 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAceGRPO: Adaptive Curriculum Enhanced Group Relative Policy Optimization for Autonomous Machine Learning Engineering
Feb 08, 2026Autonomous Machine Learning Engineering (MLE) requires agents to perform sustained, iterative optimization over long horizons. While recent LLM-based agents show promise, current prompt-based agents for MLE suffer from behavioral stagnation due to frozen parameters. Although Reinforcement Learning (RL) offers a remedy, applying it to MLE is hindered by prohibitive execution latency and inefficient data selection. Recognizing these challenges, we propose AceGRPO with two core components: (1) Evolving Data Buffer that continuously repurposes execution traces into reusable training tasks, and (2) Adaptive Sampling guided by a Learnability Potential function, which dynamically prioritizes tasks at the agent's learning frontier to maximize learning efficiency. Leveraging AceGRPO, our trained Ace-30B model achieves a 100% valid submission rate on MLE-Bench-Lite, approaches the performance of proprietary frontier models, and outperforms larger open-source baselines (e.g., DeepSeek-V3.2), demonstrating robust capability for sustained iterative optimization. Code is available at https://github.com/yuzhu-cai/AceGRPO.
From Self-Evolving Synthetic Data to Verifiable-Reward RL: Post-Training Multi-turn Interactive Tool-Using Agents
Jan 30, 2026Interactive tool-using agents must solve real-world tasks via multi-turn interaction with both humans and external environments, requiring dialogue state tracking, multi-step tool execution, while following complex instructions. Post-training such agents is challenging because synthesis for high-quality multi-turn tool-use data is difficult to scale, and reinforcement learning (RL) could face noisy signals caused by user simulation, leading to degraded training efficiency. We propose a unified framework that combines a self-evolving data agent with verifier-based RL. Our system, EigenData, is a hierarchical multi-agent engine that synthesizes tool-grounded dialogues together with executable per-instance checkers, and improves generation reliability via closed-loop self-evolving process that updates prompts and workflow. Building on the synthetic data, we develop an RL recipe that first fine-tunes the user model and then applies GRPO-style training with trajectory-level group-relative advantages and dynamic filtering, yielding consistent improvements beyond SFT. Evaluated on tau^2-bench, our best model reaches 73.0% pass^1 on Airline and 98.3% pass^1 on Telecom, matching or exceeding frontier models. Overall, our results suggest a scalable pathway for bootstrapping complex tool-using behaviors without expensive human annotation.
Toward Ultra-Long-Horizon Agentic Science: Cognitive Accumulation for Machine Learning Engineering
Jan 15, 2026The advancement of artificial intelligence toward agentic science is currently bottlenecked by the challenge of ultra-long-horizon autonomy, the ability to sustain strategic coherence and iterative correction over experimental cycles spanning days or weeks. While Large Language Models (LLMs) have demonstrated prowess in short-horizon reasoning, they are easily overwhelmed by execution details in the high-dimensional, delayed-feedback environments of real-world research, failing to consolidate sparse feedback into coherent long-term guidance. Here, we present ML-Master 2.0, an autonomous agent that masters ultra-long-horizon machine learning engineering (MLE) which is a representative microcosm of scientific discovery. By reframing context management as a process of cognitive accumulation, our approach introduces Hierarchical Cognitive Caching (HCC), a multi-tiered architecture inspired by computer systems that enables the structural differentiation of experience over time. By dynamically distilling transient execution traces into stable knowledge and cross-task wisdom, HCC allows agents to decouple immediate execution from long-term experimental strategy, effectively overcoming the scaling limits of static context windows. In evaluations on OpenAI's MLE-Bench under 24-hour budgets, ML-Master 2.0 achieves a state-of-the-art medal rate of 56.44%. Our findings demonstrate that ultra-long-horizon autonomy provides a scalable blueprint for AI capable of autonomous exploration beyond human-precedent complexities.
WorkForceAgent-R1: Incentivizing Reasoning Capability in LLM-based Web Agents via Reinforcement Learning
May 28, 2025Large language models (LLMs)-empowered web agents enables automating complex, real-time web navigation tasks in enterprise environments. However, existing web agents relying on supervised fine-tuning (SFT) often struggle with generalization and robustness due to insufficient reasoning capabilities when handling the inherently dynamic nature of web interactions. In this study, we introduce WorkForceAgent-R1, an LLM-based web agent trained using a rule-based R1-style reinforcement learning framework designed explicitly to enhance single-step reasoning and planning for business-oriented web navigation tasks. We employ a structured reward function that evaluates both adherence to output formats and correctness of actions, enabling WorkForceAgent-R1 to implicitly learn robust intermediate reasoning without explicit annotations or extensive expert demonstrations. Extensive experiments on the WorkArena benchmark demonstrate that WorkForceAgent-R1 substantially outperforms SFT baselines by 10.26-16.59%, achieving competitive performance relative to proprietary LLM-based agents (gpt-4o) in workplace-oriented web navigation tasks.
Occult: Optimizing Collaborative Communication across Experts for Accelerated Parallel MoE Training and Inference
May 19, 2025Mixture-of-experts (MoE) architectures could achieve impressive computational efficiency with expert parallelism, which relies heavily on all-to-all communication across devices. Unfortunately, such communication overhead typically constitutes a significant portion of the total runtime, hampering the scalability of distributed training and inference for modern MoE models (consuming over $40\%$ runtime in large-scale training). In this paper, we first define collaborative communication to illustrate this intrinsic limitation, and then propose system- and algorithm-level innovations to reduce communication costs. Specifically, given a pair of experts co-activated by one token, we call them "collaborated", which comprises $2$ cases as intra- and inter-collaboration, depending on whether they are kept on the same device. Our pilot investigations reveal that augmenting the proportion of intra-collaboration can accelerate expert parallelism at scale. It motivates us to strategically optimize collaborative communication for accelerated MoE training and inference, dubbed Occult. Our designs are capable of either delivering exact results with reduced communication cost or controllably minimizing the cost with collaboration pruning, materialized by modified fine-tuning. Comprehensive experiments on various MoE-LLMs demonstrate that Occult can be faster than popular state-of-the-art inference or training frameworks (more than $1.5\times$ speed up across multiple tasks and models) with comparable or superior quality compared to the standard fine-tuning. Code is available at $\href{https://github.com/UNITES-Lab/Occult}{https://github.com/UNITES-Lab/Occult}$.
Diffusion-Driven Universal Model Inversion Attack for Face Recognition
Apr 25, 2025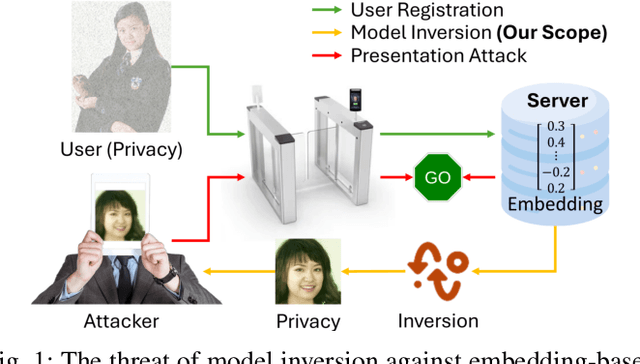
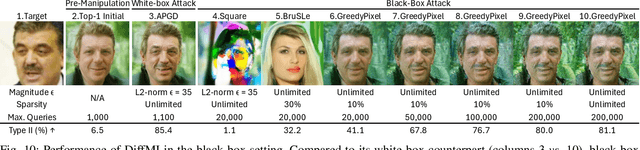
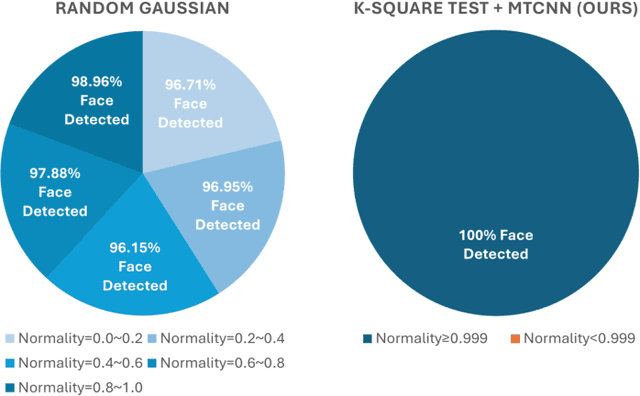
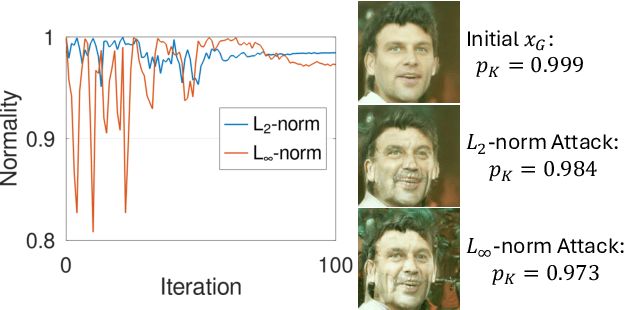
Facial recognition technology poses significant privacy risks, as it relies on biometric data that is inherently sensitive and immutable if compromised. To mitigate these concerns, face recognition systems convert raw images into embeddings, traditionally considered privacy-preserving. However, model inversion attacks pose a significant privacy threat by reconstructing these private facial images, making them a crucial tool for evaluating the privacy risks of face recognition systems. Existing methods usually require training individual generators for each target model, a computationally expensive process. In this paper, we propose DiffUMI, a training-free diffusion-driven universal model inversion attack for face recognition systems. DiffUMI is the first approach to apply a diffusion model for unconditional image generation in model inversion. Unlike other methods, DiffUMI is universal, eliminating the need for training target-specific generators. It operates within a fixed framework and pretrained diffusion model while seamlessly adapting to diverse target identities and models. DiffUMI breaches privacy-preserving face recognition systems with state-of-the-art success, demonstrating that an unconditional diffusion model, coupled with optimized adversarial search, enables efficient and high-fidelity facial reconstruction. Additionally, we introduce a novel application of out-of-domain detection (OODD), marking the first use of model inversion to distinguish non-face inputs from face inputs based solely on embeddings.
Imitation Game for Adversarial Disillusion with Multimodal Generative Chain-of-Thought Role-Play
Jan 31, 2025



As the cornerstone of artificial intelligence, machine perception confronts a fundamental threat posed by adversarial illusions. These adversarial attacks manifest in two primary forms: deductive illusion, where specific stimuli are crafted based on the victim model's general decision logic, and inductive illusion, where the victim model's general decision logic is shaped by specific stimuli. The former exploits the model's decision boundaries to create a stimulus that, when applied, interferes with its decision-making process. The latter reinforces a conditioned reflex in the model, embedding a backdoor during its learning phase that, when triggered by a stimulus, causes aberrant behaviours. The multifaceted nature of adversarial illusions calls for a unified defence framework, addressing vulnerabilities across various forms of attack. In this study, we propose a disillusion paradigm based on the concept of an imitation game. At the heart of the imitation game lies a multimodal generative agent, steered by chain-of-thought reasoning, which observes, internalises and reconstructs the semantic essence of a sample, liberated from the classic pursuit of reversing the sample to its original state. As a proof of concept, we conduct experimental simulations using a multimodal generative dialogue agent and evaluates the methodology under a variety of attack scenarios.
GreedyPixel: Fine-Grained Black-Box Adversarial Attack Via Greedy Algorithm
Jan 24, 2025A critical requirement for deep learning models is ensuring their robustness against adversarial attacks. These attacks commonly introduce noticeable perturbations, compromising the visual fidelity of adversarial examples. Another key challenge is that while white-box algorithms can generate effective adversarial perturbations, they require access to the model gradients, limiting their practicality in many real-world scenarios. Existing attack mechanisms struggle to achieve similar efficacy without access to these gradients. In this paper, we introduce GreedyPixel, a novel pixel-wise greedy algorithm designed to generate high-quality adversarial examples using only query-based feedback from the target model. GreedyPixel improves computational efficiency in what is typically a brute-force process by perturbing individual pixels in sequence, guided by a pixel-wise priority map. This priority map is constructed by ranking gradients obtained from a surrogate model, providing a structured path for perturbation. Our results demonstrate that GreedyPixel achieves attack success rates comparable to white-box methods without the need for gradient information, and surpasses existing algorithms in black-box settings, offering higher success rates, reduced computational time, and imperceptible perturbations. These findings underscore the advantages of GreedyPixel in terms of attack efficacy, time efficiency, and visual quality.
LEDRO: LLM-Enhanced Design Space Reduction and Optimization for Analog Circuits
Nov 19, 2024Traditional approaches for designing analog circuits are time-consuming and require significant human expertise. Existing automation efforts using methods like Bayesian Optimization (BO) and Reinforcement Learning (RL) are sub-optimal and costly to generalize across different topologies and technology nodes. In our work, we introduce a novel approach, LEDRO, utilizing Large Language Models (LLMs) in conjunction with optimization techniques to iteratively refine the design space for analog circuit sizing. LEDRO is highly generalizable compared to other RL and BO baselines, eliminating the need for design annotation or model training for different topologies or technology nodes. We conduct a comprehensive evaluation of our proposed framework and baseline on 22 different Op-Amp topologies across four FinFET technology nodes. Results demonstrate the superior performance of LEDRO as it outperforms our best baseline by an average of 13% FoM improvement with 2.15x speed-up on low complexity Op-Amps and 48% FoM improvement with 1.7x speed-up on high complexity Op-Amps. This highlights LEDRO's effective performance, efficiency, and generalizability.
Purification-Agnostic Proxy Learning for Agentic Copyright Watermarking against Adversarial Evidence Forgery
Sep 03, 2024With the proliferation of AI agents in various domains, protecting the ownership of AI models has become crucial due to the significant investment in their development. Unauthorized use and illegal distribution of these models pose serious threats to intellectual property, necessitating effective copyright protection measures. Model watermarking has emerged as a key technique to address this issue, embedding ownership information within models to assert rightful ownership during copyright disputes. This paper presents several contributions to model watermarking: a self-authenticating black-box watermarking protocol using hash techniques, a study on evidence forgery attacks using adversarial perturbations, a proposed defense involving a purification step to counter adversarial attacks, and a purification-agnostic proxy learning method to enhance watermark reliability and model performance. Experimental results demonstrate the effectiveness of these approaches in improving the security, reliability, and performance of watermarked models.