 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMetrics: Approximate Human Judgements with Automatically Generated Evaluators
Dec 19, 2025Evaluating user-facing AI applications remains a central challenge, especially in open-ended domains such as travel planning, clinical note generation, or dialogue. The gold standard is user feedback (e.g., thumbs up/down) or behavioral signals (e.g., retention), but these are often scarce in prototypes and research projects, or too-slow to use for system optimization. We present AutoMetrics, a framework for synthesizing evaluation metrics under low-data constraints. AutoMetrics combines retrieval from MetricBank, a collection of 48 metrics we curate, with automatically generated LLM-as-a-Judge criteria informed by lightweight human feedback. These metrics are composed via regression to maximize correlation with human signal. AutoMetrics takes you from expensive measures to interpretable automatic metrics. Across 5 diverse tasks, AutoMetrics improves Kendall correlation with human ratings by up to 33.4% over LLM-as-a-Judge while requiring fewer than 100 feedback points. We show that AutoMetrics can be used as a proxy reward to equal effect as a verifiable reward. We release the full AutoMetrics toolkit and MetricBank to accelerate adaptive evaluation of LLM applications.
Improved LLM Agents for Financial Document Question Answering
Jun 10, 2025
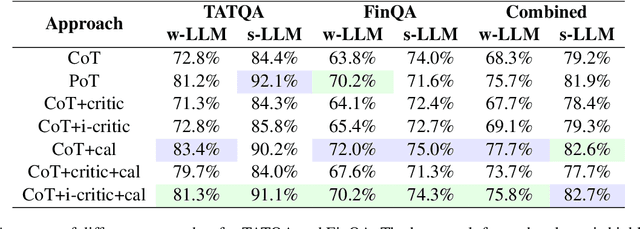
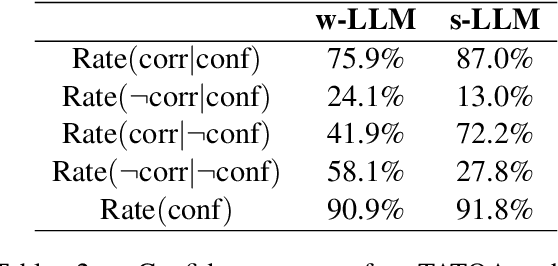
Large language models (LLMs) have shown impressive capabilities on numerous natural language processing tasks. However, LLMs still struggle with numerical question answering for financial documents that include tabular and textual data. Recent works have showed the effectiveness of critic agents (i.e., self-correction) for this task given oracle labels. Building upon this framework, this paper examines the effectiveness of the traditional critic agent when oracle labels are not available, and show, through experiments, that this critic agent's performance deteriorates in this scenario. With this in mind, we present an improved critic agent, along with the calculator agent which outperforms the previous state-of-the-art approach (program-of-thought) and is safer. Furthermore, we investigate how our agents interact with each other, and how this interaction affects their performance.
Flexible and Efficient Drift Detection without Labels
Jun 10, 2025



Machine learning models are being increasingly used to automate decisions in almost every domain, and ensuring the performance of these models is crucial for ensuring high quality machine learning enabled services. Ensuring concept drift is detected early is thus of the highest importance. A lot of research on concept drift has focused on the supervised case that assumes the true labels of supervised tasks are available immediately after making predictions. Controlling for false positives while monitoring the performance of predictive models used to make inference from extremely large datasets periodically, where the true labels are not instantly available, becomes extremely challenging. We propose a flexible and efficient concept drift detection algorithm that uses classical statistical process control in a label-less setting to accurately detect concept drifts. We shown empirically that under computational constraints, our approach has better statistical power than previous known methods. Furthermore, we introduce a new drift detection framework to model the scenario of detecting drift (without labels) given prior detections, and show our how our drift detection algorithm can be incorporated effectively into this framework. We demonstrate promising performance via numerical simulations.
An Ensemble-Based Deep Framework for Estimating Thermo-Chemical State Variables from Flamelet Generated Manifolds
Nov 25, 2022



Complete computation of turbulent combustion flow involves two separate steps: mapping reaction kinetics to low-dimensional manifolds and looking-up this approximate manifold during CFD run-time to estimate the thermo-chemical state variables. In our previous work, we showed that using a deep architecture to learn the two steps jointly, instead of separately, is 73% more accurate at estimating the source energy, a key state variable, compared to benchmarks and can be integrated within a DNS turbulent combustion framework. In their natural form, such deep architectures do not allow for uncertainty quantification of the quantities of interest: the source energy and key species source terms. In this paper, we expand on such architectures, specifically ChemTab, by introducing deep ensembles to approximate the posterior distribution of the quantities of interest. We investigate two strategies of creating these ensemble models: one that keeps the flamelet origin information (Flamelets strategy) and one that ignores the origin and considers all the data independently (Points strategy). To train these models we used flamelet data generated by the GRI--Mech 3.0 methane mechanism, which consists of 53 chemical species and 325 reactions. Our results demonstrate that the Flamelets strategy is superior in terms of the absolute prediction error for the quantities of interest, but is reliant on the types of flamelets used to train the ensemble. The Points strategy is best at capturing the variability of the quantities of interest, independent of the flamelet types. We conclude that, overall, ChemTab Deep Ensembles allows for a more accurate representation of the source energy and key species source terms, compared to the model without these modifications.
Physics Informed Machine Learning for Chemistry Tabulation
Nov 06, 2022Modeling of turbulent combustion system requires modeling the underlying chemistry and the turbulent flow. Solving both systems simultaneously is computationally prohibitive. Instead, given the difference in scales at which the two sub-systems evolve, the two sub-systems are typically (re)solved separately. Popular approaches such as the Flamelet Generated Manifolds (FGM) use a two-step strategy where the governing reaction kinetics are pre-computed and mapped to a low-dimensional manifold, characterized by a few reaction progress variables (model reduction) and the manifold is then ``looked-up'' during the runtime to estimate the high-dimensional system state by the flow system. While existing works have focused on these two steps independently, in this work we show that joint learning of the progress variables and the look--up model, can yield more accurate results. We build on the base formulation and implementation ChemTab to include the dynamically generated Themochemical State Variables (Lower Dimensional Dynamic Source Terms). We discuss the challenges in the implementation of this deep neural network architecture and experimentally demonstrate it's superior performance.
ChemTab: A Physics Guided Chemistry Modeling Framework
Feb 20, 2022Modeling of turbulent combustion system requires modeling the underlying chemistry and the turbulent flow. Solving both systems simultaneously is computationally prohibitive. Instead, given the difference in scales at which the two sub-systems evolve, the two sub-systems are typically (re)solved separately. Popular approaches such as the Flamelet Generated Manifolds (FGM) use a two-step strategy where the governing reaction kinetics are pre-computed and mapped to a low-dimensional manifold, characterized by a few reaction progress variables (model reduction) and the manifold is then "looked-up" during the run-time to estimate the high-dimensional system state by the flow system. While existing works have focused on these two steps independently, we show that joint learning of the progress variables and the look-up model, can yield more accurate results. We propose a deep neural network architecture, called ChemTab, customized for the joint learning task and experimentally demonstrate its superiority over existing state-of-the-art methods.