 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOTE-RCNN: NOise Tolerant Ensemble RCNN for Semi-Supervised Object Detection
Dec 01, 2018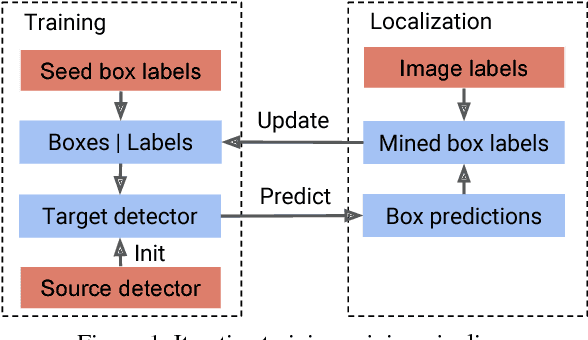
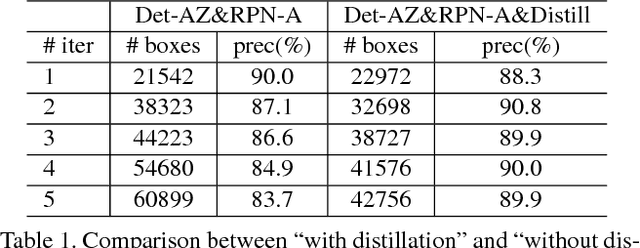

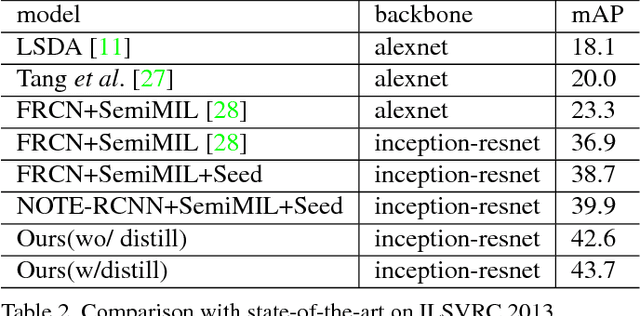
The labeling cost of large number of bounding boxes is one of the main challenges for training modern object detectors. To reduce the dependence on expensive bounding box annotations, we propose a new semi-supervised object detection formulation, in which a few seed box level annotations and a large scale of image level annotations are used to train the detector. We adopt a training-mining framework, which is widely used in weakly supervised object detection tasks. However, the mining process inherently introduces various kinds of labelling noises: false negatives, false positives and inaccurate boundaries, which can be harmful for training the standard object detectors (e.g. Faster RCNN). We propose a novel NOise Tolerant Ensemble RCNN (NOTE-RCNN) object detector to handle such noisy labels. Comparing to standard Faster RCNN, it contains three highlights: an ensemble of two classification heads and a distillation head to avoid overfitting on noisy labels and improve the mining precision, masking the negative sample loss in box predictor to avoid the harm of false negative labels, and training box regression head only on seed annotations to eliminate the harm from inaccurate boundaries of mined bounding boxes. We evaluate the methods on ILSVRC 2013 and MSCOCO 2017 dataset; we observe that the detection accuracy consistently improves as we iterate between mining and training steps, and state-of-the-art performance is achieved.
AMC: AutoML for Model Compression and Acceleration on Mobile Devices
Aug 26, 2018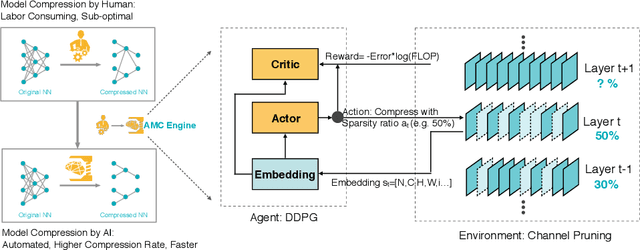

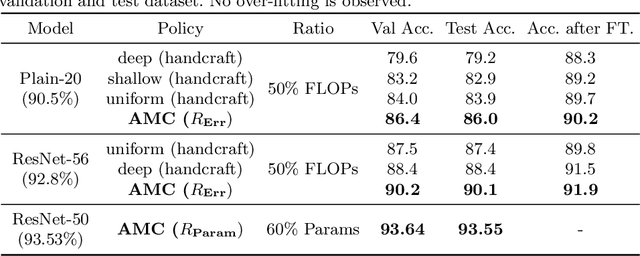
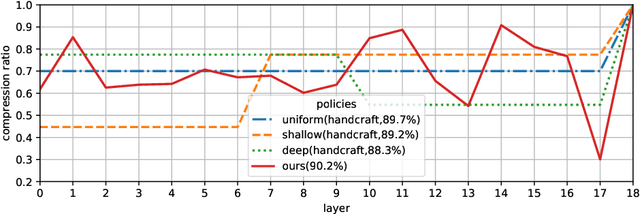
Model compression is a critical technique to efficiently deploy neural network models on mobile devices which have limited computation resources and tight power budgets. Conventional model compression techniques rely on hand-crafted heuristics and rule-based policies that require domain experts to explore the large design space trading off among model size, speed, and accuracy, which is usually sub-optimal and time-consuming. In this paper, we propose AutoML for Model Compression (AMC) which leverage reinforcement learning to provide the model compression policy. This learning-based compression policy outperforms conventional rule-based compression policy by having higher compression ratio, better preserving the accuracy and freeing human labor. Under 4x FLOPs reduction, we achieved 2.7% better accuracy than the hand- crafted model compression policy for VGG-16 on ImageNet. We applied this automated, push-the-button compression pipeline to MobileNet and achieved 1.81x speedup of measured inference latency on an Android phone and 1.43x speedup on the Titan XP GPU, with only 0.1% loss of ImageNet Top-1 accuracy.
MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels
Aug 13, 2018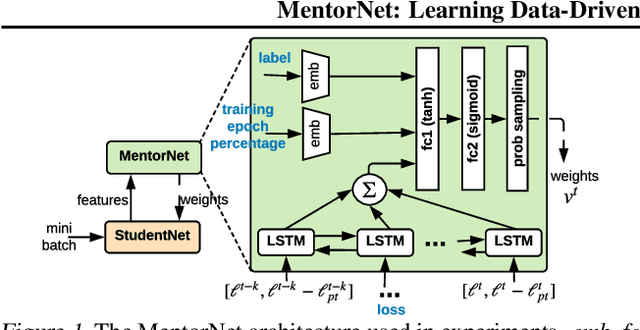
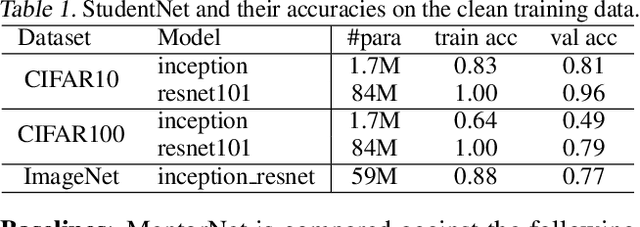

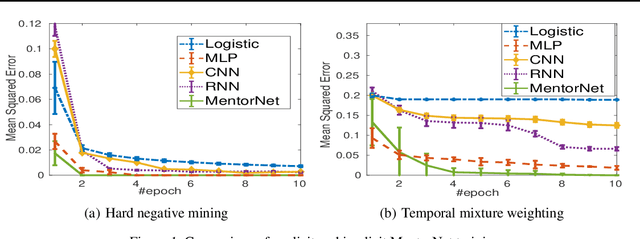
Recent deep networks are capable of memorizing the entire data even when the labels are completely random. To overcome the overfitting on corrupted labels, we propose a novel technique of learning another neural network, called MentorNet, to supervise the training of the base deep networks, namely, StudentNet. During training, MentorNet provides a curriculum (sample weighting scheme) for StudentNet to focus on the sample the label of which is probably correct. Unlike the existing curriculum that is usually predefined by human experts, MentorNet learns a data-driven curriculum dynamically with StudentNet. Experimental results demonstrate that our approach can significantly improve the generalization performance of deep networks trained on corrupted training data. Notably, to the best of our knowledge, we achieve the best-published result on WebVision, a large benchmark containing 2.2 million images of real-world noisy labels. The code are at https://github.com/google/mentornet
Progressive Neural Architecture Search
Jul 26, 2018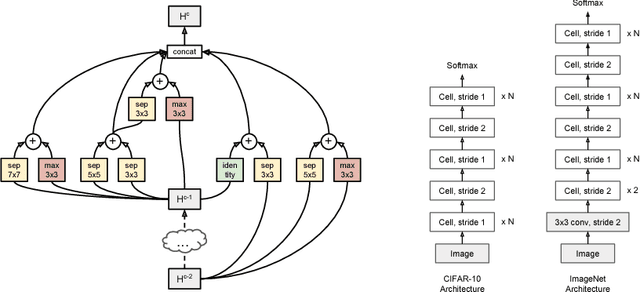
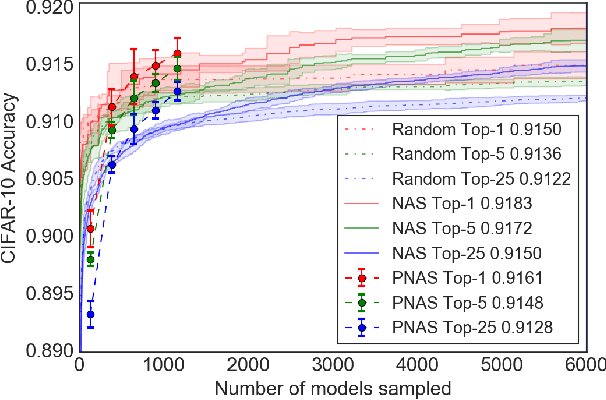

We propose a new method for learning the structure of convolutional neural networks (CNNs) that is more efficient than recent state-of-the-art methods based on reinforcement learning and evolutionary algorithms. Our approach uses a sequential model-based optimization (SMBO) strategy, in which we search for structures in order of increasing complexity, while simultaneously learning a surrogate model to guide the search through structure space. Direct comparison under the same search space shows that our method is up to 5 times more efficient than the RL method of Zoph et al. (2018) in terms of number of models evaluated, and 8 times faster in terms of total compute. The structures we discover in this way achieve state of the art classification accuracies on CIFAR-10 and ImageNet.
Thoracic Disease Identification and Localization with Limited Supervision
Jun 20, 2018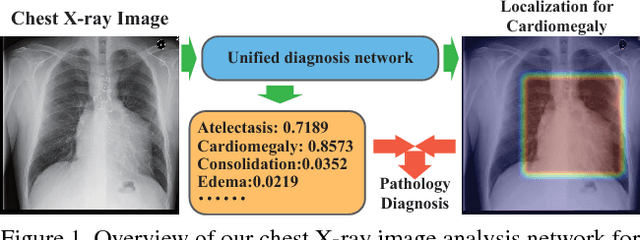

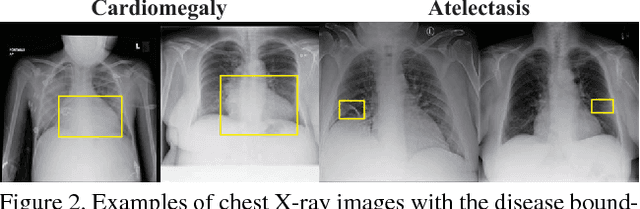
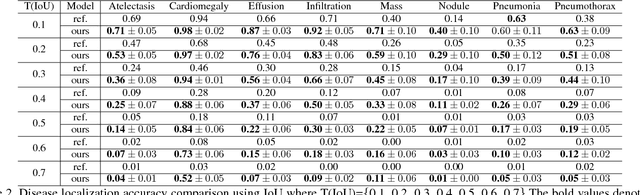
Accurate identification and localization of abnormalities from radiology images play an integral part in clinical diagnosis and treatment planning. Building a highly accurate prediction model for these tasks usually requires a large number of images manually annotated with labels and finding sites of abnormalities. In reality, however, such annotated data are expensive to acquire, especially the ones with location annotations. We need methods that can work well with only a small amount of location annotations. To address this challenge, we present a unified approach that simultaneously performs disease identification and localization through the same underlying model for all images. We demonstrate that our approach can effectively leverage both class information as well as limited location annotation, and significantly outperforms the comparative reference baseline in both classification and localization tasks.
Focal Visual-Text Attention for Visual Question Answering
Jun 05, 2018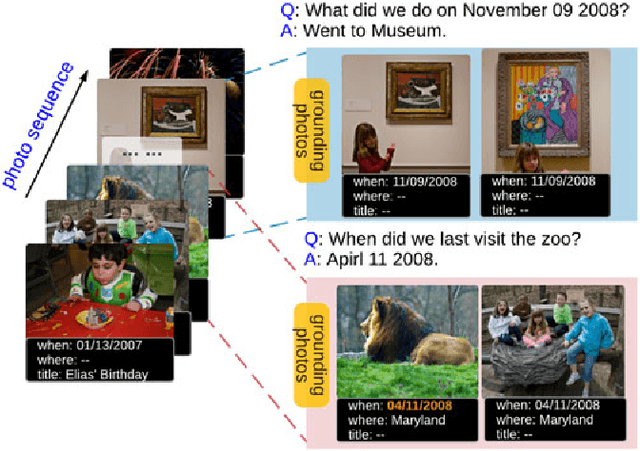
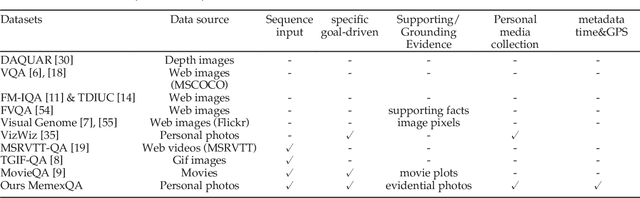
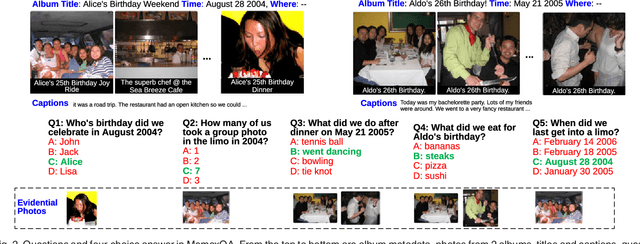

Recent insights on language and vision with neural networks have been successfully applied to simple single-image visual question answering. However, to tackle real-life question answering problems on multimedia collections such as personal photos, we have to look at whole collections with sequences of photos or videos. When answering questions from a large collection, a natural problem is to identify snippets to support the answer. In this paper, we describe a novel neural network called Focal Visual-Text Attention network (FVTA) for collective reasoning in visual question answering, where both visual and text sequence information such as images and text metadata are presented. FVTA introduces an end-to-end approach that makes use of a hierarchical process to dynamically determine what media and what time to focus on in the sequential data to answer the question. FVTA can not only answer the questions well but also provides the justifications which the system results are based upon to get the answers. FVTA achieves state-of-the-art performance on the MemexQA dataset and competitive results on the MovieQA dataset.
Iterative Visual Reasoning Beyond Convolutions
Mar 29, 2018
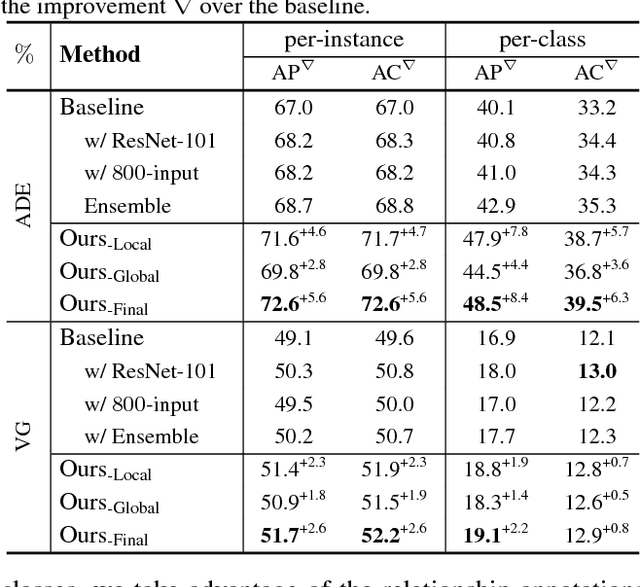
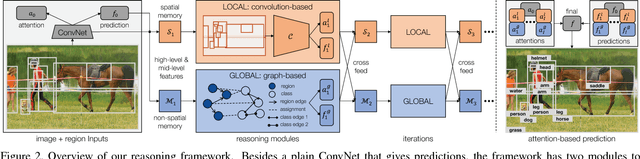
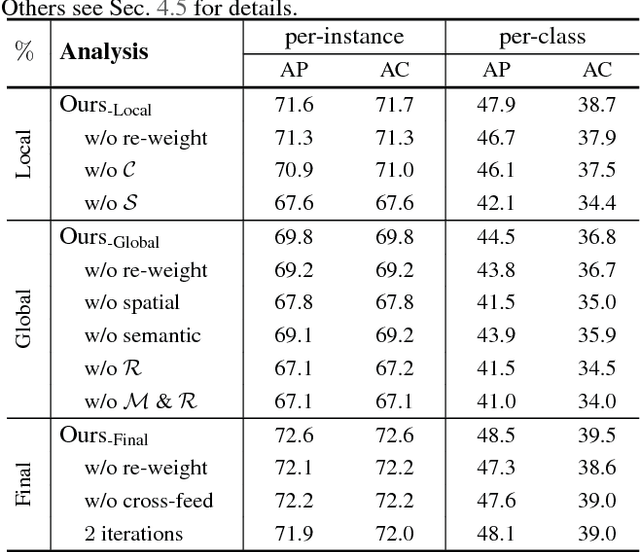
We present a novel framework for iterative visual reasoning. Our framework goes beyond current recognition systems that lack the capability to reason beyond stack of convolutions. The framework consists of two core modules: a local module that uses spatial memory to store previous beliefs with parallel updates; and a global graph-reasoning module. Our graph module has three components: a) a knowledge graph where we represent classes as nodes and build edges to encode different types of semantic relationships between them; b) a region graph of the current image where regions in the image are nodes and spatial relationships between these regions are edges; c) an assignment graph that assigns regions to classes. Both the local module and the global module roll-out iteratively and cross-feed predictions to each other to refine estimates. The final predictions are made by combining the best of both modules with an attention mechanism. We show strong performance over plain ConvNets, \eg achieving an $8.4\%$ absolute improvement on ADE measured by per-class average precision. Analysis also shows that the framework is resilient to missing regions for reasoning.
Attention-based Graph Neural Network for Semi-supervised Learning
Mar 10, 2018

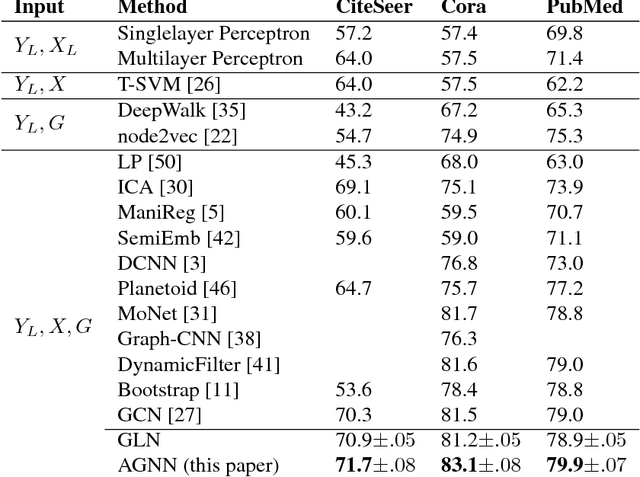

Recently popularized graph neural networks achieve the state-of-the-art accuracy on a number of standard benchmark datasets for graph-based semi-supervised learning, improving significantly over existing approaches. These architectures alternate between a propagation layer that aggregates the hidden states of the local neighborhood and a fully-connected layer. Perhaps surprisingly, we show that a linear model, that removes all the intermediate fully-connected layers, is still able to achieve a performance comparable to the state-of-the-art models. This significantly reduces the number of parameters, which is critical for semi-supervised learning where number of labeled examples are small. This in turn allows a room for designing more innovative propagation layers. Based on this insight, we propose a novel graph neural network that removes all the intermediate fully-connected layers, and replaces the propagation layers with attention mechanisms that respect the structure of the graph. The attention mechanism allows us to learn a dynamic and adaptive local summary of the neighborhood to achieve more accurate predictions. In a number of experiments on benchmark citation networks datasets, we demonstrate that our approach outperforms competing methods. By examining the attention weights among neighbors, we show that our model provides some interesting insights on how neighbors influence each other.
Dense Captioning with Joint Inference and Visual Context
Aug 07, 2017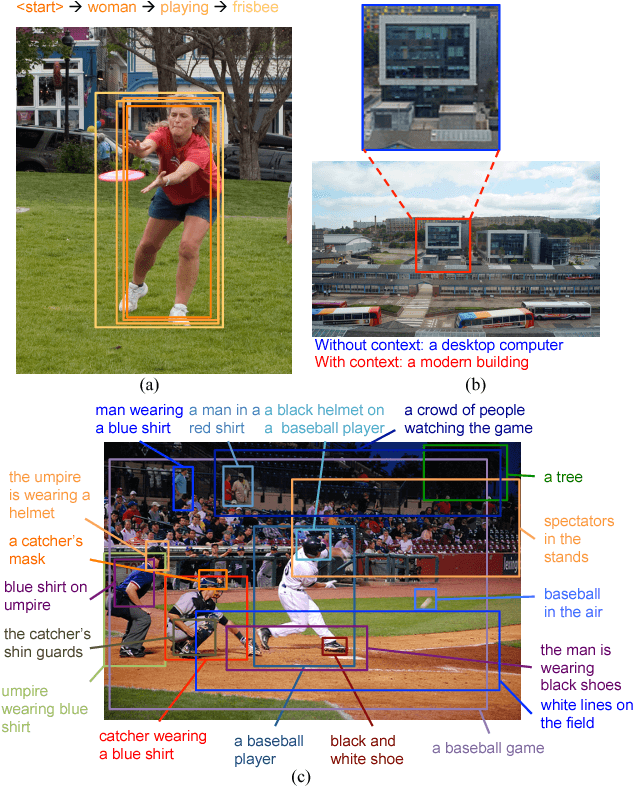

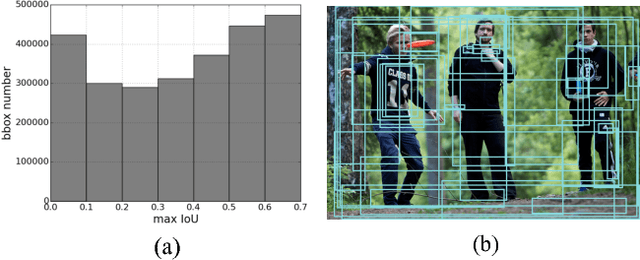

Dense captioning is a newly emerging computer vision topic for understanding images with dense language descriptions. The goal is to densely detect visual concepts (e.g., objects, object parts, and interactions between them) from images, labeling each with a short descriptive phrase. We identify two key challenges of dense captioning that need to be properly addressed when tackling the problem. First, dense visual concept annotations in each image are associated with highly overlapping target regions, making accurate localization of each visual concept challenging. Second, the large amount of visual concepts makes it hard to recognize each of them by appearance alone. We propose a new model pipeline based on two novel ideas, joint inference and context fusion, to alleviate these two challenges. We design our model architecture in a methodical manner and thoroughly evaluate the variations in architecture. Our final model, compact and efficient, achieves state-of-the-art accuracy on Visual Genome for dense captioning with a relative gain of 73\% compared to the previous best algorithm. Qualitative experiments also reveal the semantic capabilities of our model in dense captioning.
Deep Reinforcement Learning-based Image Captioning with Embedding Reward
Apr 12, 2017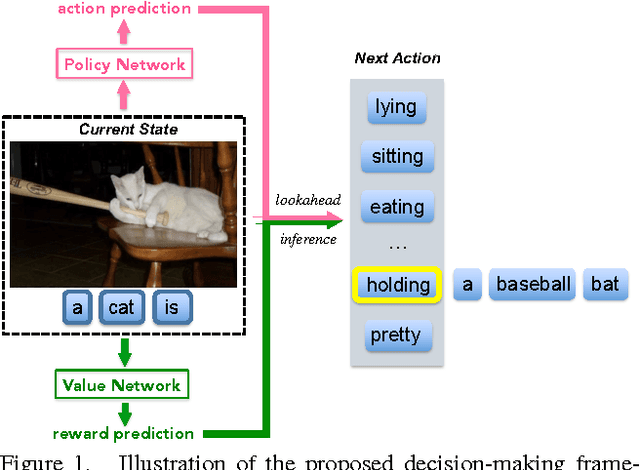
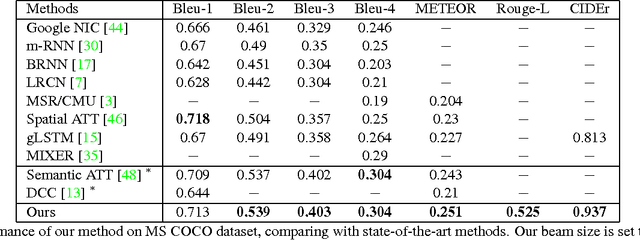
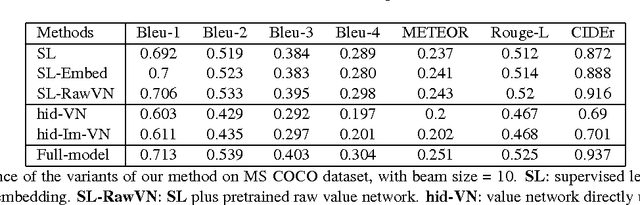
Image captioning is a challenging problem owing to the complexity in understanding the image content and diverse ways of describing it in natural language. Recent advances in deep neural networks have substantially improved the performance of this task. Most state-of-the-art approaches follow an encoder-decoder framework, which generates captions using a sequential recurrent prediction model. However, in this paper, we introduce a novel decision-making framework for image captioning. We utilize a "policy network" and a "value network" to collaboratively generate captions. The policy network serves as a local guidance by providing the confidence of predicting the next word according to the current state. Additionally, the value network serves as a global and lookahead guidance by evaluating all possible extensions of the current state. In essence, it adjusts the goal of predicting the correct words towards the goal of generating captions similar to the ground truth captions. We train both networks using an actor-critic reinforcement learning model, with a novel reward defined by visual-semantic embedding. Extensive experiments and analyses on the Microsoft COCO dataset show that the proposed framework outperforms state-of-the-art approaches across different evaluation metrics.