 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXEmoGPT: An Explainable Multimodal Emotion Recognition Framework with Cue-Level Perception and Reasoning
Feb 05, 2026Explainable Multimodal Emotion Recognition plays a crucial role in applications such as human-computer interaction and social media analytics. However, current approaches struggle with cue-level perception and reasoning due to two main challenges: 1) general-purpose modality encoders are pretrained to capture global structures and general semantics rather than fine-grained emotional cues, resulting in limited sensitivity to emotional signals; and 2) available datasets usually involve a trade-off between annotation quality and scale, which leads to insufficient supervision for emotional cues and ultimately limits cue-level reasoning. Moreover, existing evaluation metrics are inadequate for assessing cue-level reasoning performance. To address these challenges, we propose eXplainable Emotion GPT (XEmoGPT), a novel EMER framework capable of both perceiving and reasoning over emotional cues. It incorporates two specialized modules: the Video Emotional Cue Bridge (VECB) and the Audio Emotional Cue Bridge (AECB), which enhance the video and audio encoders through carefully designed tasks for fine-grained emotional cue perception. To further support cue-level reasoning, we construct a large-scale dataset, EmoCue, designed to teach XEmoGPT how to reason over multimodal emotional cues. In addition, we introduce EmoCue-360, an automated metric that extracts and matches emotional cues using semantic similarity, and release EmoCue-Eval, a benchmark of 400 expert-annotated samples covering diverse emotional scenarios. Experimental results show that XEmoGPT achieves strong performance in both emotional cue perception and reasoning.
Objaverse++: Curated 3D Object Dataset with Quality Annotations
Apr 09, 2025This paper presents Objaverse++, a curated subset of Objaverse enhanced with detailed attribute annotations by human experts. Recent advances in 3D content generation have been driven by large-scale datasets such as Objaverse, which contains over 800,000 3D objects collected from the Internet. Although Objaverse represents the largest available 3D asset collection, its utility is limited by the predominance of low-quality models. To address this limitation, we manually annotate 10,000 3D objects with detailed attributes, including aesthetic quality scores, texture color classifications, multi-object composition flags, transparency characteristics, etc. Then, we trained a neural network capable of annotating the tags for the rest of the Objaverse dataset. Through experiments and a user study on generation results, we demonstrate that models pre-trained on our quality-focused subset achieve better performance than those trained on the larger dataset of Objaverse in image-to-3D generation tasks. In addition, by comparing multiple subsets of training data filtered by our tags, our results show that the higher the data quality, the faster the training loss converges. These findings suggest that careful curation and rich annotation can compensate for the raw dataset size, potentially offering a more efficient path to develop 3D generative models. We release our enhanced dataset of approximately 500,000 curated 3D models to facilitate further research on various downstream tasks in 3D computer vision. In the near future, we aim to extend our annotations to cover the entire Objaverse dataset.
Segment Anything Model for Road Network Graph Extraction
Mar 31, 2024



We propose SAM-Road, an adaptation of the Segment Anything Model (SAM) for extracting large-scale, vectorized road network graphs from satellite imagery. To predict graph geometry, we formulate it as a dense semantic segmentation task, leveraging the inherent strengths of SAM. The image encoder of SAM is fine-tuned to produce probability masks for roads and intersections, from which the graph vertices are extracted via simple non-maximum suppression. To predict graph topology, we designed a lightweight transformer-based graph neural network, which leverages the SAM image embeddings to estimate the edge existence probabilities between vertices. Our approach directly predicts the graph vertices and edges for large regions without expensive and complex post-processing heuristics, and is capable of building complete road network graphs spanning multiple square kilometers in a matter of seconds. With its simple, straightforward, and minimalist design, SAM-Road achieves comparable accuracy with the state-of-the-art method RNGDet++, while being 40 times faster on the City-scale dataset. We thus demonstrate the power of a foundational vision model when applied to a graph learning task. The code is available at https://github.com/htcr/sam_road.
EucliDreamer: Fast and High-Quality Texturing for 3D Models with Stable Diffusion Depth
Nov 27, 2023



This paper presents a novel method to generate textures for 3D models given text prompts and 3D meshes. Additional depth information is taken into account to perform the Score Distillation Sampling (SDS) process [28] with depth conditional Stable Diffusion [34]. We ran our model over the open-source dataset Objaverse [7] and conducted a user study to compare the results with those of various 3D texturing methods. We have shown that our model can generate more satisfactory results and produce various art styles for the same object. In addition, we achieved faster time when generating textures of comparable quality. We also conduct thorough ablation studies of how different factors may affect generation quality, including sampling steps, guidance scale, negative prompts, data augmentation, elevation range, and alternatives to SDS.
Fast and Interpretable Face Identification for Out-Of-Distribution Data Using Vision Transformers
Nov 06, 2023Most face identification approaches employ a Siamese neural network to compare two images at the image embedding level. Yet, this technique can be subject to occlusion (e.g. faces with masks or sunglasses) and out-of-distribution data. DeepFace-EMD (Phan et al. 2022) reaches state-of-the-art accuracy on out-of-distribution data by first comparing two images at the image level, and then at the patch level. Yet, its later patch-wise re-ranking stage admits a large $O(n^3 \log n)$ time complexity (for $n$ patches in an image) due to the optimal transport optimization. In this paper, we propose a novel, 2-image Vision Transformers (ViTs) that compares two images at the patch level using cross-attention. After training on 2M pairs of images on CASIA Webface (Yi et al. 2014), our model performs at a comparable accuracy as DeepFace-EMD on out-of-distribution data, yet at an inference speed more than twice as fast as DeepFace-EMD (Phan et al. 2022). In addition, via a human study, our model shows promising explainability through the visualization of cross-attention. We believe our work can inspire more explorations in using ViTs for face identification.
Pruning Very Deep Neural Network Channels for Efficient Inference
Nov 14, 2022



In this paper, we introduce a new channel pruning method to accelerate very deep convolutional neural networks. Given a trained CNN model, we propose an iterative two-step algorithm to effectively prune each layer, by a LASSO regression based channel selection and least square reconstruction. We further generalize this algorithm to multi-layer and multi-branch cases. Our method reduces the accumulated error and enhances the compatibility with various architectures. Our pruned VGG-16 achieves the state-of-the-art results by 5x speed-up along with only 0.3% increase of error. More importantly, our method is able to accelerate modern networks like ResNet, Xception and suffers only 1.4%, 1.0% accuracy loss under 2x speed-up respectively, which is significant. Our code has been made publicly available.
Motion Prediction in Visual Object Tracking
Jul 01, 2020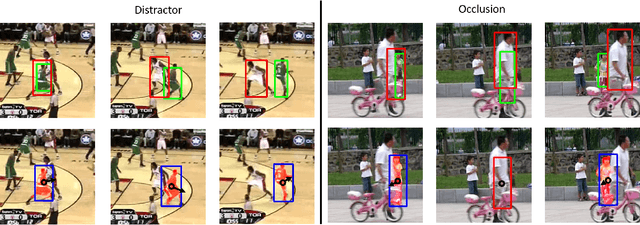



Visual object tracking (VOT) is an essential component for many applications, such as autonomous driving or assistive robotics. However, recent works tend to develop accurate systems based on more computationally expensive feature extractors for better instance matching. In contrast, this work addresses the importance of motion prediction in VOT. We use an off-the-shelf object detector to obtain instance bounding boxes. Then, a combination of camera motion decouple and Kalman filter is used for state estimation. Although our baseline system is a straightforward combination of standard methods, we obtain state-of-the-art results. Our method establishes new state-of-the-art performance on VOT (VOT-2016 and VOT-2018). Our proposed method improves the EAO on VOT-2016 from 0.472 of prior art to 0.505, from 0.410 to 0.431 on VOT-2018. To show the generalizability, we also test our method on video object segmentation (VOS: DAVIS-2016 and DAVIS-2017) and observe consistent improvement.
Epipolar Transformers
May 10, 2020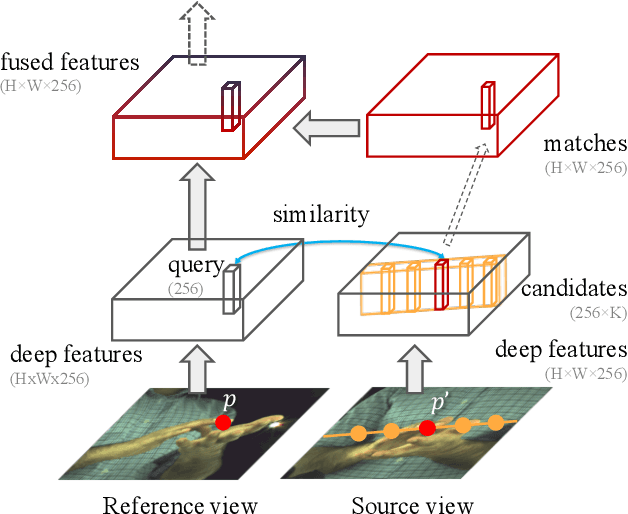
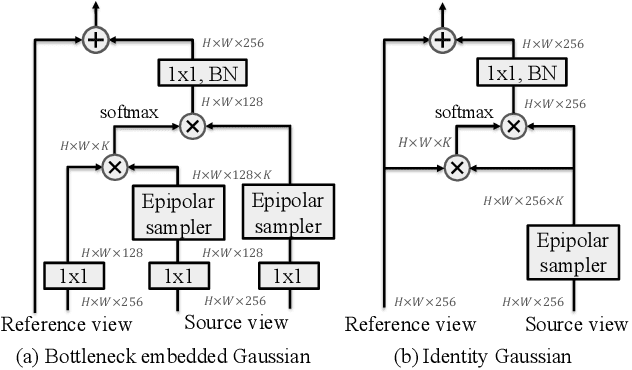


A common approach to localize 3D human joints in a synchronized and calibrated multi-view setup consists of two-steps: (1) apply a 2D detector separately on each view to localize joints in 2D, and (2) perform robust triangulation on 2D detections from each view to acquire the 3D joint locations. However, in step 1, the 2D detector is limited to solving challenging cases which could potentially be better resolved in 3D, such as occlusions and oblique viewing angles, purely in 2D without leveraging any 3D information. Therefore, we propose the differentiable "epipolar transformer", which enables the 2D detector to leverage 3D-aware features to improve 2D pose estimation. The intuition is: given a 2D location p in the current view, we would like to first find its corresponding point p' in a neighboring view, and then combine the features at p' with the features at p, thus leading to a 3D-aware feature at p. Inspired by stereo matching, the epipolar transformer leverages epipolar constraints and feature matching to approximate the features at p'. Experiments on InterHand and Human3.6M show that our approach has consistent improvements over the baselines. Specifically, in the condition where no external data is used, our Human3.6M model trained with ResNet-50 backbone and image size 256 x 256 outperforms state-of-the-art by 4.23 mm and achieves MPJPE 26.9 mm.
Deep Multivariate Mixture of Gaussians for Object Detection under Occlusion
Nov 24, 2019
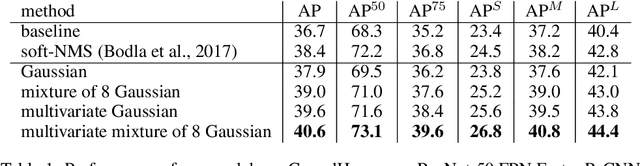

In this paper, we consider the problem of detecting object under occlusion. Most object detectors formulate bounding box regression as a unimodal task (i.e., regressing a single set of bounding box coordinates independently). However, we observe that the bounding box borders of an occluded object can have multiple plausible configurations. Also, the occluded bounding box borders have correlations with visible ones. Motivated by these two observations, we propose a deep multivariate mixture of Gaussians model for bounding box regression under occlusion. The mixture components potentially learn different configurations of an occluded part, and the covariances between variates help to learn the relationship between the occluded parts and the visible ones. Quantitatively, our model improves the AP of the baselines by 3.9% and 1.2% on CrowdHuman and MS-COCO respectively with almost no computational or memory overhead. Qualitatively, our model enjoys explainability since we can interpret the resulting bounding boxes via the covariance matrices and the mixture components.
Depth-wise Decomposition for Accelerating Separable Convolutions in Efficient Convolutional Neural Networks
Oct 21, 2019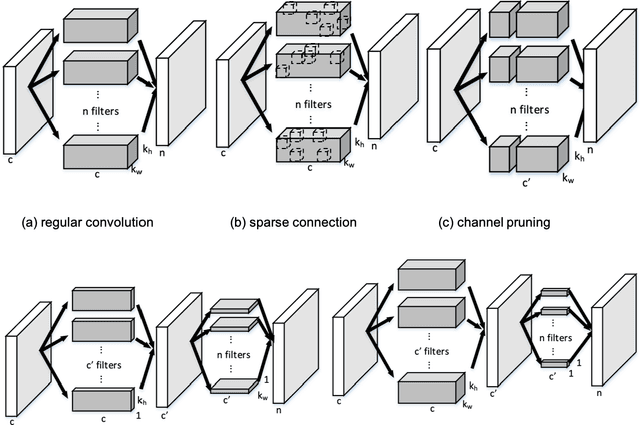
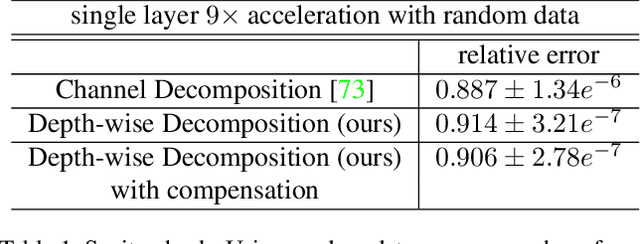


Very deep convolutional neural networks (CNNs) have been firmly established as the primary methods for many computer vision tasks. However, most state-of-the-art CNNs are large, which results in high inference latency. Recently, depth-wise separable convolution has been proposed for image recognition tasks on computationally limited platforms such as robotics and self-driving cars. Though it is much faster than its counterpart, regular convolution, accuracy is sacrificed. In this paper, we propose a novel decomposition approach based on SVD, namely depth-wise decomposition, for expanding regular convolutions into depthwise separable convolutions while maintaining high accuracy. We show our approach can be further generalized to the multi-channel and multi-layer cases, based on Generalized Singular Value Decomposition (GSVD) [59]. We conduct thorough experiments with the latest ShuffleNet V2 model [47] on both random synthesized dataset and a large-scale image recognition dataset: ImageNet [10]. Our approach outperforms channel decomposition [73] on all datasets. More importantly, our approach improves the Top-1 accuracy of ShuffleNet V2 by ~2%.