 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMP: Continual Multimodal Pre-training for Vision Foundation Models
Mar 24, 2025Pre-trained Vision Foundation Models (VFMs) provide strong visual representations for a wide range of applications. In this paper, we continually pre-train prevailing VFMs in a multimodal manner such that they can effortlessly process visual inputs of varying sizes and produce visual representations that are more aligned with language representations, regardless of their original pre-training process. To this end, we introduce CoMP, a carefully designed multimodal pre-training pipeline. CoMP uses a Continual Rotary Position Embedding to support native resolution continual pre-training, and an Alignment Loss between visual and textual features through language prototypes to align multimodal representations. By three-stage training, our VFMs achieve remarkable improvements not only in multimodal understanding but also in other downstream tasks such as classification and segmentation. Remarkably, CoMP-SigLIP achieves scores of 66.7 on ChartQA and 75.9 on DocVQA with a 0.5B LLM, while maintaining an 87.4% accuracy on ImageNet-1K and a 49.5 mIoU on ADE20K under frozen chunk evaluation.
FOCUS: Towards Universal Foreground Segmentation
Jan 09, 2025



Foreground segmentation is a fundamental task in computer vision, encompassing various subdivision tasks. Previous research has typically designed task-specific architectures for each task, leading to a lack of unification. Moreover, they primarily focus on recognizing foreground objects without effectively distinguishing them from the background. In this paper, we emphasize the importance of the background and its relationship with the foreground. We introduce FOCUS, the Foreground ObjeCts Universal Segmentation framework that can handle multiple foreground tasks. We develop a multi-scale semantic network using the edge information of objects to enhance image features. To achieve boundary-aware segmentation, we propose a novel distillation method, integrating the contrastive learning strategy to refine the prediction mask in multi-modal feature space. We conduct extensive experiments on a total of 13 datasets across 5 tasks, and the results demonstrate that FOCUS consistently outperforms the state-of-the-art task-specific models on most metrics.
Comprehensive Multi-Modal Prototypes are Simple and Effective Classifiers for Vast-Vocabulary Object Detection
Dec 23, 2024



Enabling models to recognize vast open-world categories has been a longstanding pursuit in object detection. By leveraging the generalization capabilities of vision-language models, current open-world detectors can recognize a broader range of vocabularies, despite being trained on limited categories. However, when the scale of the category vocabularies during training expands to a real-world level, previous classifiers aligned with coarse class names significantly reduce the recognition performance of these detectors. In this paper, we introduce Prova, a multi-modal prototype classifier for vast-vocabulary object detection. Prova extracts comprehensive multi-modal prototypes as initialization of alignment classifiers to tackle the vast-vocabulary object recognition failure problem. On V3Det, this simple method greatly enhances the performance among one-stage, two-stage, and DETR-based detectors with only additional projection layers in both supervised and open-vocabulary settings. In particular, Prova improves Faster R-CNN, FCOS, and DINO by 3.3, 6.2, and 2.9 AP respectively in the supervised setting of V3Det. For the open-vocabulary setting, Prova achieves a new state-of-the-art performance with 32.8 base AP and 11.0 novel AP, which is of 2.6 and 4.3 gain over the previous methods.
Inst-IT: Boosting Multimodal Instance Understanding via Explicit Visual Prompt Instruction Tuning
Dec 04, 2024



Large Multimodal Models (LMMs) have made significant breakthroughs with the advancement of instruction tuning. However, while existing models can understand images and videos at a holistic level, they still struggle with instance-level understanding that requires a more nuanced comprehension and alignment. Instance-level understanding is crucial, as it focuses on the specific elements that we are most interested in. Excitingly, existing works find that the state-of-the-art LMMs exhibit strong instance understanding capabilities when provided with explicit visual cues. Motivated by this, we introduce an automated annotation pipeline assisted by GPT-4o to extract instance-level information from images and videos through explicit visual prompting for instance guidance. Building upon this pipeline, we proposed Inst-IT, a solution to enhance LMMs in Instance understanding via explicit visual prompt Instruction Tuning. Inst-IT consists of a benchmark to diagnose multimodal instance-level understanding, a large-scale instruction-tuning dataset, and a continuous instruction-tuning training paradigm to effectively enhance spatial-temporal instance understanding capabilities of existing LMMs. Experimental results show that, with the boost of Inst-IT, our models not only achieve outstanding performance on Inst-IT Bench but also demonstrate significant improvements across various generic image and video understanding benchmarks. This highlights that our dataset not only boosts instance-level understanding but also strengthens the overall capabilities of generic image and video comprehension.
V3Det Challenge 2024 on Vast Vocabulary and Open Vocabulary Object Detection: Methods and Results
Jun 17, 2024


Detecting objects in real-world scenes is a complex task due to various challenges, including the vast range of object categories, and potential encounters with previously unknown or unseen objects. The challenges necessitate the development of public benchmarks and challenges to advance the field of object detection. Inspired by the success of previous COCO and LVIS Challenges, we organize the V3Det Challenge 2024 in conjunction with the 4th Open World Vision Workshop: Visual Perception via Learning in an Open World (VPLOW) at CVPR 2024, Seattle, US. This challenge aims to push the boundaries of object detection research and encourage innovation in this field. The V3Det Challenge 2024 consists of two tracks: 1) Vast Vocabulary Object Detection: This track focuses on detecting objects from a large set of 13204 categories, testing the detection algorithm's ability to recognize and locate diverse objects. 2) Open Vocabulary Object Detection: This track goes a step further, requiring algorithms to detect objects from an open set of categories, including unknown objects. In the following sections, we will provide a comprehensive summary and analysis of the solutions submitted by participants. By analyzing the methods and solutions presented, we aim to inspire future research directions in vast vocabulary and open-vocabulary object detection, driving progress in this field. Challenge homepage: https://v3det.openxlab.org.cn/challenge
DeepStack: Deeply Stacking Visual Tokens is Surprisingly Simple and Effective for LMMs
Jun 06, 2024Most large multimodal models (LMMs) are implemented by feeding visual tokens as a sequence into the first layer of a large language model (LLM). The resulting architecture is simple but significantly increases computation and memory costs, as it has to handle a large number of additional tokens in its input layer. This paper presents a new architecture DeepStack for LMMs. Considering $N$ layers in the language and vision transformer of LMMs, we stack the visual tokens into $N$ groups and feed each group to its aligned transformer layer \textit{from bottom to top}. Surprisingly, this simple method greatly enhances the power of LMMs to model interactions among visual tokens across layers but with minimal additional cost. We apply DeepStack to both language and vision transformer in LMMs, and validate the effectiveness of DeepStack LMMs with extensive empirical results. Using the same context length, our DeepStack 7B and 13B parameters surpass their counterparts by \textbf{2.7} and \textbf{2.9} on average across \textbf{9} benchmarks, respectively. Using only one-fifth of the context length, DeepStack rivals closely to the counterparts that use the full context length. These gains are particularly pronounced on high-resolution tasks, e.g., \textbf{4.2}, \textbf{11.0}, and \textbf{4.0} improvements on TextVQA, DocVQA, and InfoVQA compared to LLaVA-1.5-7B, respectively. We further apply DeepStack to vision transformer layers, which brings us a similar amount of improvements, \textbf{3.8} on average compared with LLaVA-1.5-7B.
To See is to Believe: Prompting GPT-4V for Better Visual Instruction Tuning
Nov 29, 2023



Existing visual instruction tuning methods typically prompt large language models with textual descriptions to generate instruction-following data. Despite the promising performance achieved, these descriptions are derived from image annotations, which are oftentimes coarse-grained. Furthermore, the instructions might even contradict the visual content without observing the entire visual context. To address this challenge, we introduce a fine-grained visual instruction dataset, LVIS-Instruct4V, which contains 220K visually aligned and context-aware instructions produced by prompting the powerful GPT-4V with images from LVIS. Through experimental validation and case studies, we demonstrate that high-quality visual instructional data could improve the performance of LLaVA-1.5, a state-of-the-art large multimodal model, across a wide spectrum of benchmarks by clear margins. Notably, by simply replacing the LLaVA-Instruct with our LVIS-Instruct4V, we achieve better results than LLaVA on most challenging LMM benchmarks, e.g., LLaVA$^w$ (76.7 vs. 70.7) and MM-Vet (40.2 vs. 35.4). We release our data and model at https://github.com/X2FD/LVIS-INSTRUCT4V.
SEGIC: Unleashing the Emergent Correspondence for In-Context Segmentation
Nov 24, 2023In-context segmentation aims at segmenting novel images using a few labeled example images, termed as "in-context examples", exploring content similarities between examples and the target. The resulting models can be generalized seamlessly to novel segmentation tasks, significantly reducing the labeling and training costs compared with conventional pipelines. However, in-context segmentation is more challenging than classic ones due to its meta-learning nature, requiring the model to learn segmentation rules conditioned on a few samples, not just the segmentation. Unlike previous work with ad-hoc or non-end-to-end designs, we propose SEGIC, an end-to-end segment-in-context framework built upon a single vision foundation model (VFM). In particular, SEGIC leverages the emergent correspondence within VFM to capture dense relationships between target images and in-context samples. As such, information from in-context samples is then extracted into three types of instructions, i.e. geometric, visual, and meta instructions, serving as explicit conditions for the final mask prediction. SEGIC is a straightforward yet effective approach that yields state-of-the-art performance on one-shot segmentation benchmarks. Notably, SEGIC can be easily generalized to diverse tasks, including video object segmentation and open-vocabulary segmentation. Code will be available at \url{https://github.com/MengLcool/SEGIC}.
Learning from Rich Semantics and Coarse Locations for Long-tailed Object Detection
Oct 18, 2023



Long-tailed object detection (LTOD) aims to handle the extreme data imbalance in real-world datasets, where many tail classes have scarce instances. One popular strategy is to explore extra data with image-level labels, yet it produces limited results due to (1) semantic ambiguity -- an image-level label only captures a salient part of the image, ignoring the remaining rich semantics within the image; and (2) location sensitivity -- the label highly depends on the locations and crops of the original image, which may change after data transformations like random cropping. To remedy this, we propose RichSem, a simple but effective method, which is robust to learn rich semantics from coarse locations without the need of accurate bounding boxes. RichSem leverages rich semantics from images, which are then served as additional soft supervision for training detectors. Specifically, we add a semantic branch to our detector to learn these soft semantics and enhance feature representations for long-tailed object detection. The semantic branch is only used for training and is removed during inference. RichSem achieves consistent improvements on both overall and rare-category of LVIS under different backbones and detectors. Our method achieves state-of-the-art performance without requiring complex training and testing procedures. Moreover, we show the effectiveness of our method on other long-tailed datasets with additional experiments. Code is available at \url{https://github.com/MengLcool/RichSem}.
Detection Hub: Unifying Object Detection Datasets via Query Adaptation on Language Embedding
Jun 07, 2022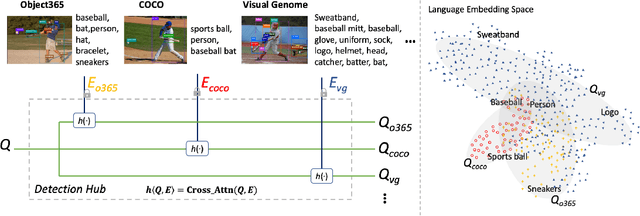

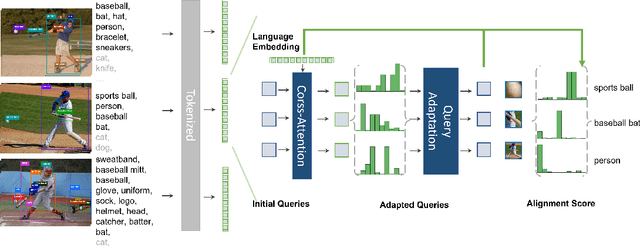
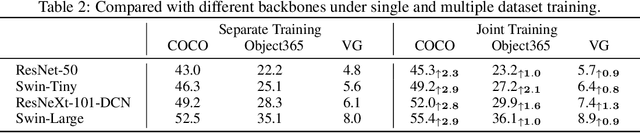
Leveraging large-scale data can introduce performance gains on many computer vision tasks. Unfortunately, this does not happen in object detection when training a single model under multiple datasets together. We observe two main obstacles: taxonomy difference and bounding box annotation inconsistency, which introduces domain gaps in different datasets that prevents us from joint training. In this paper, we show that these two challenges can be effectively addressed by simply adapting object queries on language embedding of categories per dataset. We design a detection hub to dynamically adapt queries on category embedding based on the different distributions of datasets. Unlike previous methods attempted to learn a joint embedding for all datasets, our adaptation method can utilize the language embedding as semantic centers for common categories, while learning the semantic bias towards specific categories belonging to different datasets to handle annotation differences and make up the domain gaps. These novel improvements enable us to end-to-end train a single detector on multiple datasets simultaneously to fully take their advantages. Further experiments on joint training on multiple datasets demonstrate the significant performance gains over separate individual fine-tuned detectors.