 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Flow to One Step: Real-Time Multi-Modal Trajectory Policies via Implicit Maximum Likelihood Estimation-based Distribution Distillation
Mar 10, 2026Generative policies based on diffusion and flow matching achieve strong performance in robotic manipulation by modeling multi-modal human demonstrations. However, their reliance on iterative Ordinary Differential Equation (ODE) integration introduces substantial latency, limiting high-frequency closed-loop control. Recent single-step acceleration methods alleviate this overhead but often exhibit distributional collapse, producing averaged trajectories that fail to execute coherent manipulation strategies. We propose a framework that distills a Conditional Flow Matching (CFM) expert into a fast single-step student via Implicit Maximum Likelihood Estimation (IMLE). A bi-directional Chamfer distance provides a set-level objective that promotes both mode coverage and fidelity, enabling preservation of the teacher multi-modal action distribution in a single forward pass. A unified perception encoder further integrates multi-view RGB, depth, point clouds, and proprioception into a geometry-aware representation. The resulting high-frequency control supports real-time receding-horizon re-planning and improved robustness under dynamic disturbances.
Beyond the Vehicle: Cooperative Localization by Fusing Point Clouds for GPS-Challenged Urban Scenarios
Feb 03, 2026Accurate vehicle localization is a critical challenge in urban environments where GPS signals are often unreliable. This paper presents a cooperative multi-sensor and multi-modal localization approach to address this issue by fusing data from vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) systems. Our approach integrates cooperative data with a point cloud registration-based simultaneous localization and mapping (SLAM) algorithm. The system processes point clouds generated from diverse sensor modalities, including vehicle-mounted LiDAR and stereo cameras, as well as sensors deployed at intersections. By leveraging shared data from infrastructure, our method significantly improves localization accuracy and robustness in complex, GPS-noisy urban scenarios.
M4Diffuser: Multi-View Diffusion Policy with Manipulability-Aware Control for Robust Mobile Manipulation
Sep 18, 2025Mobile manipulation requires the coordinated control of a mobile base and a robotic arm while simultaneously perceiving both global scene context and fine-grained object details. Existing single-view approaches often fail in unstructured environments due to limited fields of view, exploration, and generalization abilities. Moreover, classical controllers, although stable, struggle with efficiency and manipulability near singularities. To address these challenges, we propose M4Diffuser, a hybrid framework that integrates a Multi-View Diffusion Policy with a novel Reduced and Manipulability-aware QP (ReM-QP) controller for mobile manipulation. The diffusion policy leverages proprioceptive states and complementary camera perspectives with both close-range object details and global scene context to generate task-relevant end-effector goals in the world frame. These high-level goals are then executed by the ReM-QP controller, which eliminates slack variables for computational efficiency and incorporates manipulability-aware preferences for robustness near singularities. Comprehensive experiments in simulation and real-world environments show that M4Diffuser achieves 7 to 56 percent higher success rates and reduces collisions by 3 to 31 percent over baselines. Our approach demonstrates robust performance for smooth whole-body coordination, and strong generalization to unseen tasks, paving the way for reliable mobile manipulation in unstructured environments. Details of the demo and supplemental material are available on our project website https://sites.google.com/view/m4diffuser.
DORA: Object Affordance-Guided Reinforcement Learning for Dexterous Robotic Manipulation
May 20, 2025Dexterous robotic manipulation remains a longstanding challenge in robotics due to the high dimensionality of control spaces and the semantic complexity of object interaction. In this paper, we propose an object affordance-guided reinforcement learning framework that enables a multi-fingered robotic hand to learn human-like manipulation strategies more efficiently. By leveraging object affordance maps, our approach generates semantically meaningful grasp pose candidates that serve as both policy constraints and priors during training. We introduce a voting-based grasp classification mechanism to ensure functional alignment between grasp configurations and object affordance regions. Furthermore, we incorporate these constraints into a generalizable RL pipeline and design a reward function that unifies affordance-awareness with task-specific objectives. Experimental results across three manipulation tasks - cube grasping, jug grasping and lifting, and hammer use - demonstrate that our affordance-guided approach improves task success rates by an average of 15.4% compared to baselines. These findings highlight the critical role of object affordance priors in enhancing sample efficiency and learning generalizable, semantically grounded manipulation policies. For more details, please visit our project website https://sites.google.com/view/dora-manip.
RECSIP: REpeated Clustering of Scores Improving the Precision
Mar 15, 2025The latest research on Large Language Models (LLMs) has demonstrated significant advancement in the field of Natural Language Processing (NLP). However, despite this progress, there is still a lack of reliability in these models. This is due to the stochastic architecture of LLMs, which presents a challenge for users attempting to ascertain the reliability of a model's response. These responses may cause serious harm in high-risk environments or expensive failures in industrial contexts. Therefore, we introduce the framework REpeated Clustering of Scores Improving the Precision (RECSIP) which focuses on improving the precision of LLMs by asking multiple models in parallel, scoring and clustering their responses to ensure a higher reliability on the response. The evaluation of our reference implementation recsip on the benchmark MMLU-Pro using the models GPT-4o, Claude and Gemini shows an overall increase of 5.8 per cent points compared to the best used model.
Sim-to-Real Transfer of Robotic Assembly with Visual Inputs Using CycleGAN and Force Control
Aug 30, 2022
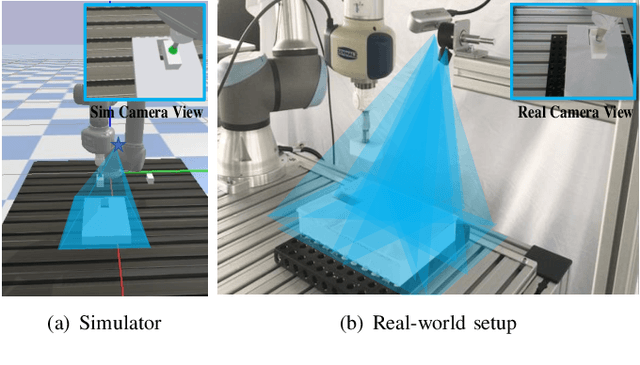
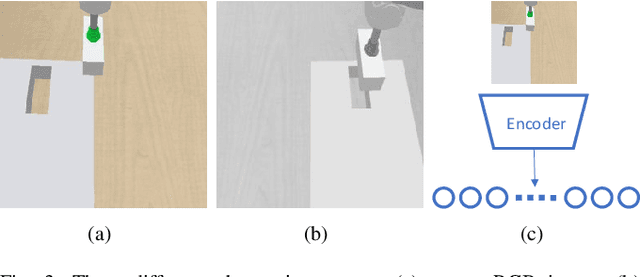
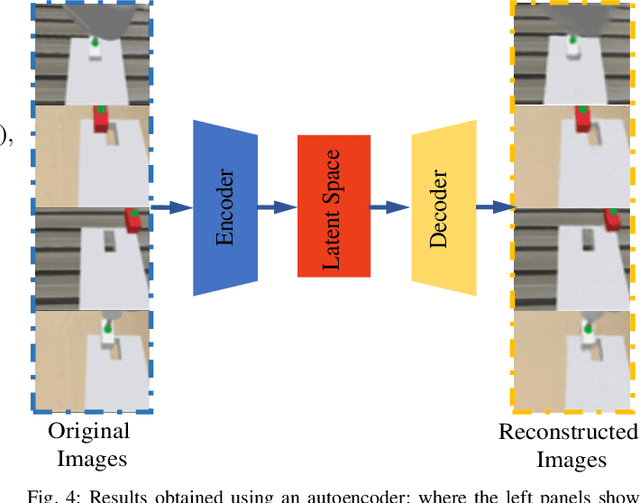
Recently, deep reinforcement learning (RL) has shown some impressive successes in robotic manipulation applications. However, training robots in the real world is nontrivial owing to sample efficiency and safety concerns. Sim-to-real transfer is proposed to address the aforementioned concerns but introduces a new issue called the reality gap. In this work, we introduce a sim-to-real learning framework for vision-based assembly tasks and perform training in a simulated environment by employing inputs from a single camera to address the aforementioned issues. We present a domain adaptation method based on cycle-consistent generative adversarial networks (CycleGAN) and a force control transfer approach to bridge the reality gap. We demonstrate that the proposed framework trained in a simulated environment can be successfully transferred to a real peg-in-hole setup.