 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInput Length Matters: An Empirical Study Of RNN-T And MWER Training For Long-form Telephony Speech Recognition
Oct 08, 2021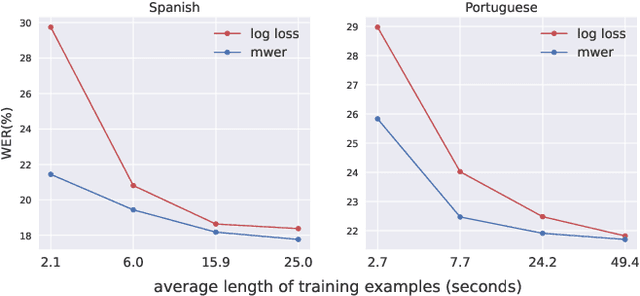


End-to-end models have achieved state-of-the-art results on several automatic speech recognition tasks. However, they perform poorly when evaluated on long-form data, e.g., minutes long conversational telephony audio. One reason the model fails on long-form speech is that it has only seen short utterances during training. This paper presents an empirical study on the effect of training utterance length on the word error rate (WER) for RNN-transducer (RNN-T) model. We compare two widely used training objectives, log loss (or RNN-T loss) and minimum word error rate (MWER) loss. We conduct experiments on telephony datasets in four languages. Our experiments show that for both losses, the WER on long-form speech reduces substantially as the training utterance length increases. The average relative WER gain is 15.7% for log loss and 8.8% for MWER loss. When training on short utterances, MWER loss leads to a lower WER than the log loss. Such difference between the two losses diminishes when the input length increases.
Bridging the gap between streaming and non-streaming ASR systems bydistilling ensembles of CTC and RNN-T models
Apr 25, 2021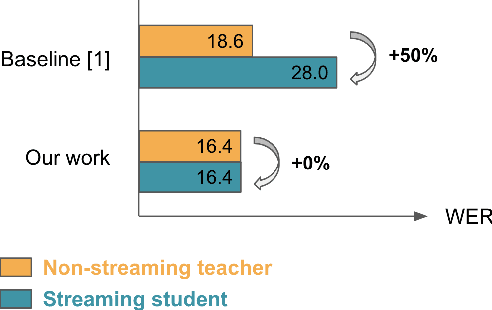
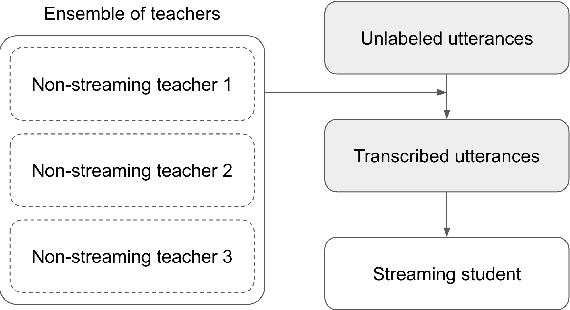

Streaming end-to-end automatic speech recognition (ASR) systems are widely used in everyday applications that require transcribing speech to text in real-time. Their minimal latency makes them suitable for such tasks. Unlike their non-streaming counterparts, streaming models are constrained to be causal with no future context and suffer from higher word error rates (WER). To improve streaming models, a recent study [1] proposed to distill a non-streaming teacher model on unsupervised utterances, and then train a streaming student using the teachers' predictions. However, the performance gap between teacher and student WERs remains high. In this paper, we aim to close this gap by using a diversified set of non-streaming teacher models and combining them using Recognizer Output Voting Error Reduction (ROVER). In particular, we show that, despite being weaker than RNN-T models, CTC models are remarkable teachers. Further, by fusing RNN-T and CTC models together, we build the strongest teachers. The resulting student models drastically improve upon streaming models of previous work [1]: the WER decreases by 41% on Spanish, 27% on Portuguese, and 13% on French.
Improving Streaming Automatic Speech Recognition With Non-Streaming Model Distillation On Unsupervised Data
Oct 22, 2020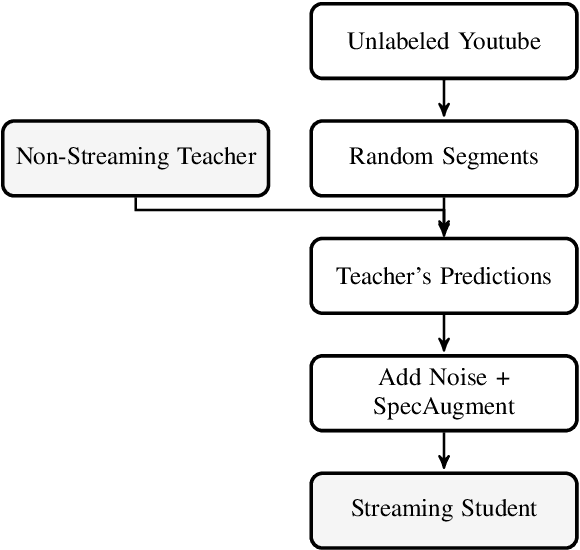
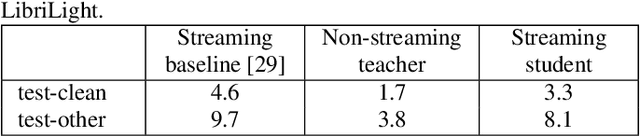
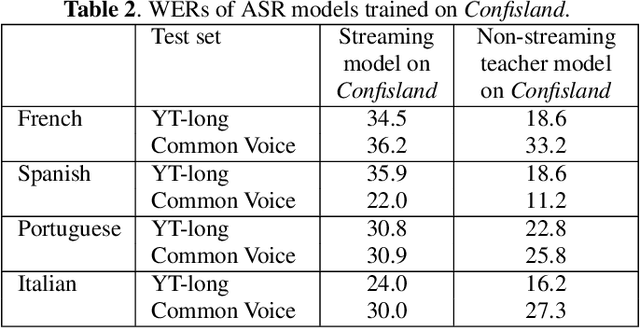
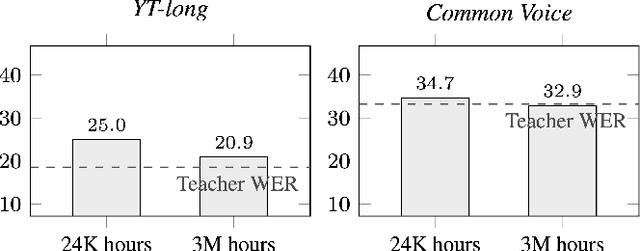
Streaming end-to-end automatic speech recognition (ASR) models are widely used on smart speakers and on-device applications. Since these models are expected to transcribe speech with minimal latency, they are constrained to be causal with no future context, compared to their non-streaming counterparts. Consequently, streaming models usually perform worse than non-streaming models. We propose a novel and effective learning method by leveraging a non-streaming ASR model as a teacher to generate transcripts on an arbitrarily large data set, which is then used to distill knowledge into streaming ASR models. This way, we scale the training of streaming models to up to 3 million hours of YouTube audio. Experiments show that our approach can significantly reduce the word error rate (WER) of RNNT models not only on LibriSpeech but also on YouTube data in four languages. For example, in French, we are able to reduce the WER by 16.4% relatively to a baseline streaming model by leveraging a non-streaming teacher model trained on the same amount of labeled data as the baseline.