 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoAlign: Geometric Feature Realignment for MLLM Spatial Reasoning
Apr 14, 2026Multimodal large language models (MLLMs) have exhibited remarkable performance in various visual tasks, yet still struggle with spatial reasoning. Recent efforts mitigate this by injecting geometric features from 3D foundation models, but rely on static single-layer extractions. We identify that such an approach induces a task misalignment bias: the geometric features naturally evolve towards 3D pretraining objectives, which may contradict the heterogeneous spatial demands of MLLMs, rendering any single layer fundamentally insufficient. To resolve this, we propose GeoAlign, a novel framework that dynamically aggregates multi-layer geometric features to realign with the actual demands. GeoAlign constructs a hierarchical geometric feature bank and leverages the MLLM's original visual tokens as content-aware queries to perform layer-wise sparse routing, adaptively fetching the suitable geometric features for each patch. Extensive experiments on VSI-Bench, ScanQA, and SQA3D demonstrate that our compact 4B model effectively achieves state-of-the-art performance, even outperforming larger existing MLLMs.
Key-Value Pair-Free Continual Learner via Task-Specific Prompt-Prototype
Jan 08, 2026Continual learning aims to enable models to acquire new knowledge while retaining previously learned information. Prompt-based methods have shown remarkable performance in this domain; however, they typically rely on key-value pairing, which can introduce inter-task interference and hinder scalability. To overcome these limitations, we propose a novel approach employing task-specific Prompt-Prototype (ProP), thereby eliminating the need for key-value pairs. In our method, task-specific prompts facilitate more effective feature learning for the current task, while corresponding prototypes capture the representative features of the input. During inference, predictions are generated by binding each task-specific prompt with its associated prototype. Additionally, we introduce regularization constraints during prompt initialization to penalize excessively large values, thereby enhancing stability. Experiments on several widely used datasets demonstrate the effectiveness of the proposed method. In contrast to mainstream prompt-based approaches, our framework removes the dependency on key-value pairs, offering a fresh perspective for future continual learning research.
Beyond the Visible: Benchmarking Occlusion Perception in Multimodal Large Language Models
Aug 06, 2025Occlusion perception, a critical foundation for human-level spatial understanding, embodies the challenge of integrating visual recognition and reasoning. Though multimodal large language models (MLLMs) have demonstrated remarkable capabilities, their performance on occlusion perception remains under-explored. To address this gap, we introduce O-Bench, the first visual question answering (VQA) benchmark specifically designed for occlusion perception. Based on SA-1B, we construct 1,365 images featuring semantically coherent occlusion scenarios through a novel layered synthesis approach. Upon this foundation, we annotate 4,588 question-answer pairs in total across five tailored tasks, employing a reliable, semi-automatic workflow. Our extensive evaluation of 22 representative MLLMs against the human baseline reveals a significant performance gap between current MLLMs and humans, which, we find, cannot be sufficiently bridged by model scaling or thinking process. We further identify three typical failure patterns, including an overly conservative bias, a fragile gestalt prediction, and a struggle with quantitative tasks. We believe O-Bench can not only provide a vital evaluation tool for occlusion perception, but also inspire the development of MLLMs for better visual intelligence. Our benchmark will be made publicly available upon paper publication.
ShapeMamba-EM: Fine-Tuning Foundation Model with Local Shape Descriptors and Mamba Blocks for 3D EM Image Segmentation
Aug 26, 2024



Electron microscopy (EM) imaging offers unparalleled resolution for analyzing neural tissues, crucial for uncovering the intricacies of synaptic connections and neural processes fundamental to understanding behavioral mechanisms. Recently, the foundation models have demonstrated impressive performance across numerous natural and medical image segmentation tasks. However, applying these foundation models to EM segmentation faces significant challenges due to domain disparities. This paper presents ShapeMamba-EM, a specialized fine-tuning method for 3D EM segmentation, which employs adapters for long-range dependency modeling and an encoder for local shape description within the original foundation model. This approach effectively addresses the unique volumetric and morphological complexities of EM data. Tested over a wide range of EM images, covering five segmentation tasks and 10 datasets, ShapeMamba-EM outperforms existing methods, establishing a new standard in EM image segmentation and enhancing the understanding of neural tissue architecture.
Amodal Segmentation for Laparoscopic Surgery Video Instruments
Aug 02, 2024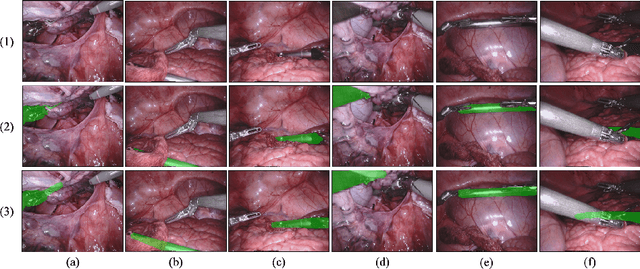
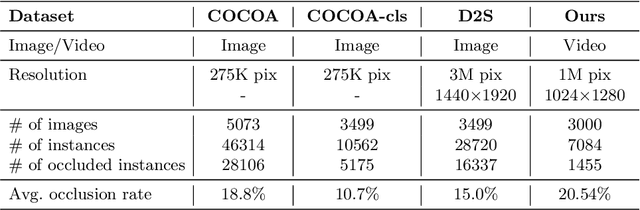
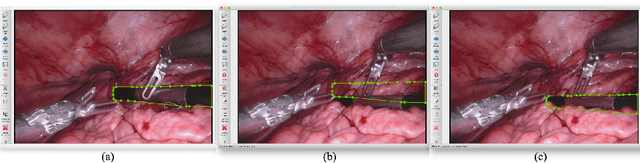

Segmentation of surgical instruments is crucial for enhancing surgeon performance and ensuring patient safety. Conventional techniques such as binary, semantic, and instance segmentation share a common drawback: they do not accommodate the parts of instruments obscured by tissues or other instruments. Precisely predicting the full extent of these occluded instruments can significantly improve laparoscopic surgeries by providing critical guidance during operations and assisting in the analysis of potential surgical errors, as well as serving educational purposes. In this paper, we introduce Amodal Segmentation to the realm of surgical instruments in the medical field. This technique identifies both the visible and occluded parts of an object. To achieve this, we introduce a new Amoal Instruments Segmentation (AIS) dataset, which was developed by reannotating each instrument with its complete mask, utilizing the 2017 MICCAI EndoVis Robotic Instrument Segmentation Challenge dataset. Additionally, we evaluate several leading amodal segmentation methods to establish a benchmark for this new dataset.
PLUG: Revisiting Amodal Segmentation with Foundation Model and Hierarchical Focus
May 25, 2024



Aiming to predict the complete shapes of partially occluded objects, amodal segmentation is an important step towards visual intelligence. With crucial significance, practical prior knowledge derives from sufficient training, while limited amodal annotations pose challenges to achieve better performance. To tackle this problem, utilizing the mighty priors accumulated in the foundation model, we propose the first SAM-based amodal segmentation approach, PLUG. Methodologically, a novel framework with hierarchical focus is presented to better adapt the task characteristics and unleash the potential capabilities of SAM. In the region level, due to the association and division in visible and occluded areas, inmodal and amodal regions are assigned as the focuses of distinct branches to avoid mutual disturbance. In the point level, we introduce the concept of uncertainty to explicitly assist the model in identifying and focusing on ambiguous points. Guided by the uncertainty map, a computation-economic point loss is applied to improve the accuracy of predicted boundaries. Experiments are conducted on several prominent datasets, and the results show that our proposed method outperforms existing methods with large margins. Even with fewer total parameters, our method still exhibits remarkable advantages.
Beyond Score Changes: Adversarial Attack on No-Reference Image Quality Assessment from Two Perspectives
Apr 24, 2024



Deep neural networks have demonstrated impressive success in No-Reference Image Quality Assessment (NR-IQA). However, recent researches highlight the vulnerability of NR-IQA models to subtle adversarial perturbations, leading to inconsistencies between model predictions and subjective ratings. Current adversarial attacks, however, focus on perturbing predicted scores of individual images, neglecting the crucial aspect of inter-score correlation relationships within an entire image set. Meanwhile, it is important to note that the correlation, like ranking correlation, plays a significant role in NR-IQA tasks. To comprehensively explore the robustness of NR-IQA models, we introduce a new framework of correlation-error-based attacks that perturb both the correlation within an image set and score changes on individual images. Our research primarily focuses on ranking-related correlation metrics like Spearman's Rank-Order Correlation Coefficient (SROCC) and prediction error-related metrics like Mean Squared Error (MSE). As an instantiation, we propose a practical two-stage SROCC-MSE-Attack (SMA) that initially optimizes target attack scores for the entire image set and then generates adversarial examples guided by these scores. Experimental results demonstrate that our SMA method not only significantly disrupts the SROCC to negative values but also maintains a considerable change in the scores of individual images. Meanwhile, it exhibits state-of-the-art performance across metrics with different categories. Our method provides a new perspective on the robustness of NR-IQA models.
Defense Against Adversarial Attacks on No-Reference Image Quality Models with Gradient Norm Regularization
Mar 18, 2024



The task of No-Reference Image Quality Assessment (NR-IQA) is to estimate the quality score of an input image without additional information. NR-IQA models play a crucial role in the media industry, aiding in performance evaluation and optimization guidance. However, these models are found to be vulnerable to adversarial attacks, which introduce imperceptible perturbations to input images, resulting in significant changes in predicted scores. In this paper, we propose a defense method to improve the stability in predicted scores when attacked by small perturbations, thus enhancing the adversarial robustness of NR-IQA models. To be specific, we present theoretical evidence showing that the magnitude of score changes is related to the $\ell_1$ norm of the model's gradient with respect to the input image. Building upon this theoretical foundation, we propose a norm regularization training strategy aimed at reducing the $\ell_1$ norm of the gradient, thereby boosting the robustness of NR-IQA models. Experiments conducted on four NR-IQA baseline models demonstrate the effectiveness of our strategy in reducing score changes in the presence of adversarial attacks. To the best of our knowledge, this work marks the first attempt to defend against adversarial attacks on NR-IQA models. Our study offers valuable insights into the adversarial robustness of NR-IQA models and provides a foundation for future research in this area.
Exploring Vulnerabilities of No-Reference Image Quality Assessment Models: A Query-Based Black-Box Method
Jan 17, 2024



No-Reference Image Quality Assessment (NR-IQA) aims to predict image quality scores consistent with human perception without relying on pristine reference images, serving as a crucial component in various visual tasks. Ensuring the robustness of NR-IQA methods is vital for reliable comparisons of different image processing techniques and consistent user experiences in recommendations. The attack methods for NR-IQA provide a powerful instrument to test the robustness of NR-IQA. However, current attack methods of NR-IQA heavily rely on the gradient of the NR-IQA model, leading to limitations when the gradient information is unavailable. In this paper, we present a pioneering query-based black box attack against NR-IQA methods. We propose the concept of score boundary and leverage an adaptive iterative approach with multiple score boundaries. Meanwhile, the initial attack directions are also designed to leverage the characteristics of the Human Visual System (HVS). Experiments show our method outperforms all compared state-of-the-art attack methods and is far ahead of previous black-box methods. The effective NR-IQA model DBCNN suffers a Spearman's rank-order correlation coefficient (SROCC) decline of 0.6381 attacked by our method, revealing the vulnerability of NR-IQA models to black-box attacks. The proposed attack method also provides a potent tool for further exploration into NR-IQA robustness.
BLADE: Box-Level Supervised Amodal Segmentation through Directed Expansion
Jan 04, 2024



Perceiving the complete shape of occluded objects is essential for human and machine intelligence. While the amodal segmentation task is to predict the complete mask of partially occluded objects, it is time-consuming and labor-intensive to annotate the pixel-level ground truth amodal masks. Box-level supervised amodal segmentation addresses this challenge by relying solely on ground truth bounding boxes and instance classes as supervision, thereby alleviating the need for exhaustive pixel-level annotations. Nevertheless, current box-level methodologies encounter limitations in generating low-resolution masks and imprecise boundaries, failing to meet the demands of practical real-world applications. We present a novel solution to tackle this problem by introducing a directed expansion approach from visible masks to corresponding amodal masks. Our approach involves a hybrid end-to-end network based on the overlapping region - the area where different instances intersect. Diverse segmentation strategies are applied for overlapping regions and non-overlapping regions according to distinct characteristics. To guide the expansion of visible masks, we introduce an elaborately-designed connectivity loss for overlapping regions, which leverages correlations with visible masks and facilitates accurate amodal segmentation. Experiments are conducted on several challenging datasets and the results show that our proposed method can outperform existing state-of-the-art methods with large margins.