 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved LLM Agents for Financial Document Question Answering
Jun 10, 2025
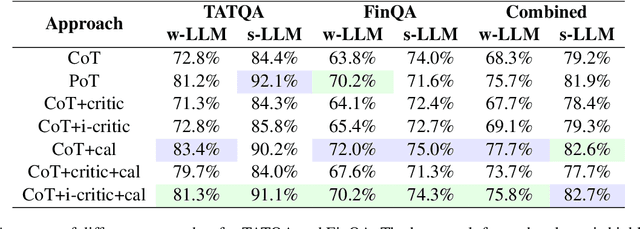
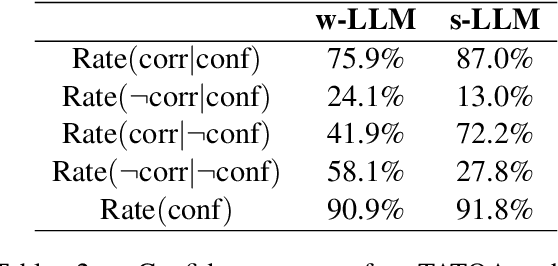
Large language models (LLMs) have shown impressive capabilities on numerous natural language processing tasks. However, LLMs still struggle with numerical question answering for financial documents that include tabular and textual data. Recent works have showed the effectiveness of critic agents (i.e., self-correction) for this task given oracle labels. Building upon this framework, this paper examines the effectiveness of the traditional critic agent when oracle labels are not available, and show, through experiments, that this critic agent's performance deteriorates in this scenario. With this in mind, we present an improved critic agent, along with the calculator agent which outperforms the previous state-of-the-art approach (program-of-thought) and is safer. Furthermore, we investigate how our agents interact with each other, and how this interaction affects their performance.
Zeroth-Order Optimization Finds Flat Minima
Jun 05, 2025Zeroth-order methods are extensively used in machine learning applications where gradients are infeasible or expensive to compute, such as black-box attacks, reinforcement learning, and language model fine-tuning. Existing optimization theory focuses on convergence to an arbitrary stationary point, but less is known on the implicit regularization that provides a fine-grained characterization on which particular solutions are finally reached. We show that zeroth-order optimization with the standard two-point estimator favors solutions with small trace of Hessian, which is widely used in previous work to distinguish between sharp and flat minima. We further provide convergence rates of zeroth-order optimization to approximate flat minima for convex and sufficiently smooth functions, where flat minima are defined as the minimizers that achieve the smallest trace of Hessian among all optimal solutions. Experiments on binary classification tasks with convex losses and language model fine-tuning support our theoretical findings.
How Is LLM Reasoning Distracted by Irrelevant Context? An Analysis Using a Controlled Benchmark
May 24, 2025We introduce Grade School Math with Distracting Context (GSM-DC), a synthetic benchmark to evaluate Large Language Models' (LLMs) reasoning robustness against systematically controlled irrelevant context (IC). GSM-DC constructs symbolic reasoning graphs with precise distractor injections, enabling rigorous, reproducible evaluation. Our experiments demonstrate that LLMs are significantly sensitive to IC, affecting both reasoning path selection and arithmetic accuracy. Additionally, training models with strong distractors improves performance in both in-distribution and out-of-distribution scenarios. We further propose a stepwise tree search guided by a process reward model, which notably enhances robustness in out-of-distribution conditions.
SubGCache: Accelerating Graph-based RAG with Subgraph-level KV Cache
May 19, 2025Graph-based retrieval-augmented generation (RAG) enables large language models (LLMs) to incorporate structured knowledge via graph retrieval as contextual input, enhancing more accurate and context-aware reasoning. We observe that for different queries, it could retrieve similar subgraphs as prompts, and thus we propose SubGCache, which aims to reduce inference latency by reusing computation across queries with similar structural prompts (i.e., subgraphs). Specifically, SubGCache clusters queries based on subgraph embeddings, constructs a representative subgraph for each cluster, and pre-computes the key-value (KV) cache of the representative subgraph. For each query with its retrieved subgraph within a cluster, it reuses the pre-computed KV cache of the representative subgraph of the cluster without computing the KV tensors again for saving computation. Experiments on two new datasets across multiple LLM backbones and graph-based RAG frameworks demonstrate that SubGCache consistently reduces inference latency with comparable and even improved generation quality, achieving up to 6.68$\times$ reduction in time-to-first-token (TTFT).
LoRA-Based Continual Learning with Constraints on Critical Parameter Changes
Apr 18, 2025LoRA-based continual learning represents a promising avenue for leveraging pre-trained models in downstream continual learning tasks. Recent studies have shown that orthogonal LoRA tuning effectively mitigates forgetting. However, this work unveils that under orthogonal LoRA tuning, the critical parameters for pre-tasks still change notably after learning post-tasks. To address this problem, we directly propose freezing the most critical parameter matrices in the Vision Transformer (ViT) for pre-tasks before learning post-tasks. In addition, building on orthogonal LoRA tuning, we propose orthogonal LoRA composition (LoRAC) based on QR decomposition, which may further enhance the plasticity of our method. Elaborate ablation studies and extensive comparisons demonstrate the effectiveness of our proposed method. Our results indicate that our method achieves state-of-the-art (SOTA) performance on several well-known continual learning benchmarks. For instance, on the Split CIFAR-100 dataset, our method shows a 6.35\% improvement in accuracy and a 3.24\% reduction in forgetting compared to previous methods. Our code is available at https://github.com/learninginvision/LoRAC-IPC.
Saga: Capturing Multi-granularity Semantics from Massive Unlabelled IMU Data for User Perception
Apr 16, 2025Inertial measurement units (IMUs), have been prevalently used in a wide range of mobile perception applications such as activity recognition and user authentication, where a large amount of labelled data are normally required to train a satisfactory model. However, it is difficult to label micro-activities in massive IMU data due to the hardness of understanding raw IMU data and the lack of ground truth. In this paper, we propose a novel fine-grained user perception approach, called Saga, which only needs a small amount of labelled IMU data to achieve stunning user perception accuracy. The core idea of Saga is to first pre-train a backbone feature extraction model, utilizing the rich semantic information of different levels embedded in the massive unlabelled IMU data. Meanwhile, for a specific downstream user perception application, Bayesian Optimization is employed to determine the optimal weights for pre-training tasks involving different semantic levels. We implement Saga on five typical mobile phones and evaluate Saga on three typical tasks on three IMU datasets. Results show that when only using about 100 training samples per class, Saga can achieve over 90% accuracy of the full-fledged model trained on over ten thousands training samples with no additional system overhead.
LLMs Can Achieve High-quality Simultaneous Machine Translation as Efficiently as Offline
Apr 13, 2025



When the complete source sentence is provided, Large Language Models (LLMs) perform excellently in offline machine translation even with a simple prompt "Translate the following sentence from [src lang] into [tgt lang]:". However, in many real scenarios, the source tokens arrive in a streaming manner and simultaneous machine translation (SiMT) is required, then the efficiency and performance of decoder-only LLMs are significantly limited by their auto-regressive nature. To enable LLMs to achieve high-quality SiMT as efficiently as offline translation, we propose a novel paradigm that includes constructing supervised fine-tuning (SFT) data for SiMT, along with new training and inference strategies. To replicate the token input/output stream in SiMT, the source and target tokens are rearranged into an interleaved sequence, separated by special tokens according to varying latency requirements. This enables powerful LLMs to learn read and write operations adaptively, based on varying latency prompts, while still maintaining efficient auto-regressive decoding. Experimental results show that, even with limited SFT data, our approach achieves state-of-the-art performance across various SiMT benchmarks, and preserves the original abilities of offline translation. Moreover, our approach generalizes well to document-level SiMT setting without requiring specific fine-tuning, even beyond the offline translation model.
A Multi-Agent Framework with Automated Decision Rule Optimization for Cross-Domain Misinformation Detection
Mar 30, 2025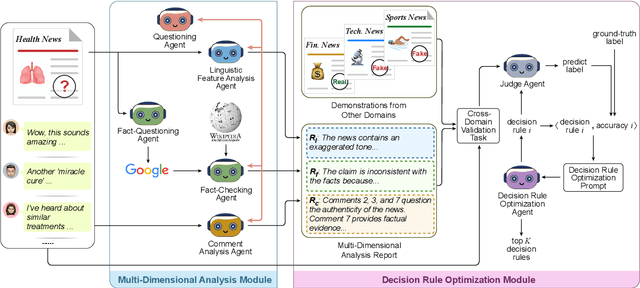
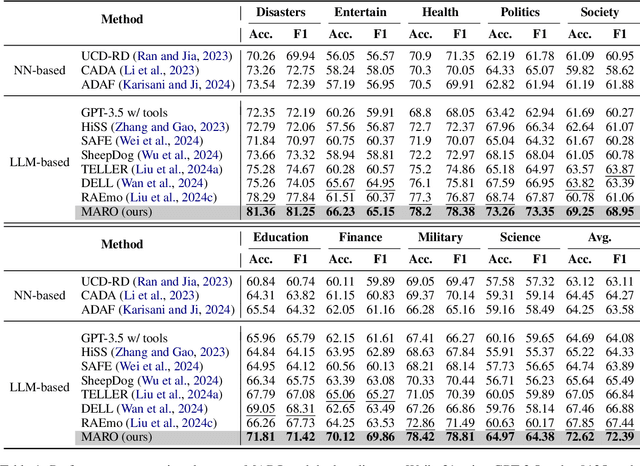
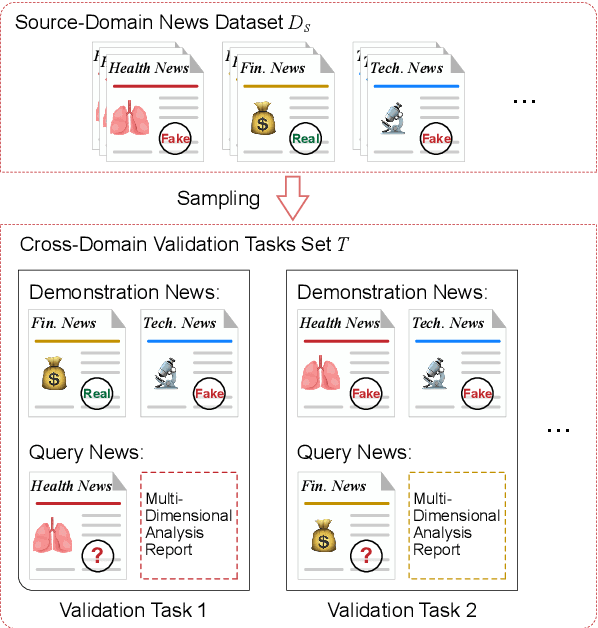
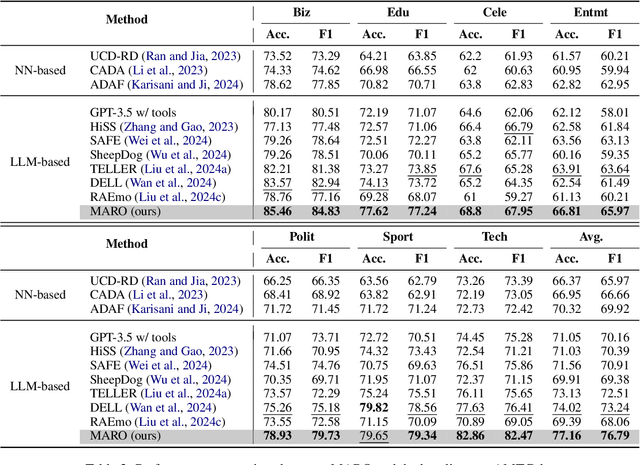
Misinformation spans various domains, but detection methods trained on specific domains often perform poorly when applied to others. With the rapid development of Large Language Models (LLMs), researchers have begun to utilize LLMs for cross-domain misinformation detection. However, existing LLM-based methods often fail to adequately analyze news in the target domain, limiting their detection capabilities. More importantly, these methods typically rely on manually designed decision rules, which are limited by domain knowledge and expert experience, thus limiting the generalizability of decision rules to different domains. To address these issues, we propose a MultiAgent Framework for cross-domain misinformation detection with Automated Decision Rule Optimization (MARO). Under this framework, we first employs multiple expert agents to analyze target-domain news. Subsequently, we introduce a question-reflection mechanism that guides expert agents to facilitate higherquality analysis. Furthermore, we propose a decision rule optimization approach based on carefully-designed cross-domain validation tasks to iteratively enhance the effectiveness of decision rules in different domains. Experimental results and in-depth analysis on commonlyused datasets demonstrate that MARO achieves significant improvements over existing methods.
Optimizing Case-Based Reasoning System for Functional Test Script Generation with Large Language Models
Mar 26, 2025In this work, we explore the potential of large language models (LLMs) for generating functional test scripts, which necessitates understanding the dynamically evolving code structure of the target software. To achieve this, we propose a case-based reasoning (CBR) system utilizing a 4R cycle (i.e., retrieve, reuse, revise, and retain), which maintains and leverages a case bank of test intent descriptions and corresponding test scripts to facilitate LLMs for test script generation. To improve user experience further, we introduce Re4, an optimization method for the CBR system, comprising reranking-based retrieval finetuning and reinforced reuse finetuning. Specifically, we first identify positive examples with high semantic and script similarity, providing reliable pseudo-labels for finetuning the retriever model without costly labeling. Then, we apply supervised finetuning, followed by a reinforcement learning finetuning stage, to align LLMs with our production scenarios, ensuring the faithful reuse of retrieved cases. Extensive experimental results on two product development units from Huawei Datacom demonstrate the superiority of the proposed CBR+Re4. Notably, we also show that the proposed Re4 method can help alleviate the repetitive generation issues with LLMs.
TimeZero: Temporal Video Grounding with Reasoning-Guided LVLM
Mar 17, 2025We introduce TimeZero, a reasoning-guided LVLM designed for the temporal video grounding (TVG) task. This task requires precisely localizing relevant video segments within long videos based on a given language query. TimeZero tackles this challenge by extending the inference process, enabling the model to reason about video-language relationships solely through reinforcement learning. To evaluate the effectiveness of TimeZero, we conduct experiments on two benchmarks, where TimeZero achieves state-of-the-art performance on Charades-STA. Code is available at https://github.com/www-Ye/TimeZero.