 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerEdit: Disentangled Multi-Object Editing via Conflict-Aware Multi-Layer Learning
Nov 11, 2025



Text-driven multi-object image editing which aims to precisely modify multiple objects within an image based on text descriptions, has recently attracted considerable interest. Existing works primarily follow the localize-editing paradigm, focusing on independent object localization and editing while neglecting critical inter-object interactions. However, this work points out that the neglected attention entanglements in inter-object conflict regions, inherently hinder disentangled multi-object editing, leading to either inter-object editing leakage or intra-object editing constraints. We thereby propose a novel multi-layer disentangled editing framework LayerEdit, a training-free method which, for the first time, through precise object-layered decomposition and coherent fusion, enables conflict-free object-layered editing. Specifically, LayerEdit introduces a novel "decompose-editingfusion" framework, consisting of: (1) Conflict-aware Layer Decomposition module, which utilizes an attention-aware IoU scheme and time-dependent region removing, to enhance conflict awareness and suppression for layer decomposition. (2) Object-layered Editing module, to establish coordinated intra-layer text guidance and cross-layer geometric mapping, achieving disentangled semantic and structural modifications. (3) Transparency-guided Layer Fusion module, to facilitate structure-coherent inter-object layer fusion through precise transparency guidance learning. Extensive experiments verify the superiority of LayerEdit over existing methods, showing unprecedented intra-object controllability and inter-object coherence in complex multi-object scenarios. Codes are available at: https://github.com/fufy1024/LayerEdit.
DynaSolidGeo: A Dynamic Benchmark for Genuine Spatial Mathematical Reasoning of VLMs in Solid Geometry
Oct 25, 2025

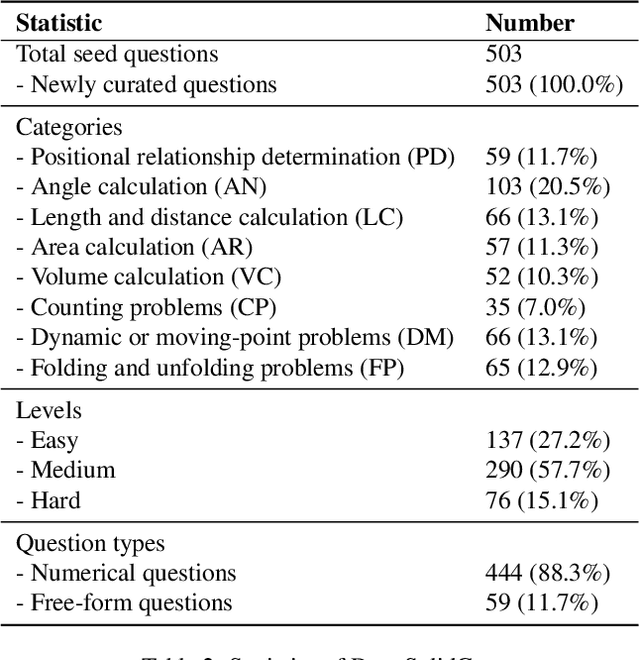

Solid geometry problem solving demands spatial mathematical reasoning that integrates spatial intelligence and symbolic reasoning. However, most existing multimodal mathematical reasoning benchmarks focus primarily on 2D plane geometry, rely on static datasets prone to data contamination and memorization, and evaluate models solely by final answers, overlooking the reasoning process. To address these limitations, we introduce DynaSolidGeo, the first dynamic benchmark for evaluating genuine spatial reasoning in Vision-Language Models (VLMs). Constructed through a semi-automatic annotation pipeline, DynaSolidGeo contains 503 expert-curated seed questions that can, in principle, dynamically generate an unbounded number of diverse multimodal text-visual instances. Beyond answer accuracy, we incorporate process evaluation based on expert-annotated reasoning chains to measure logical validity and causal coherence. Experiments across representative open-source and closed-source VLMs reveal large performance gaps, severe degradation in dynamic settings, and poor performance on tasks requiring high-level spatial intelligence, such as mental rotation and visualization. The code and dataset are available at \href{https://zgca-ai4edu.github.io/DynaSolidGeo/}{DynaSolidGeo}.
DP$^2$O-SR: Direct Perceptual Preference Optimization for Real-World Image Super-Resolution
Oct 21, 2025Benefiting from pre-trained text-to-image (T2I) diffusion models, real-world image super-resolution (Real-ISR) methods can synthesize rich and realistic details. However, due to the inherent stochasticity of T2I models, different noise inputs often lead to outputs with varying perceptual quality. Although this randomness is sometimes seen as a limitation, it also introduces a wider perceptual quality range, which can be exploited to improve Real-ISR performance. To this end, we introduce Direct Perceptual Preference Optimization for Real-ISR (DP$^2$O-SR), a framework that aligns generative models with perceptual preferences without requiring costly human annotations. We construct a hybrid reward signal by combining full-reference and no-reference image quality assessment (IQA) models trained on large-scale human preference datasets. This reward encourages both structural fidelity and natural appearance. To better utilize perceptual diversity, we move beyond the standard best-vs-worst selection and construct multiple preference pairs from outputs of the same model. Our analysis reveals that the optimal selection ratio depends on model capacity: smaller models benefit from broader coverage, while larger models respond better to stronger contrast in supervision. Furthermore, we propose hierarchical preference optimization, which adaptively weights training pairs based on intra-group reward gaps and inter-group diversity, enabling more efficient and stable learning. Extensive experiments across both diffusion- and flow-based T2I backbones demonstrate that DP$^2$O-SR significantly improves perceptual quality and generalizes well to real-world benchmarks.
Detect Anything via Next Point Prediction
Oct 14, 2025Object detection has long been dominated by traditional coordinate regression-based models, such as YOLO, DETR, and Grounding DINO. Although recent efforts have attempted to leverage MLLMs to tackle this task, they face challenges like low recall rate, duplicate predictions, coordinate misalignment, etc. In this work, we bridge this gap and propose Rex-Omni, a 3B-scale MLLM that achieves state-of-the-art object perception performance. On benchmarks like COCO and LVIS, Rex-Omni attains performance comparable to or exceeding regression-based models (e.g., DINO, Grounding DINO) in a zero-shot setting. This is enabled by three key designs: 1) Task Formulation: we use special tokens to represent quantized coordinates from 0 to 999, reducing the model's learning difficulty and improving token efficiency for coordinate prediction; 2) Data Engines: we construct multiple data engines to generate high-quality grounding, referring, and pointing data, providing semantically rich supervision for training; \3) Training Pipelines: we employ a two-stage training process, combining supervised fine-tuning on 22 million data with GRPO-based reinforcement post-training. This RL post-training leverages geometry-aware rewards to effectively bridge the discrete-to-continuous coordinate prediction gap, improve box accuracy, and mitigate undesirable behaviors like duplicate predictions that stem from the teacher-guided nature of the initial SFT stage. Beyond conventional detection, Rex-Omni's inherent language understanding enables versatile capabilities such as object referring, pointing, visual prompting, GUI grounding, spatial referring, OCR and key-pointing, all systematically evaluated on dedicated benchmarks. We believe that Rex-Omni paves the way for more versatile and language-aware visual perception systems.
ZeroCard: Cardinality Estimation with Zero Dependence on Target Databases -- No Data, No Query, No Retraining
Oct 09, 2025
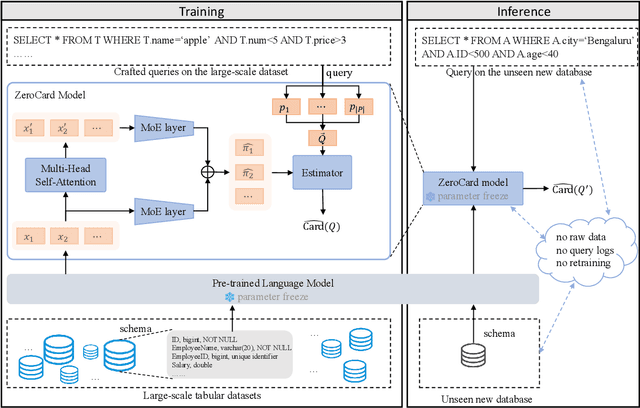
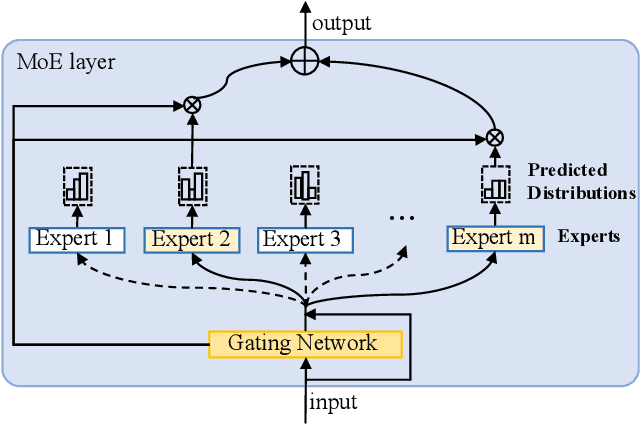
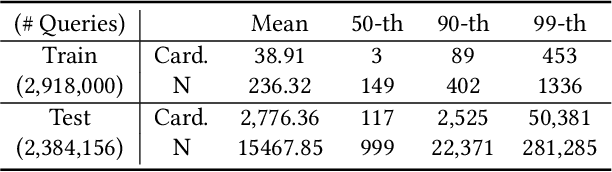
Cardinality estimation is a fundamental task in database systems and plays a critical role in query optimization. Despite significant advances in learning-based cardinality estimation methods, most existing approaches remain difficult to generalize to new datasets due to their strong dependence on raw data or queries, thus limiting their practicality in real scenarios. To overcome these challenges, we argue that semantics in the schema may benefit cardinality estimation, and leveraging such semantics may alleviate these dependencies. To this end, we introduce ZeroCard, the first semantics-driven cardinality estimation method that can be applied without any dependence on raw data access, query logs, or retraining on the target database. Specifically, we propose to predict data distributions using schema semantics, thereby avoiding raw data dependence. Then, we introduce a query template-agnostic representation method to alleviate query dependence. Finally, we construct a large-scale query dataset derived from real-world tables and pretrain ZeroCard on it, enabling it to learn cardinality from schema semantics and predicate representations. After pretraining, ZeroCard's parameters can be frozen and applied in an off-the-shelf manner. We conduct extensive experiments to demonstrate the distinct advantages of ZeroCard and show its practical applications in query optimization. Its zero-dependence property significantly facilitates deployment in real-world scenarios.
Activation Steering with a Feedback Controller
Oct 05, 2025



Controlling the behaviors of large language models (LLM) is fundamental to their safety alignment and reliable deployment. However, existing steering methods are primarily driven by empirical insights and lack theoretical performance guarantees. In this work, we develop a control-theoretic foundation for activation steering by showing that popular steering methods correspond to the proportional (P) controllers, with the steering vector serving as the feedback signal. Building on this finding, we propose Proportional-Integral-Derivative (PID) Steering, a principled framework that leverages the full PID controller for activation steering in LLMs. The proportional (P) term aligns activations with target semantic directions, the integral (I) term accumulates errors to enforce persistent corrections across layers, and the derivative (D) term mitigates overshoot by counteracting rapid activation changes. This closed-loop design yields interpretable error dynamics and connects activation steering to classical stability guarantees in control theory. Moreover, PID Steering is lightweight, modular, and readily integrates with state-of-the-art steering methods. Extensive experiments across multiple LLM families and benchmarks demonstrate that PID Steering consistently outperforms existing approaches, achieving more robust and reliable behavioral control.
NSARM: Next-Scale Autoregressive Modeling for Robust Real-World Image Super-Resolution
Oct 01, 2025



Most recent real-world image super-resolution (Real-ISR) methods employ pre-trained text-to-image (T2I) diffusion models to synthesize the high-quality image either from random Gaussian noise, which yields realistic results but is slow due to iterative denoising, or directly from the input low-quality image, which is efficient but at the price of lower output quality. These approaches train ControlNet or LoRA modules while keeping the pre-trained model fixed, which often introduces over-enhanced artifacts and hallucinations, suffering from the robustness to inputs of varying degradations. Recent visual autoregressive (AR) models, such as pre-trained Infinity, can provide strong T2I generation capabilities while offering superior efficiency by using the bitwise next-scale prediction strategy. Building upon next-scale prediction, we introduce a robust Real-ISR framework, namely Next-Scale Autoregressive Modeling (NSARM). Specifically, we train NSARM in two stages: a transformation network is first trained to map the input low-quality image to preliminary scales, followed by an end-to-end full-model fine-tuning. Such a comprehensive fine-tuning enhances the robustness of NSARM in Real-ISR tasks without compromising its generative capability. Extensive quantitative and qualitative evaluations demonstrate that as a pure AR model, NSARM achieves superior visual results over existing Real-ISR methods while maintaining a fast inference speed. Most importantly, it demonstrates much higher robustness to the quality of input images, showing stronger generalization performance. Project page: https://github.com/Xiangtaokong/NSARM
SegDINO3D: 3D Instance Segmentation Empowered by Both Image-Level and Object-Level 2D Features
Sep 19, 2025In this paper, we present SegDINO3D, a novel Transformer encoder-decoder framework for 3D instance segmentation. As 3D training data is generally not as sufficient as 2D training images, SegDINO3D is designed to fully leverage 2D representation from a pre-trained 2D detection model, including both image-level and object-level features, for improving 3D representation. SegDINO3D takes both a point cloud and its associated 2D images as input. In the encoder stage, it first enriches each 3D point by retrieving 2D image features from its corresponding image views and then leverages a 3D encoder for 3D context fusion. In the decoder stage, it formulates 3D object queries as 3D anchor boxes and performs cross-attention from 3D queries to 2D object queries obtained from 2D images using the 2D detection model. These 2D object queries serve as a compact object-level representation of 2D images, effectively avoiding the challenge of keeping thousands of image feature maps in the memory while faithfully preserving the knowledge of the pre-trained 2D model. The introducing of 3D box queries also enables the model to modulate cross-attention using the predicted boxes for more precise querying. SegDINO3D achieves the state-of-the-art performance on the ScanNetV2 and ScanNet200 3D instance segmentation benchmarks. Notably, on the challenging ScanNet200 dataset, SegDINO3D significantly outperforms prior methods by +8.7 and +6.8 mAP on the validation and hidden test sets, respectively, demonstrating its superiority.
M4Diffuser: Multi-View Diffusion Policy with Manipulability-Aware Control for Robust Mobile Manipulation
Sep 18, 2025Mobile manipulation requires the coordinated control of a mobile base and a robotic arm while simultaneously perceiving both global scene context and fine-grained object details. Existing single-view approaches often fail in unstructured environments due to limited fields of view, exploration, and generalization abilities. Moreover, classical controllers, although stable, struggle with efficiency and manipulability near singularities. To address these challenges, we propose M4Diffuser, a hybrid framework that integrates a Multi-View Diffusion Policy with a novel Reduced and Manipulability-aware QP (ReM-QP) controller for mobile manipulation. The diffusion policy leverages proprioceptive states and complementary camera perspectives with both close-range object details and global scene context to generate task-relevant end-effector goals in the world frame. These high-level goals are then executed by the ReM-QP controller, which eliminates slack variables for computational efficiency and incorporates manipulability-aware preferences for robustness near singularities. Comprehensive experiments in simulation and real-world environments show that M4Diffuser achieves 7 to 56 percent higher success rates and reduces collisions by 3 to 31 percent over baselines. Our approach demonstrates robust performance for smooth whole-body coordination, and strong generalization to unseen tasks, paving the way for reliable mobile manipulation in unstructured environments. Details of the demo and supplemental material are available on our project website https://sites.google.com/view/m4diffuser.
Continuous-Time Value Iteration for Multi-Agent Reinforcement Learning
Sep 11, 2025



Existing reinforcement learning (RL) methods struggle with complex dynamical systems that demand interactions at high frequencies or irregular time intervals. Continuous-time RL (CTRL) has emerged as a promising alternative by replacing discrete-time Bellman recursion with differential value functions defined as viscosity solutions of the Hamilton--Jacobi--Bellman (HJB) equation. While CTRL has shown promise, its applications have been largely limited to the single-agent domain. This limitation stems from two key challenges: (i) conventional solution methods for HJB equations suffer from the curse of dimensionality (CoD), making them intractable in high-dimensional systems; and (ii) even with HJB-based learning approaches, accurately approximating centralized value functions in multi-agent settings remains difficult, which in turn destabilizes policy training. In this paper, we propose a CT-MARL framework that uses physics-informed neural networks (PINNs) to approximate HJB-based value functions at scale. To ensure the value is consistent with its differential structure, we align value learning with value-gradient learning by introducing a Value Gradient Iteration (VGI) module that iteratively refines value gradients along trajectories. This improves gradient fidelity, in turn yielding more accurate values and stronger policy learning. We evaluate our method using continuous-time variants of standard benchmarks, including multi-agent particle environment (MPE) and multi-agent MuJoCo. Our results demonstrate that our approach consistently outperforms existing continuous-time RL baselines and scales to complex multi-agent dynamics.