 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Energy-Based Models for End-to-End Speech Recognition
Mar 25, 2021


End-to-end models with auto-regressive decoders have shown impressive results for automatic speech recognition (ASR). These models formulate the sequence-level probability as a product of the conditional probabilities of all individual tokens given their histories. However, the performance of locally normalised models can be sub-optimal because of factors such as exposure bias. Consequently, the model distribution differs from the underlying data distribution. In this paper, the residual energy-based model (R-EBM) is proposed to complement the auto-regressive ASR model to close the gap between the two distributions. Meanwhile, R-EBMs can also be regarded as utterance-level confidence estimators, which may benefit many downstream tasks. Experiments on a 100hr LibriSpeech dataset show that R-EBMs can reduce the word error rates (WERs) by 8.2%/6.7% while improving areas under precision-recall curves of confidence scores by 12.6%/28.4% on test-clean/test-other sets. Furthermore, on a state-of-the-art model using self-supervised learning (wav2vec 2.0), R-EBMs still significantly improves both the WER and confidence estimation performance.
Learning Word-Level Confidence For Subword End-to-End ASR
Mar 11, 2021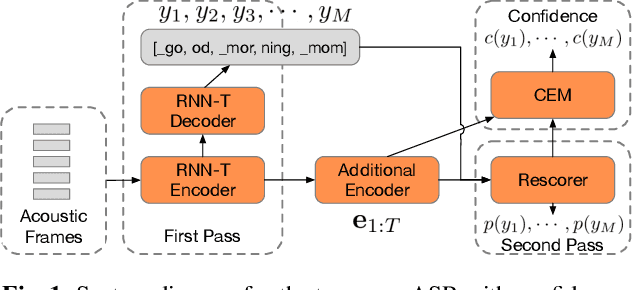

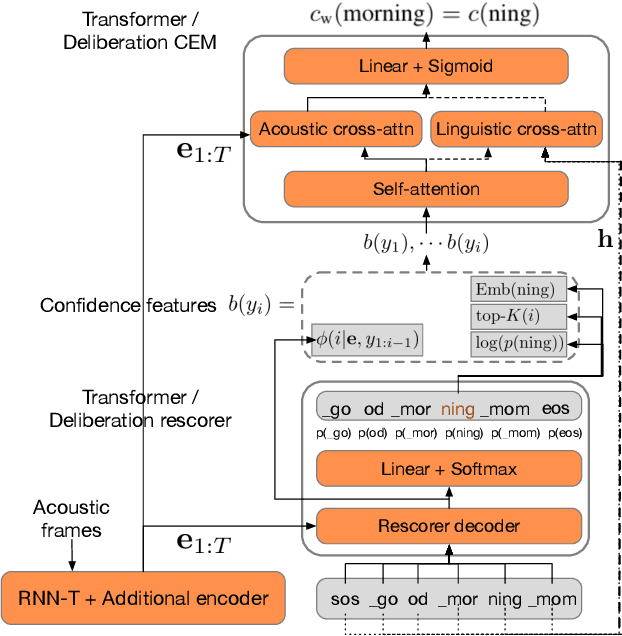
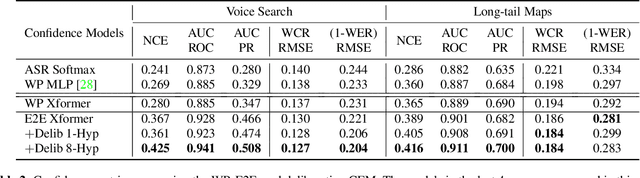
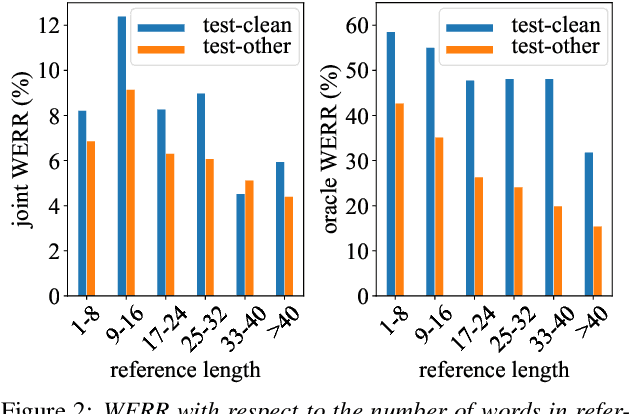
We study the problem of word-level confidence estimation in subword-based end-to-end (E2E) models for automatic speech recognition (ASR). Although prior works have proposed training auxiliary confidence models for ASR systems, they do not extend naturally to systems that operate on word-pieces (WP) as their vocabulary. In particular, ground truth WP correctness labels are needed for training confidence models, but the non-unique tokenization from word to WP causes inaccurate labels to be generated. This paper proposes and studies two confidence models of increasing complexity to solve this problem. The final model uses self-attention to directly learn word-level confidence without needing subword tokenization, and exploits full context features from multiple hypotheses to improve confidence accuracy. Experiments on Voice Search and long-tail test sets show standard metrics (e.g., NCE, AUC, RMSE) improving substantially. The proposed confidence module also enables a model selection approach to combine an on-device E2E model with a hybrid model on the server to address the rare word recognition problem for the E2E model.
Spatial-Temporal Alignment Network for Action Recognition and Detection
Dec 04, 2020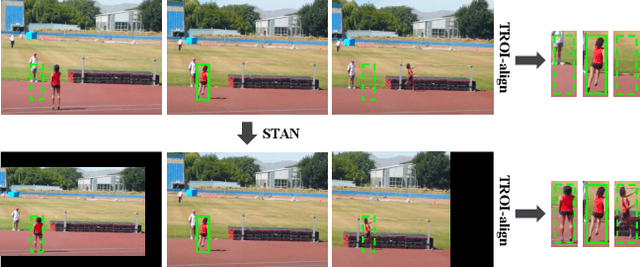
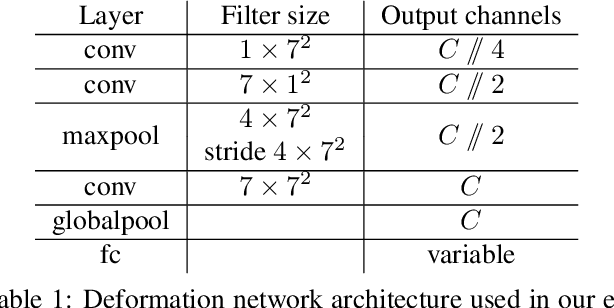
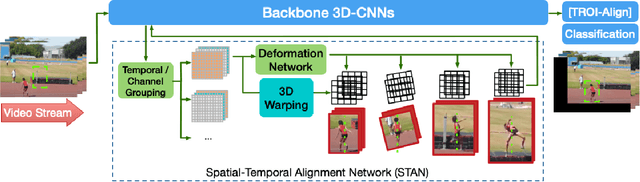
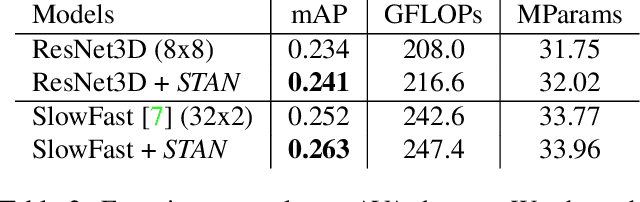
This paper studies how to introduce viewpoint-invariant feature representations that can help action recognition and detection. Although we have witnessed great progress of action recognition in the past decade, it remains challenging yet interesting how to efficiently model the geometric variations in large scale datasets. This paper proposes a novel Spatial-Temporal Alignment Network (STAN) that aims to learn geometric invariant representations for action recognition and action detection. The STAN model is very light-weighted and generic, which could be plugged into existing action recognition models like ResNet3D and the SlowFast with a very low extra computational cost. We test our STAN model extensively on AVA, Kinetics-400, AVA-Kinetics, Charades, and Charades-Ego datasets. The experimental results show that the STAN model can consistently improve the state of the arts in both action detection and action recognition tasks. We will release our data, models and code.
Confidence Estimation for Attention-based Sequence-to-sequence Models for Speech Recognition
Oct 23, 2020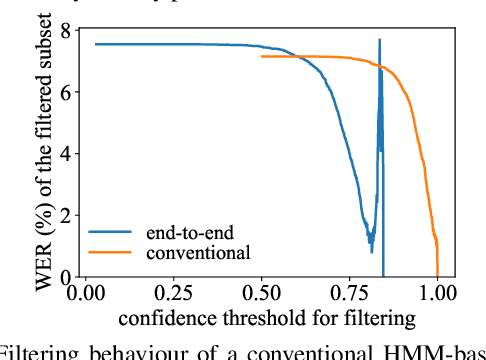
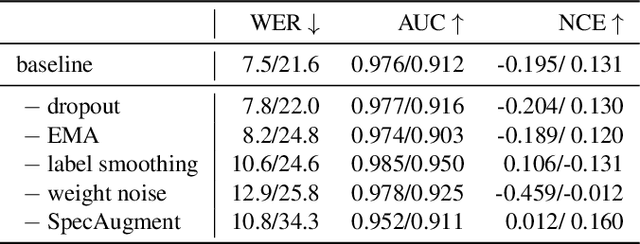
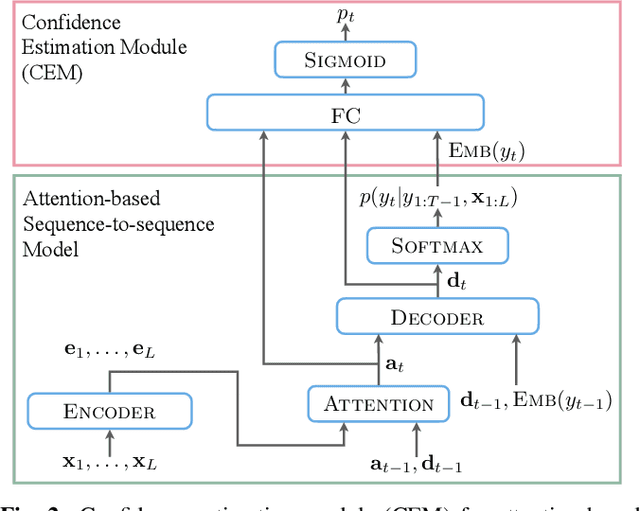
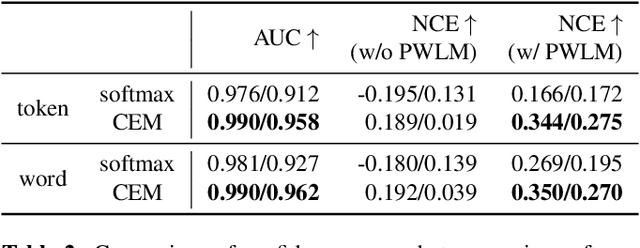
For various speech-related tasks, confidence scores from a speech recogniser are a useful measure to assess the quality of transcriptions. In traditional hidden Markov model-based automatic speech recognition (ASR) systems, confidence scores can be reliably obtained from word posteriors in decoding lattices. However, for an ASR system with an auto-regressive decoder, such as an attention-based sequence-to-sequence model, computing word posteriors is difficult. An obvious alternative is to use the decoder softmax probability as the model confidence. In this paper, we first examine how some commonly used regularisation methods influence the softmax-based confidence scores and study the overconfident behaviour of end-to-end models. Then we propose a lightweight and effective approach named confidence estimation module (CEM) on top of an existing end-to-end ASR model. Experiments on LibriSpeech show that CEM can mitigate the overconfidence problem and can produce more reliable confidence scores with and without shallow fusion of a language model. Further analysis shows that CEM generalises well to speech from a moderately mismatched domain and can potentially improve downstream tasks such as semi-supervised learning.
Improving Streaming Automatic Speech Recognition With Non-Streaming Model Distillation On Unsupervised Data
Oct 22, 2020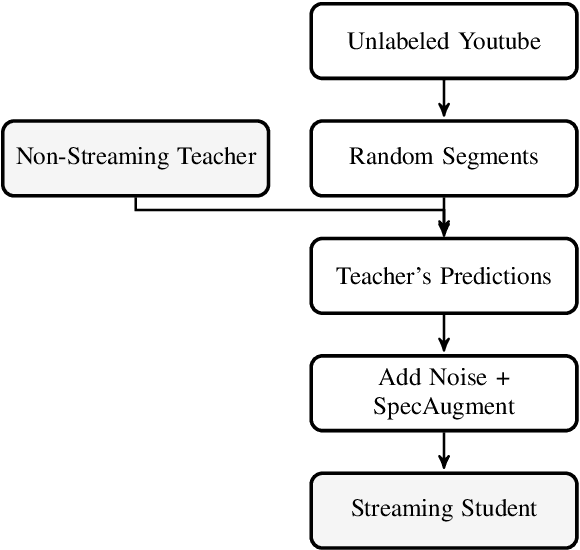
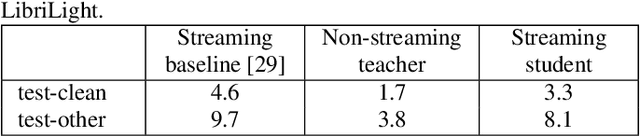
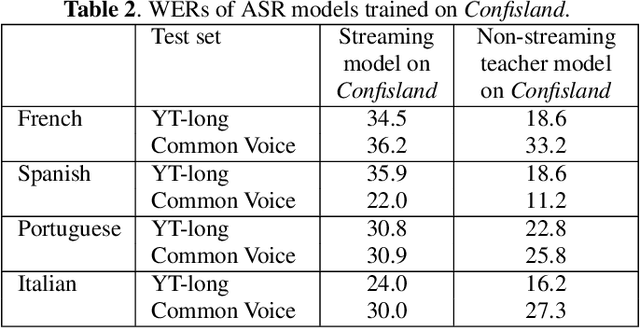
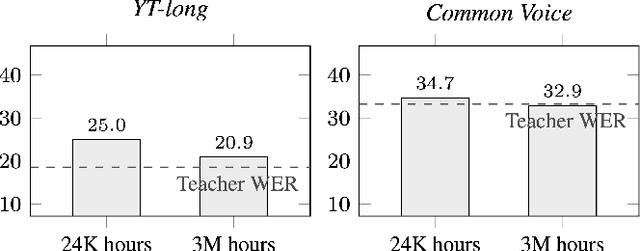
Streaming end-to-end automatic speech recognition (ASR) models are widely used on smart speakers and on-device applications. Since these models are expected to transcribe speech with minimal latency, they are constrained to be causal with no future context, compared to their non-streaming counterparts. Consequently, streaming models usually perform worse than non-streaming models. We propose a novel and effective learning method by leveraging a non-streaming ASR model as a teacher to generate transcripts on an arbitrarily large data set, which is then used to distill knowledge into streaming ASR models. This way, we scale the training of streaming models to up to 3 million hours of YouTube audio. Experiments show that our approach can significantly reduce the word error rate (WER) of RNNT models not only on LibriSpeech but also on YouTube data in four languages. For example, in French, we are able to reduce the WER by 16.4% relatively to a baseline streaming model by leveraging a non-streaming teacher model trained on the same amount of labeled data as the baseline.
Zero-shot Entity Linking with Efficient Long Range Sequence Modeling
Oct 12, 2020
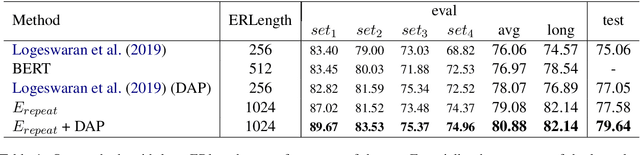
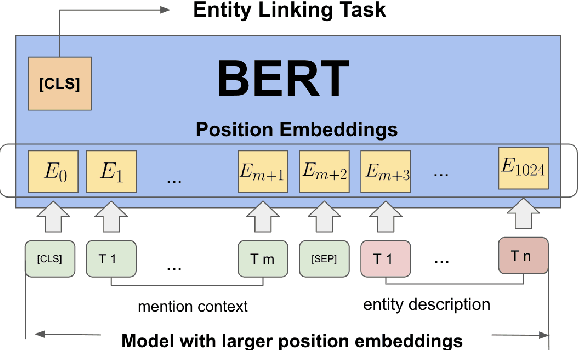
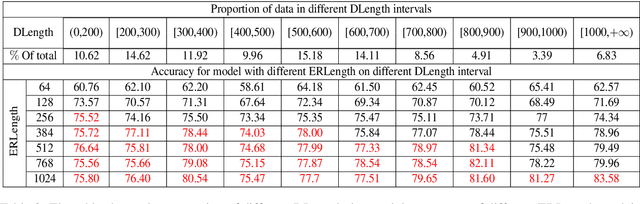
This paper considers the problem of zero-shot entity linking, in which a link in the test time may not present in training. Following the prevailing BERT-based research efforts, we find a simple yet effective way is to expand the long-range sequence modeling. Unlike many previous methods, our method does not require expensive pre-training of BERT with long position embedding. Instead, we propose an efficient position embeddings initialization method called Embedding-repeat, which initializes larger position embeddings based on BERT-Base. On Wikia's zero-shot EL dataset, our method improves the SOTA from 76.06% to 79.08%, and for its long data, the corresponding improvement is from 74.57% to 82.14%. Our experiments suggest the effectiveness of long-range sequence modeling without retraining the BERT model.
RNN-T Models Fail to Generalize to Out-of-Domain Audio: Causes and Solutions
May 17, 2020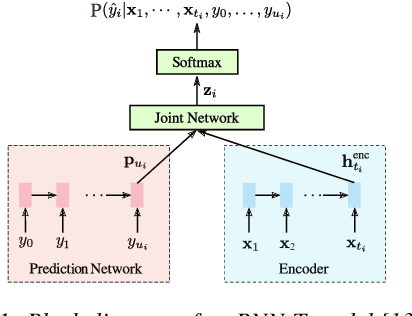
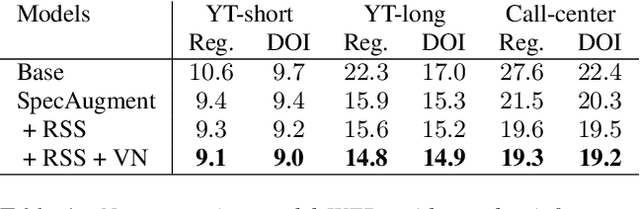
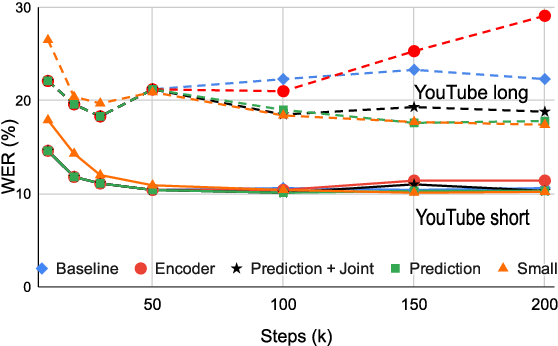
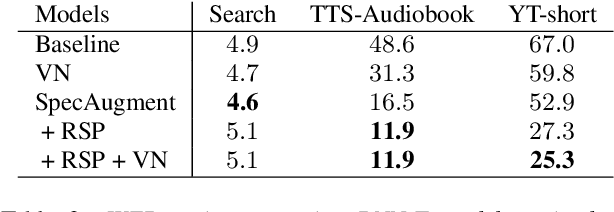
In recent years, all-neural end-to-end approaches have obtained state-of-the-art results on several challenging automatic speech recognition (ASR) tasks. However, most existing works focus on building ASR models where train and test data are drawn from the same domain. This results in poor generalization characteristics on mismatched-domains: e.g., end-to-end models trained on short segments perform poorly when evaluated on longer utterances. In this work, we analyze the generalization properties of streaming and non-streaming recurrent neural network transducer (RNN-T) based end-to-end models in order to identify model components that negatively affect generalization performance. We propose two solutions: combining multiple regularization techniques during training, and using dynamic overlapping inference. On a long-form YouTube test set, when the non-streaming RNN-T model is trained with shorter segments of data, the proposed combination improves word error rate (WER) from 22.3% to 14.8%; when the streaming RNN-T model trained on short Search queries, the proposed techniques improve WER on the YouTube set from 67.0% to 25.3%. Finally, when trained on Librispeech, we find that dynamic overlapping inference improves WER on YouTube from 99.8% to 33.0%.
Label-Efficient Learning on Point Clouds using Approximate Convex Decompositions
Mar 30, 2020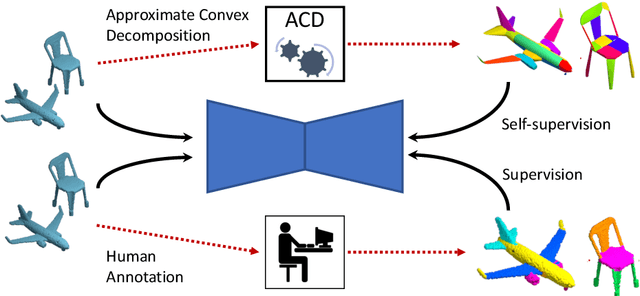
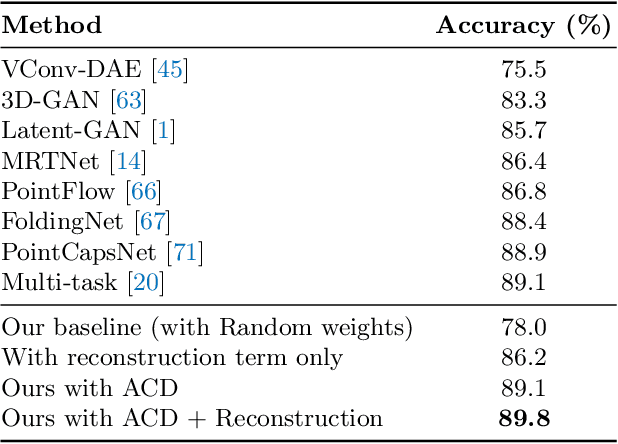


The problems of shape classification and part segmentation from 3D point clouds have garnered increasing attention in the last few years. But both of these problems suffer from relatively small training sets, creating the need for statistically efficient methods to learn 3D shape representations. In this work, we investigate the use of Approximate Convex Decompositions (ACD) as a self-supervisory signal for label-efficient learning of point cloud representations. Decomposing a 3D shape into simpler constituent parts or primitives is a fundamental problem in geometrical shape processing. There has been extensive work on such decompositions, where the criterion for simplicity of a constituent shape is often defined in terms of convexity for solid primitives. In this paper, we show that using the results of ACD to approximate a ground truth segmentation provides excellent self-supervision for learning 3D point cloud representations that are highly effective on downstream tasks. We report improvements over the state-of-theart in unsupervised representation learning on the ModelNet40 shape classification dataset and significant gains in few-shot part segmentation on the ShapeNetPart dataset. Code available at https://github.com/matheusgadelha/PointCloudLearningACD
Speech Sentiment Analysis via Pre-trained Features from End-to-end ASR Models
Nov 21, 2019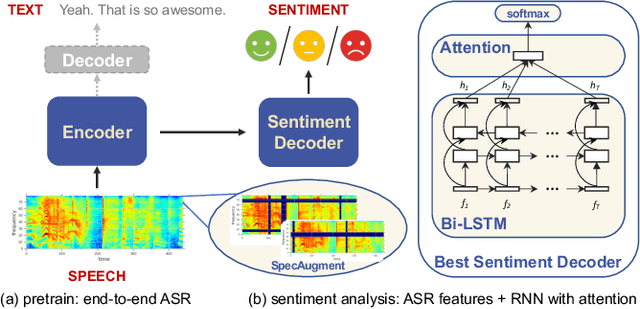

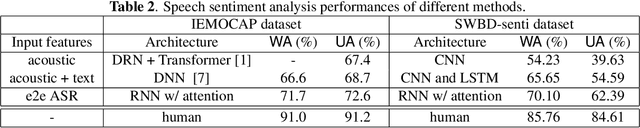

In this paper, we propose to use pre-trained features from end-to-end ASR models to solve the speech sentiment analysis problem as a down-stream task. We show that end-to-end ASR features, which integrate both acoustic and text information from speech, achieve promising results. We use RNN with self-attention as the sentiment classifier, which also provides an easy visualization through attention weights to help interpret model predictions. We use well benchmarked IEMOCAP dataset and a new large-scale sentiment analysis dataset SWBD-senti for evaluation. Our approach improves the-state-of-the-art accuracy on IEMOCAP from 66.6% to 71.7%, and achieves an accuracy of 70.10% on SWBD-senti with more than 49,500 utterances.
Product Image Recognition with Guidance Learning and Noisy Supervision
Jul 26, 2019


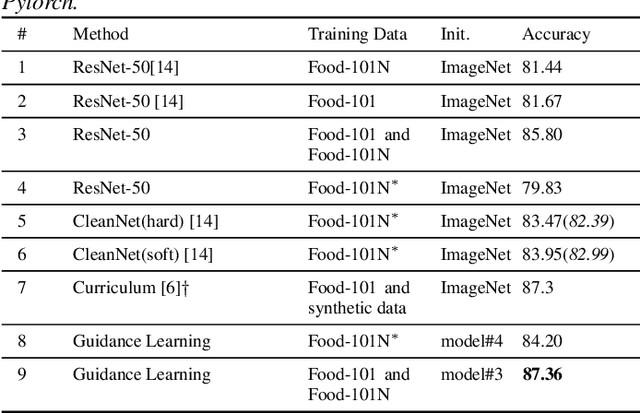
This paper considers recognizing products from daily photos, which is an important problem in real-world applications but also challenging due to background clutters, category diversities, noisy labels, etc. We address this problem by two contributions. First, we introduce a novel large-scale product image dataset, termed as Product-90. Instead of collecting product images by labor-and time-intensive image capturing, we take advantage of the web and download images from the reviews of several e-commerce websites where the images are casually captured by consumers. Labels are assigned automatically by the categories of e-commerce websites. Totally the Product-90 consists of more than 140K images with 90 categories. Due to the fact that consumers may upload unrelated images, it is inevitable that our Product-90 introduces noisy labels. As the second contribution, we develop a simple yet efficient \textit{guidance learning} (GL) method for training convolutional neural networks (CNNs) with noisy supervision. The GL method first trains an initial teacher network with the full noisy dataset, and then trains a target/student network with both large-scale noisy set and small manually-verified clean set in a multi-task manner. Specifically, in the stage of student network training, the large-scale noisy data is supervised by its guidance knowledge which is the combination of its given noisy label and the soften label from the teacher network. We conduct extensive experiments on our Products-90 and public datasets, namely Food101, Food-101N, and Clothing1M. Our guidance learning method achieves performance superior to state-of-the-art methods on these datasets.