 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCRVerse: Towards Holistic OCR in End-to-End Vision-Language Models
Jan 29, 2026The development of large vision language models drives the demand for managing, and applying massive amounts of multimodal data, making OCR technology, which extracts information from visual images, increasingly popular. However, existing OCR methods primarily focus on recognizing text elements from images or scanned documents (\textbf{Text-centric OCR}), neglecting the identification of visual elements from visually information-dense image sources (\textbf{Vision-centric OCR}), such as charts, web pages and science plots. In reality, these visually information-dense images are widespread on the internet and have significant real-world application value, such as data visualization and web page analysis. In this technical report, we propose \textbf{OCRVerse}, the first holistic OCR method in end-to-end manner that enables unified text-centric OCR and vision-centric OCR. To this end, we constructe comprehensive data engineering to cover a wide range of text-centric documents, such as newspapers, magazines and books, as well as vision-centric rendered composites, including charts, web pages and scientific plots. Moreover, we propose a two-stage SFT-RL multi-domain training method for OCRVerse. SFT directly mixes cross-domain data to train and establish initial domain knowledge, while RL focuses on designing personalized reward strategies for the characteristics of each domain. Specifically, since different domains require various output formats and expected outputs, we provide sufficient flexibility in the RL stage to customize flexible reward signals for each domain, thereby improving cross-domain fusion and avoiding data conflicts. Experimental results demonstrate the effectiveness of OCRVerse, achieving competitive results across text-centric and vision-centric data types, even comparable to large-scale open-source and closed-source models.
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
Jan 07, 2026We present Gen3R, a method that bridges the strong priors of foundational reconstruction models and video diffusion models for scene-level 3D generation. We repurpose the VGGT reconstruction model to produce geometric latents by training an adapter on its tokens, which are regularized to align with the appearance latents of pre-trained video diffusion models. By jointly generating these disentangled yet aligned latents, Gen3R produces both RGB videos and corresponding 3D geometry, including camera poses, depth maps, and global point clouds. Experiments demonstrate that our approach achieves state-of-the-art results in single- and multi-image conditioned 3D scene generation. Additionally, our method can enhance the robustness of reconstruction by leveraging generative priors, demonstrating the mutual benefit of tightly coupling reconstruction and generative models.
cuPilot: A Strategy-Coordinated Multi-agent Framework for CUDA Kernel Evolution
Dec 23, 2025Optimizing CUDA kernels is a challenging and labor-intensive task, given the need for hardware-software co-design expertise and the proprietary nature of high-performance kernel libraries. While recent large language models (LLMs) combined with evolutionary algorithms show promise in automatic kernel optimization, existing approaches often fall short in performance due to their suboptimal agent designs and mismatched evolution representations. This work identifies these mismatches and proposes cuPilot, a strategy-coordinated multi-agent framework that introduces strategy as an intermediate semantic representation for kernel evolution. Key contributions include a strategy-coordinated evolution algorithm, roofline-guided prompting, and strategy-level population initialization. Experimental results show that the generated kernels by cuPilot achieve an average speed up of 3.09$\times$ over PyTorch on a benchmark of 100 kernels. On the GEMM tasks, cuPilot showcases sophisticated optimizations and achieves high utilization of critical hardware units. The generated kernels are open-sourced at https://github.com/champloo2878/cuPilot-Kernels.git.
Learning When to Look: A Disentangled Curriculum for Strategic Perception in Multimodal Reasoning
Dec 19, 2025Multimodal Large Language Models (MLLMs) demonstrate significant potential but remain brittle in complex, long-chain visual reasoning tasks. A critical failure mode is "visual forgetting", where models progressively lose visual grounding as reasoning extends, a phenomenon aptly described as "think longer, see less". We posit this failure stems from current training paradigms prematurely entangling two distinct cognitive skills: (1) abstract logical reasoning "how-to-think") and (2) strategic visual perception ("when-to-look"). This creates a foundational cold-start deficiency -- weakening abstract reasoning -- and a strategic perception deficit, as models lack a policy for when to perceive. In this paper, we propose a novel curriculum-based framework to disentangle these skills. First, we introduce a disentangled Supervised Fine-Tuning (SFT) curriculum that builds a robust abstract reasoning backbone on text-only data before anchoring it to vision with a novel Perception-Grounded Chain-of-Thought (PG-CoT) paradigm. Second, we resolve the strategic perception deficit by formulating timing as a reinforcement learning problem. We design a Pivotal Perception Reward that teaches the model when to look by coupling perceptual actions to linguistic markers of cognitive uncertainty (e.g., "wait", "verify"), thereby learning an autonomous grounding policy. Our contributions include the formalization of these two deficiencies and the development of a principled, two-stage framework to address them, transforming the model from a heuristic-driven observer to a strategic, grounded reasoner. \textbf{Code}: \url{https://github.com/gaozilve-max/learning-when-to-look}.
STAR: STacked AutoRegressive Scheme for Unified Multimodal Learning
Dec 15, 2025



Multimodal large language models (MLLMs) play a pivotal role in advancing the quest for general artificial intelligence. However, achieving unified target for multimodal understanding and generation remains challenging due to optimization conflicts and performance trade-offs. To effectively enhance generative performance while preserving existing comprehension capabilities, we introduce STAR: a STacked AutoRegressive scheme for task-progressive unified multimodal learning. This approach decomposes multimodal learning into multiple stages: understanding, generation, and editing. By freezing the parameters of the fundamental autoregressive (AR) model and progressively stacking isomorphic AR modules, it avoids cross-task interference while expanding the model's capabilities. Concurrently, we introduce a high-capacity VQ to enhance the granularity of image representations and employ an implicit reasoning mechanism to improve generation quality under complex conditions. Experiments demonstrate that STAR achieves state-of-the-art performance on GenEval (0.91), DPG-Bench (87.44), and ImgEdit (4.34), validating its efficacy for unified multimodal learning.
DBGroup: Dual-Branch Point Grouping for Weakly Supervised 3D Instance Segmentation
Nov 13, 2025



Weakly supervised 3D instance segmentation is essential for 3D scene understanding, especially as the growing scale of data and high annotation costs associated with fully supervised approaches. Existing methods primarily rely on two forms of weak supervision: one-thing-one-click annotations and bounding box annotations, both of which aim to reduce labeling efforts. However, these approaches still encounter limitations, including labor-intensive annotation processes, high complexity, and reliance on expert annotators. To address these challenges, we propose \textbf{DBGroup}, a two-stage weakly supervised 3D instance segmentation framework that leverages scene-level annotations as a more efficient and scalable alternative. In the first stage, we introduce a Dual-Branch Point Grouping module to generate pseudo labels guided by semantic and mask cues extracted from multi-view images. To further improve label quality, we develop two refinement strategies: Granularity-Aware Instance Merging and Semantic Selection and Propagation. The second stage involves multi-round self-training on an end-to-end instance segmentation network using the refined pseudo-labels. Additionally, we introduce an Instance Mask Filter strategy to address inconsistencies within the pseudo labels. Extensive experiments demonstrate that DBGroup achieves competitive performance compared to sparse-point-level supervised 3D instance segmentation methods, while surpassing state-of-the-art scene-level supervised 3D semantic segmentation approaches. Code is available at https://github.com/liuxuexun/DBGroup.
Metis-HOME: Hybrid Optimized Mixture-of-Experts for Multimodal Reasoning
Oct 23, 2025Inspired by recent advancements in LLM reasoning, the field of multimodal reasoning has seen remarkable progress, achieving significant performance gains on intricate tasks such as mathematical problem-solving. Despite this progress, current multimodal large reasoning models exhibit two key limitations. They tend to employ computationally expensive reasoning even for simple queries, leading to inefficiency. Furthermore, this focus on specialized reasoning often impairs their broader, more general understanding capabilities. In this paper, we propose Metis-HOME: a Hybrid Optimized Mixture-of-Experts framework designed to address this trade-off. Metis-HOME enables a ''Hybrid Thinking'' paradigm by structuring the original dense model into two distinct expert branches: a thinking branch tailored for complex, multi-step reasoning, and a non-thinking branch optimized for rapid, direct inference on tasks like general VQA and OCR. A lightweight, trainable router dynamically allocates queries to the most suitable expert. We instantiate Metis-HOME by adapting the Qwen2.5-VL-7B into an MoE architecture. Comprehensive evaluations reveal that our approach not only substantially enhances complex reasoning abilities but also improves the model's general capabilities, reversing the degradation trend observed in other reasoning-specialized models. Our work establishes a new paradigm for building powerful and versatile MLLMs, effectively resolving the prevalent reasoning-vs-generalization dilemma.
UItron: Foundational GUI Agent with Advanced Perception and Planning
Aug 29, 2025GUI agent aims to enable automated operations on Mobile/PC devices, which is an important task toward achieving artificial general intelligence. The rapid advancement of VLMs accelerates the development of GUI agents, owing to their powerful capabilities in visual understanding and task planning. However, building a GUI agent remains a challenging task due to the scarcity of operation trajectories, the availability of interactive infrastructure, and the limitation of initial capabilities in foundation models. In this work, we introduce UItron, an open-source foundational model for automatic GUI agents, featuring advanced GUI perception, grounding, and planning capabilities. UItron highlights the necessity of systemic data engineering and interactive infrastructure as foundational components for advancing GUI agent development. It not only systematically studies a series of data engineering strategies to enhance training effects, but also establishes an interactive environment connecting both Mobile and PC devices. In training, UItron adopts supervised finetuning over perception and planning tasks in various GUI scenarios, and then develop a curriculum reinforcement learning framework to enable complex reasoning and exploration for online environments. As a result, UItron achieves superior performance in benchmarks of GUI perception, grounding, and planning. In particular, UItron highlights the interaction proficiency with top-tier Chinese mobile APPs, as we identified a general lack of Chinese capabilities even in state-of-the-art solutions. To this end, we manually collect over one million steps of operation trajectories across the top 100 most popular apps, and build the offline and online agent evaluation environments. Experimental results demonstrate that UItron achieves significant progress in Chinese app scenarios, propelling GUI agents one step closer to real-world application.
Beyond the Visible: Benchmarking Occlusion Perception in Multimodal Large Language Models
Aug 06, 2025Occlusion perception, a critical foundation for human-level spatial understanding, embodies the challenge of integrating visual recognition and reasoning. Though multimodal large language models (MLLMs) have demonstrated remarkable capabilities, their performance on occlusion perception remains under-explored. To address this gap, we introduce O-Bench, the first visual question answering (VQA) benchmark specifically designed for occlusion perception. Based on SA-1B, we construct 1,365 images featuring semantically coherent occlusion scenarios through a novel layered synthesis approach. Upon this foundation, we annotate 4,588 question-answer pairs in total across five tailored tasks, employing a reliable, semi-automatic workflow. Our extensive evaluation of 22 representative MLLMs against the human baseline reveals a significant performance gap between current MLLMs and humans, which, we find, cannot be sufficiently bridged by model scaling or thinking process. We further identify three typical failure patterns, including an overly conservative bias, a fragile gestalt prediction, and a struggle with quantitative tasks. We believe O-Bench can not only provide a vital evaluation tool for occlusion perception, but also inspire the development of MLLMs for better visual intelligence. Our benchmark will be made publicly available upon paper publication.
RoboTron-Sim: Improving Real-World Driving via Simulated Hard-Case
Aug 06, 2025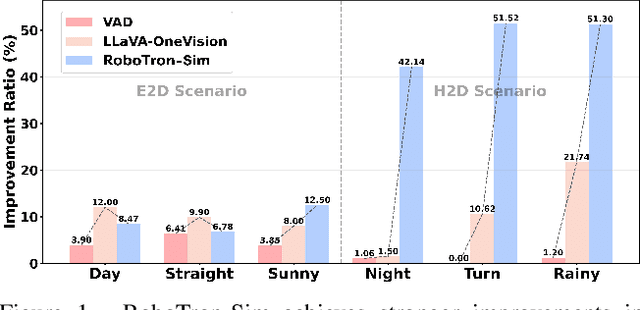



Collecting real-world data for rare high-risk scenarios, long-tailed driving events, and complex interactions remains challenging, leading to poor performance of existing autonomous driving systems in these critical situations. In this paper, we propose RoboTron-Sim that improves real-world driving in critical situations by utilizing simulated hard cases. First, we develop a simulated dataset called Hard-case Augmented Synthetic Scenarios (HASS), which covers 13 high-risk edge-case categories, as well as balanced environmental conditions such as day/night and sunny/rainy. Second, we introduce Scenario-aware Prompt Engineering (SPE) and an Image-to-Ego Encoder (I2E Encoder) to enable multimodal large language models to effectively learn real-world challenging driving skills from HASS, via adapting to environmental deviations and hardware differences between real-world and simulated scenarios. Extensive experiments on nuScenes show that RoboTron-Sim improves driving performance in challenging scenarios by around 50%, achieving state-of-the-art results in real-world open-loop planning. Qualitative results further demonstrate the effectiveness of RoboTron-Sim in better managing rare high-risk driving scenarios. Project page: https://stars79689.github.io/RoboTron-Sim/