 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNymeriaPlus: Enriching Nymeria Dataset with Additional Annotations and Data
Mar 19, 2026The Nymeria Dataset, released in 2024, is a large-scale collection of in-the-wild human activities captured with multiple egocentric wearable devices that are spatially localized and temporally synchronized. It provides body-motion ground truth recorded with a motion-capture suit, device trajectories, semi-dense 3D point clouds, and in-context narrations. In this paper, we upgrade Nymeria and introduce NymeriaPlus. NymeriaPlus features: (1) improved human motion in Momentum Human Rig (MHR) and SMPL formats; (2) dense 3D and 2D bounding box annotations for indoor objects and structural elements; (3) instance-level 3D object reconstructions; and (4) additional modalities e.g., basemap recordings, audio, and wristband videos. By consolidating these complementary modalities and annotations into a single, coherent benchmark, NymeriaPlus strengthens Nymeria into a more powerful in-the-wild egocentric dataset. We expect NymeriaPlus to bridge a key gap in existing egocentric resources and to support a broader range of research, including unique explorations of multimodal learning for embodied AI.
Dancing Points: Synthesizing Ballroom Dancing with Three-Point Inputs
Jan 05, 2026Ballroom dancing is a structured yet expressive motion category. Its highly diverse movement and complex interactions between leader and follower dancers make the understanding and synthesis challenging. We demonstrate that the three-point trajectory available from a virtual reality (VR) device can effectively serve as a dancer's motion descriptor, simplifying the modeling and synthesis of interplay between dancers' full-body motions down to sparse trajectories. Thanks to the low dimensionality, we can employ an efficient MLP network to predict the follower's three-point trajectory directly from the leader's three-point input for certain types of ballroom dancing, addressing the challenge of modeling high-dimensional full-body interaction. It also prevents our method from overfitting thanks to its compact yet explicit representation. By leveraging the inherent structure of the movements and carefully planning the autoregressive procedure, we show a deterministic neural network is able to translate three-point trajectories into a virtual embodied avatar, which is typically considered under-constrained and requires generative models for common motions. In addition, we demonstrate this deterministic approach generalizes beyond small, structured datasets like ballroom dancing, and performs robustly on larger, more diverse datasets such as LaFAN. Our method provides a computationally- and data-efficient solution, opening new possibilities for immersive paired dancing applications. Code and pre-trained models for this paper are available at https://peizhuoli.github.io/dancing-points.
MHR: Momentum Human Rig
Nov 19, 2025We present MHR, a parametric human body model that combines the decoupled skeleton/shape paradigm of ATLAS with a flexible, modern rig and pose corrective system inspired by the Momentum library. Our model enables expressive, anatomically plausible human animation, supporting non-linear pose correctives, and is designed for robust integration in AR/VR and graphics pipelines.
From Sparse Signal to Smooth Motion: Real-Time Motion Generation with Rolling Prediction Models
Apr 07, 2025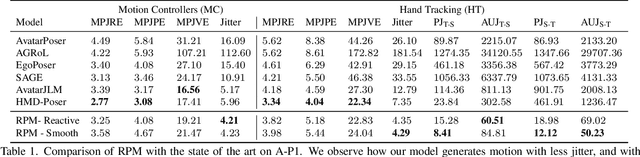

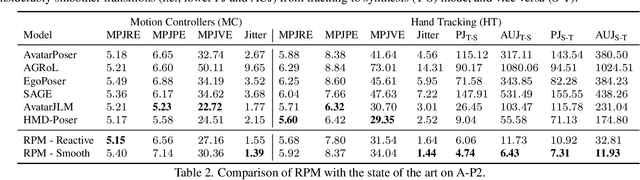

In extended reality (XR), generating full-body motion of the users is important to understand their actions, drive their virtual avatars for social interaction, and convey a realistic sense of presence. While prior works focused on spatially sparse and always-on input signals from motion controllers, many XR applications opt for vision-based hand tracking for reduced user friction and better immersion. Compared to controllers, hand tracking signals are less accurate and can even be missing for an extended period of time. To handle such unreliable inputs, we present Rolling Prediction Model (RPM), an online and real-time approach that generates smooth full-body motion from temporally and spatially sparse input signals. Our model generates 1) accurate motion that matches the inputs (i.e., tracking mode) and 2) plausible motion when inputs are missing (i.e., synthesis mode). More importantly, RPM generates seamless transitions from tracking to synthesis, and vice versa. To demonstrate the practical importance of handling noisy and missing inputs, we present GORP, the first dataset of realistic sparse inputs from a commercial virtual reality (VR) headset with paired high quality body motion ground truth. GORP provides >14 hours of VR gameplay data from 28 people using motion controllers (spatially sparse) and hand tracking (spatially and temporally sparse). We benchmark RPM against the state of the art on both synthetic data and GORP to highlight how we can bridge the gap for real-world applications with a realistic dataset and by handling unreliable input signals. Our code, pretrained models, and GORP dataset are available in the project webpage.
CHOICE: Coordinated Human-Object Interaction in Cluttered Environments for Pick-and-Place Actions
Dec 09, 2024



Animating human-scene interactions such as pick-and-place tasks in cluttered, complex layouts is a challenging task, with objects of a wide variation of geometries and articulation under scenarios with various obstacles. The main difficulty lies in the sparsity of the motion data compared to the wide variation of the objects and environments as well as the poor availability of transition motions between different tasks, increasing the complexity of the generalization to arbitrary conditions. To cope with this issue, we develop a system that tackles the interaction synthesis problem as a hierarchical goal-driven task. Firstly, we develop a bimanual scheduler that plans a set of keyframes for simultaneously controlling the two hands to efficiently achieve the pick-and-place task from an abstract goal signal such as the target object selected by the user. Next, we develop a neural implicit planner that generates guidance hand trajectories under diverse object shape/types and obstacle layouts. Finally, we propose a linear dynamic model for our DeepPhase controller that incorporates a Kalman filter to enable smooth transitions in the frequency domain, resulting in a more realistic and effective multi-objective control of the character.Our system can produce a wide range of natural pick-and-place movements with respect to the geometry of objects, the articulation of containers and the layout of the objects in the scene.
EgoLM: Multi-Modal Language Model of Egocentric Motions
Sep 26, 2024



As the prevalence of wearable devices, learning egocentric motions becomes essential to develop contextual AI. In this work, we present EgoLM, a versatile framework that tracks and understands egocentric motions from multi-modal inputs, e.g., egocentric videos and motion sensors. EgoLM exploits rich contexts for the disambiguation of egomotion tracking and understanding, which are ill-posed under single modality conditions. To facilitate the versatile and multi-modal framework, our key insight is to model the joint distribution of egocentric motions and natural languages using large language models (LLM). Multi-modal sensor inputs are encoded and projected to the joint latent space of language models, and used to prompt motion generation or text generation for egomotion tracking or understanding, respectively. Extensive experiments on large-scale multi-modal human motion dataset validate the effectiveness of EgoLM as a generalist model for universal egocentric learning.
Nymeria: A Massive Collection of Multimodal Egocentric Daily Motion in the Wild
Jun 14, 2024We introduce Nymeria - a large-scale, diverse, richly annotated human motion dataset collected in the wild with multiple multimodal egocentric devices. The dataset comes with a) full-body 3D motion ground truth; b) egocentric multimodal recordings from Project Aria devices with RGB, grayscale, eye-tracking cameras, IMUs, magnetometer, barometer, and microphones; and c) an additional "observer" device providing a third-person viewpoint. We compute world-aligned 6DoF transformations for all sensors, across devices and capture sessions. The dataset also provides 3D scene point clouds and calibrated gaze estimation. We derive a protocol to annotate hierarchical language descriptions of in-context human motion, from fine-grain pose narrations, to atomic actions and activity summarization. To the best of our knowledge, the Nymeria dataset is the world largest in-the-wild collection of human motion with natural and diverse activities; first of its kind to provide synchronized and localized multi-device multimodal egocentric data; and the world largest dataset with motion-language descriptions. It contains 1200 recordings of 300 hours of daily activities from 264 participants across 50 locations, travelling a total of 399Km. The motion-language descriptions provide 310.5K sentences in 8.64M words from a vocabulary size of 6545. To demonstrate the potential of the dataset we define key research tasks for egocentric body tracking, motion synthesis, and action recognition and evaluate several state-of-the-art baseline algorithms. Data and code will be open-sourced.
DivaTrack: Diverse Bodies and Motions from Acceleration-Enhanced Three-Point Trackers
Feb 14, 2024Full-body avatar presence is crucial for immersive social and environmental interactions in digital reality. However, current devices only provide three six degrees of freedom (DOF) poses from the headset and two controllers (i.e. three-point trackers). Because it is a highly under-constrained problem, inferring full-body pose from these inputs is challenging, especially when supporting the full range of body proportions and use cases represented by the general population. In this paper, we propose a deep learning framework, DivaTrack, which outperforms existing methods when applied to diverse body sizes and activities. We augment the sparse three-point inputs with linear accelerations from Inertial Measurement Units (IMU) to improve foot contact prediction. We then condition the otherwise ambiguous lower-body pose with the predictions of foot contact and upper-body pose in a two-stage model. We further stabilize the inferred full-body pose in a wide range of configurations by learning to blend predictions that are computed in two reference frames, each of which is designed for different types of motions. We demonstrate the effectiveness of our design on a large dataset that captures 22 subjects performing challenging locomotion for three-point tracking, including lunges, hula-hooping, and sitting. As shown in a live demo using the Meta VR headset and Xsens IMUs, our method runs in real-time while accurately tracking a user's motion when they perform a diverse set of movements.
MOCHA: Real-Time Motion Characterization via Context Matching
Oct 16, 2023



Transforming neutral, characterless input motions to embody the distinct style of a notable character in real time is highly compelling for character animation. This paper introduces MOCHA, a novel online motion characterization framework that transfers both motion styles and body proportions from a target character to an input source motion. MOCHA begins by encoding the input motion into a motion feature that structures the body part topology and captures motion dependencies for effective characterization. Central to our framework is the Neural Context Matcher, which generates a motion feature for the target character with the most similar context to the input motion feature. The conditioned autoregressive model of the Neural Context Matcher can produce temporally coherent character features in each time frame. To generate the final characterized pose, our Characterizer network incorporates the characteristic aspects of the target motion feature into the input motion feature while preserving its context. This is achieved through a transformer model that introduces the adaptive instance normalization and context mapping-based cross-attention, effectively injecting the character feature into the source feature. We validate the performance of our framework through comparisons with prior work and an ablation study. Our framework can easily accommodate various applications, including characterization with only sparse input and real-time characterization. Additionally, we contribute a high-quality motion dataset comprising six different characters performing a range of motions, which can serve as a valuable resource for future research.
DROP: Dynamics Responses from Human Motion Prior and Projective Dynamics
Sep 24, 2023Synthesizing realistic human movements, dynamically responsive to the environment, is a long-standing objective in character animation, with applications in computer vision, sports, and healthcare, for motion prediction and data augmentation. Recent kinematics-based generative motion models offer impressive scalability in modeling extensive motion data, albeit without an interface to reason about and interact with physics. While simulator-in-the-loop learning approaches enable highly physically realistic behaviors, the challenges in training often affect scalability and adoption. We introduce DROP, a novel framework for modeling Dynamics Responses of humans using generative mOtion prior and Projective dynamics. DROP can be viewed as a highly stable, minimalist physics-based human simulator that interfaces with a kinematics-based generative motion prior. Utilizing projective dynamics, DROP allows flexible and simple integration of the learned motion prior as one of the projective energies, seamlessly incorporating control provided by the motion prior with Newtonian dynamics. Serving as a model-agnostic plug-in, DROP enables us to fully leverage recent advances in generative motion models for physics-based motion synthesis. We conduct extensive evaluations of our model across different motion tasks and various physical perturbations, demonstrating the scalability and diversity of responses.