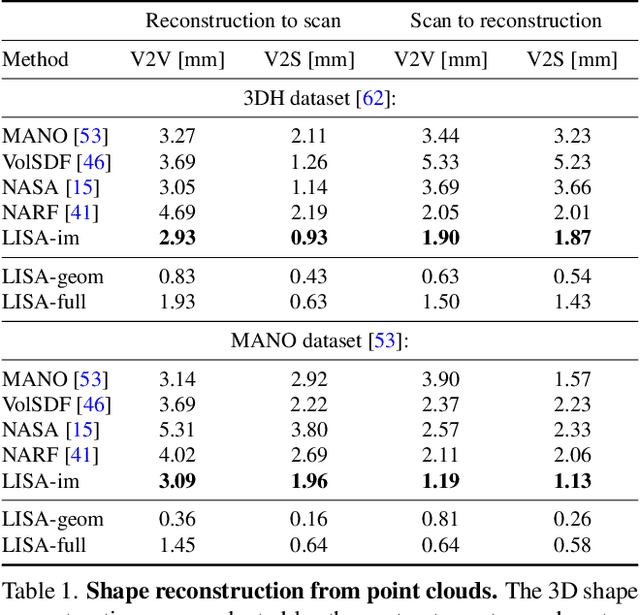
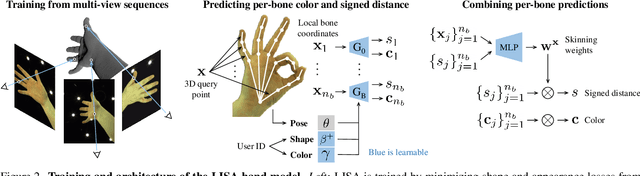
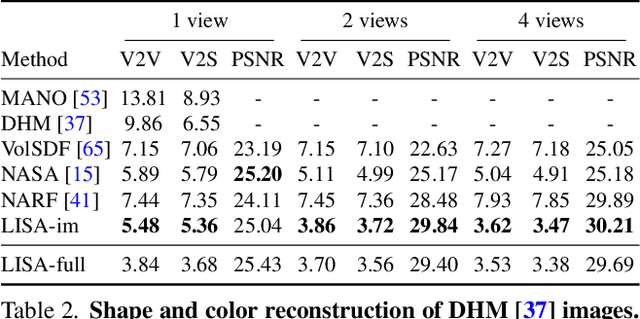
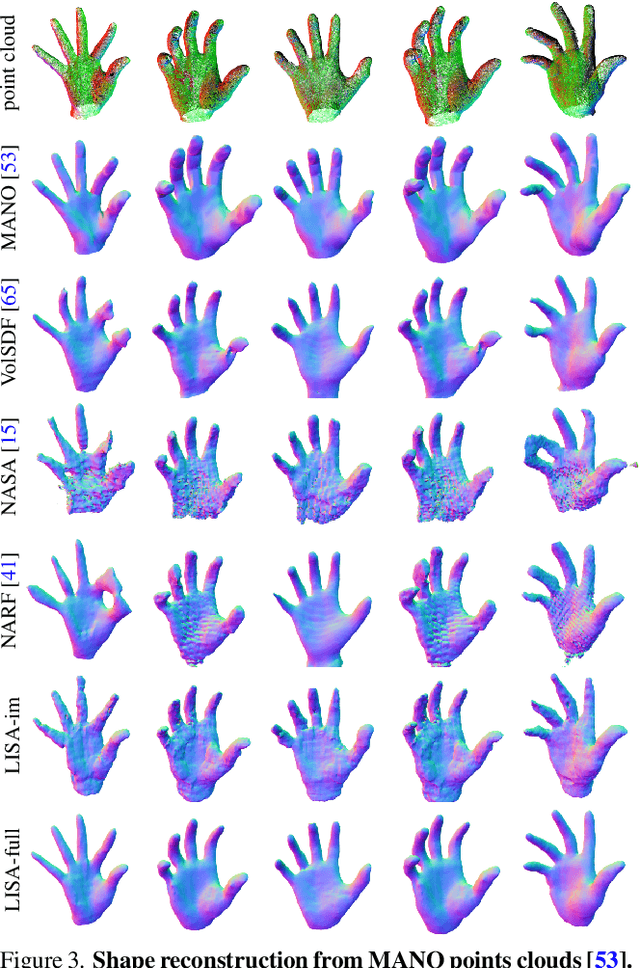
This paper proposes a do-it-all neural model of human hands, named LISA. The model can capture accurate hand shape and appearance, generalize to arbitrary hand subjects, provide dense surface correspondences, be reconstructed from images in the wild and easily animated. We train LISA by minimizing the shape and appearance losses on a large set of multi-view RGB image sequences annotated with coarse 3D poses of the hand skeleton. For a 3D point in the hand local coordinate, our model predicts the color and the signed distance with respect to each hand bone independently, and then combines the per-bone predictions using predicted skinning weights. The shape, color and pose representations are disentangled by design, allowing to estimate or animate only selected parameters. We experimentally demonstrate that LISA can accurately reconstruct a dynamic hand from monocular or multi-view sequences, achieving a noticeably higher quality of reconstructed hand shapes compared to baseline approaches. Project page: https://www.iri.upc.edu/people/ecorona/lisa/.
Identity-Disentangled Neural Deformation Model for Dynamic Meshes
Oct 04, 2021


Neural shape models can represent complex 3D shapes with a compact latent space. When applied to dynamically deforming shapes such as the human hands, however, they would need to preserve temporal coherence of the deformation as well as the intrinsic identity of the subject. These properties are difficult to regularize with manually designed loss functions. In this paper, we learn a neural deformation model that disentangles the identity-induced shape variations from pose-dependent deformations using implicit neural functions. We perform template-free unsupervised learning on 3D scans without explicit mesh correspondence or semantic correspondences of shapes across subjects. We can then apply the learned model to reconstruct partial dynamic 4D scans of novel subjects performing unseen actions. We propose two methods to integrate global pose alignment with our neural deformation model. Experiments demonstrate the efficacy of our method in the disentanglement of identities and pose. Our method also outperforms traditional skeleton-driven models in reconstructing surface details such as palm prints or tendons without limitations from a fixed template.
Egocentric Activity Recognition and Localization on a 3D Map
May 27, 2021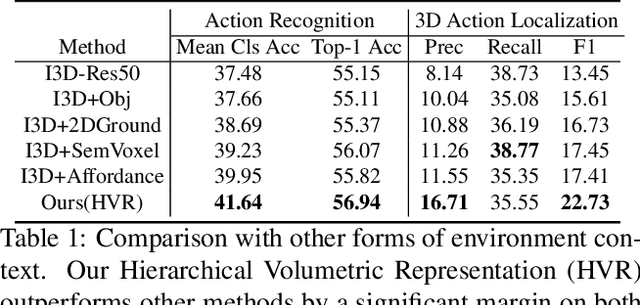
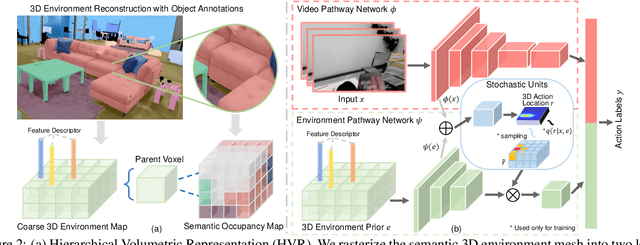
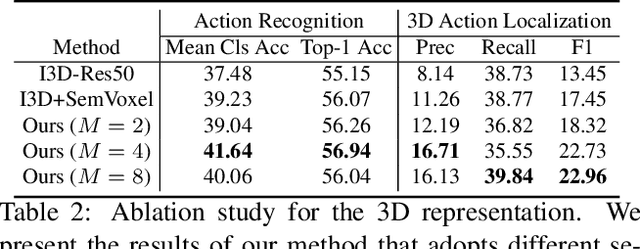
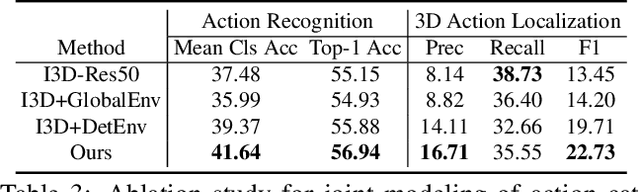
Given a video captured from a first person perspective and recorded in a familiar environment, can we recognize what the person is doing and identify where the action occurs in the 3D space? We address this challenging problem of jointly recognizing and localizing actions of a mobile user on a known 3D map from egocentric videos. To this end, we propose a novel deep probabilistic model. Our model takes the inputs of a Hierarchical Volumetric Representation (HVR) of the environment and an egocentric video, infers the 3D action location as a latent variable, and recognizes the action based on the video and contextual cues surrounding its potential locations. To evaluate our model, we conduct extensive experiments on a newly collected egocentric video dataset, in which both human naturalistic actions and photo-realistic 3D environment reconstructions are captured. Our method demonstrates strong results on both action recognition and 3D action localization across seen and unseen environments. We believe our work points to an exciting research direction in the intersection of egocentric vision, and 3D scene understanding.
FroDO: From Detections to 3D Objects
May 11, 2020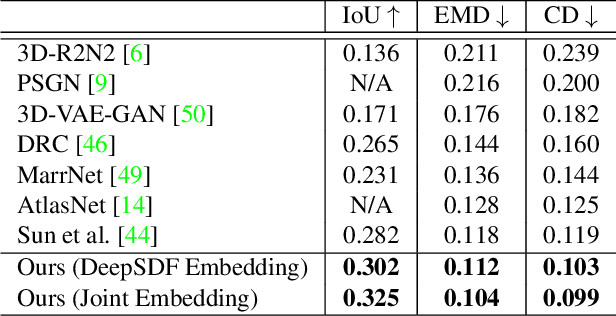


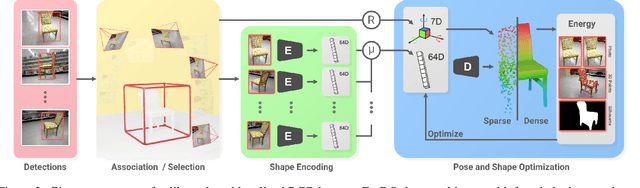
Object-oriented maps are important for scene understanding since they jointly capture geometry and semantics, allow individual instantiation and meaningful reasoning about objects. We introduce FroDO, a method for accurate 3D reconstruction of object instances from RGB video that infers object location, pose and shape in a coarse-to-fine manner. Key to FroDO is to embed object shapes in a novel learnt space that allows seamless switching between sparse point cloud and dense DeepSDF decoding. Given an input sequence of localized RGB frames, FroDO first aggregates 2D detections to instantiate a category-aware 3D bounding box per object. A shape code is regressed using an encoder network before optimizing shape and pose further under the learnt shape priors using sparse and dense shape representations. The optimization uses multi-view geometric, photometric and silhouette losses. We evaluate on real-world datasets, including Pix3D, Redwood-OS, and ScanNet, for single-view, multi-view, and multi-object reconstruction.
The Replica Dataset: A Digital Replica of Indoor Spaces
Jun 13, 2019


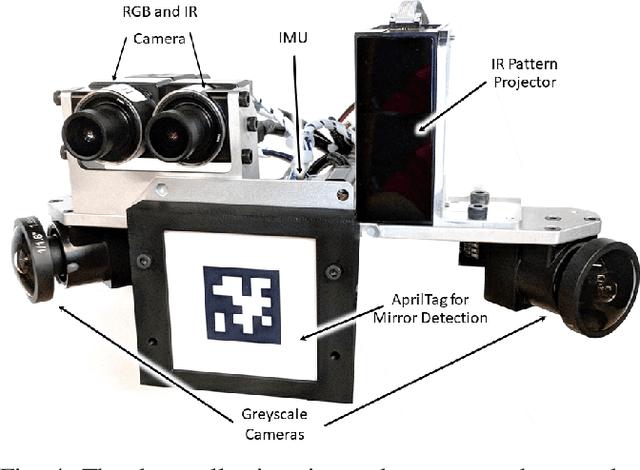
We introduce Replica, a dataset of 18 highly photo-realistic 3D indoor scene reconstructions at room and building scale. Each scene consists of a dense mesh, high-resolution high-dynamic-range (HDR) textures, per-primitive semantic class and instance information, and planar mirror and glass reflectors. The goal of Replica is to enable machine learning (ML) research that relies on visually, geometrically, and semantically realistic generative models of the world - for instance, egocentric computer vision, semantic segmentation in 2D and 3D, geometric inference, and the development of embodied agents (virtual robots) performing navigation, instruction following, and question answering. Due to the high level of realism of the renderings from Replica, there is hope that ML systems trained on Replica may transfer directly to real world image and video data. Together with the data, we are releasing a minimal C++ SDK as a starting point for working with the Replica dataset. In addition, Replica is `Habitat-compatible', i.e. can be natively used with AI Habitat for training and testing embodied agents.
Detailed Dense Inference with Convolutional Neural Networks via Discrete Wavelet Transform
Aug 06, 2018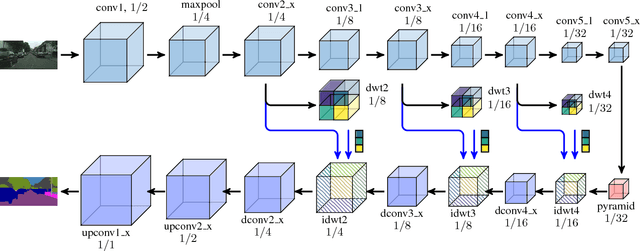
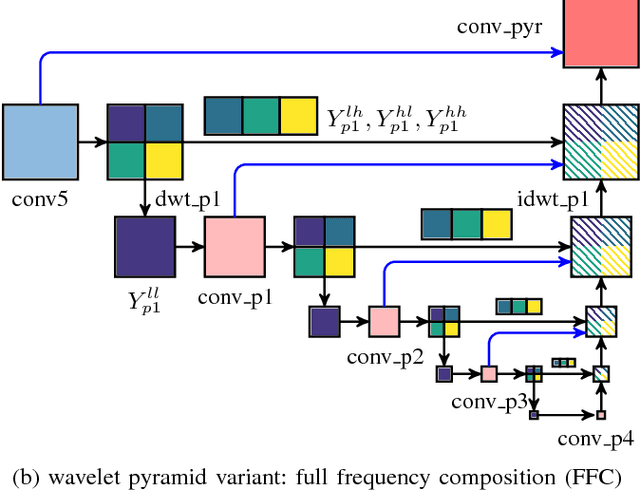

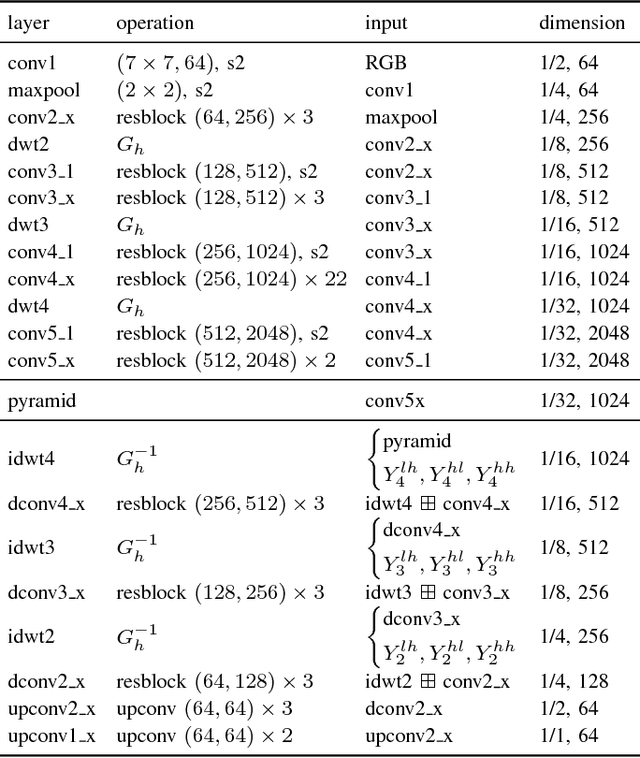
Dense pixelwise prediction such as semantic segmentation is an up-to-date challenge for deep convolutional neural networks (CNNs). Many state-of-the-art approaches either tackle the loss of high-resolution information due to pooling in the encoder stage, or use dilated convolutions or high-resolution lanes to maintain detailed feature maps and predictions. Motivated by the structural analogy between multi-resolution wavelet analysis and the pooling/unpooling layers of CNNs, we introduce discrete wavelet transform (DWT) into the CNN encoder-decoder architecture and propose WCNN. The high-frequency wavelet coefficients are computed at encoder, which are later used at the decoder to unpooled jointly with coarse-resolution feature maps through the inverse DWT. The DWT/iDWT is further used to develop two wavelet pyramids to capture the global context, where the multi-resolution DWT is applied to successively reduce the spatial resolution and increase the receptive field. Experiment with the Cityscape dataset, the proposed WCNNs are computationally efficient and yield improvements the accuracy for high-resolution dense pixelwise prediction.
Multi-View Deep Learning for Consistent Semantic Mapping with RGB-D Cameras
Dec 04, 2017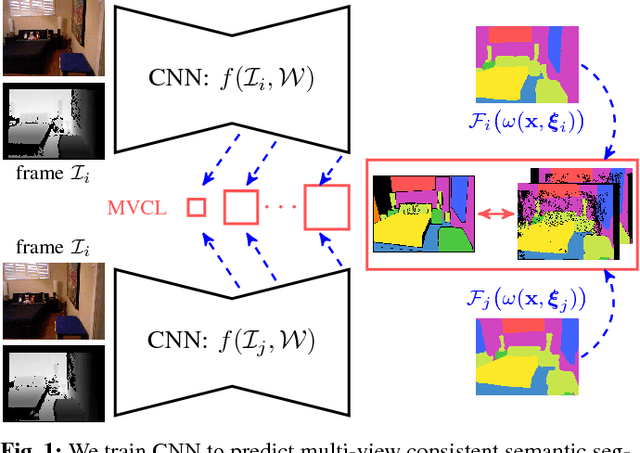
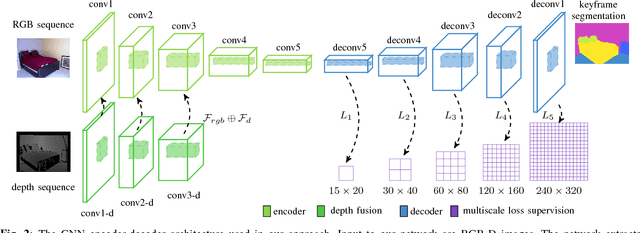

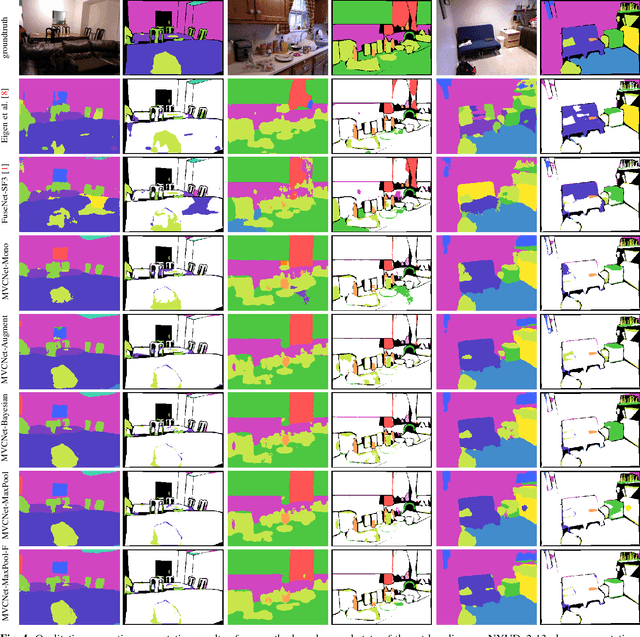
Visual scene understanding is an important capability that enables robots to purposefully act in their environment. In this paper, we propose a novel approach to object-class segmentation from multiple RGB-D views using deep learning. We train a deep neural network to predict object-class semantics that is consistent from several view points in a semi-supervised way. At test time, the semantics predictions of our network can be fused more consistently in semantic keyframe maps than predictions of a network trained on individual views. We base our network architecture on a recent single-view deep learning approach to RGB and depth fusion for semantic object-class segmentation and enhance it with multi-scale loss minimization. We obtain the camera trajectory using RGB-D SLAM and warp the predictions of RGB-D images into ground-truth annotated frames in order to enforce multi-view consistency during training. At test time, predictions from multiple views are fused into keyframes. We propose and analyze several methods for enforcing multi-view consistency during training and testing. We evaluate the benefit of multi-view consistency training and demonstrate that pooling of deep features and fusion over multiple views outperforms single-view baselines on the NYUDv2 benchmark for semantic segmentation. Our end-to-end trained network achieves state-of-the-art performance on the NYUDv2 dataset in single-view segmentation as well as multi-view semantic fusion.
De-noising, Stabilizing and Completing 3D Reconstructions On-the-go using Plane Priors
Mar 28, 2017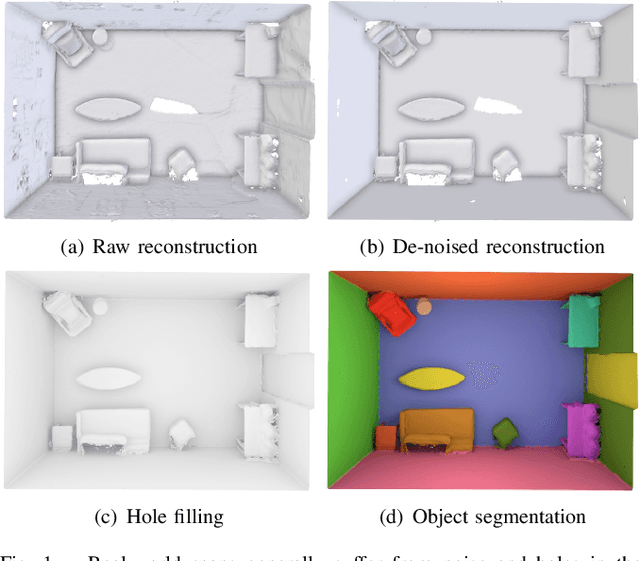
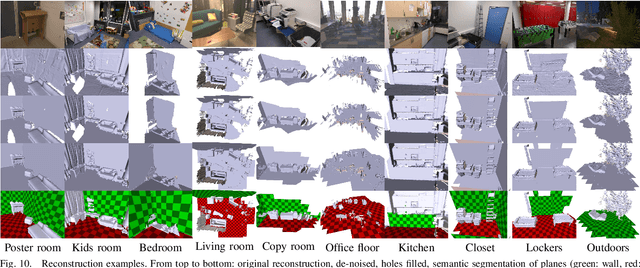

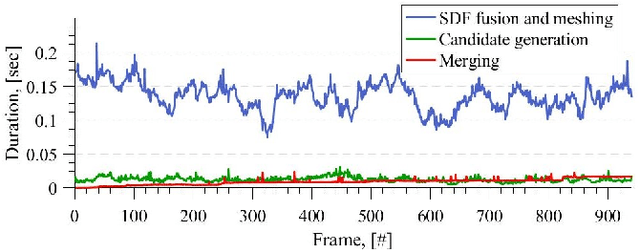
Creating 3D maps on robots and other mobile devices has become a reality in recent years. Online 3D reconstruction enables many exciting applications in robotics and AR/VR gaming. However, the reconstructions are noisy and generally incomplete. Moreover, during onine reconstruction, the surface changes with every newly integrated depth image which poses a significant challenge for physics engines and path planning algorithms. This paper presents a novel, fast and robust method for obtaining and using information about planar surfaces, such as walls, floors, and ceilings as a stage in 3D reconstruction based on Signed Distance Fields. Our algorithm recovers clean and accurate surfaces, reduces the movement of individual mesh vertices caused by noise during online reconstruction and fills in the occluded and unobserved regions. We implemented and evaluated two different strategies to generate plane candidates and two strategies for merging them. Our implementation is optimized to run in real-time on mobile devices such as the Tango tablet. In an extensive set of experiments, we validated that our approach works well in a large number of natural environments despite the presence of significant amount of occlusion, clutter and noise, which occur frequently. We further show that plane fitting enables in many cases a meaningful semantic segmentation of real-world scenes.