 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleHP: Estimating Hand Pose in Metric Space
Jun 24, 2026Accurate metric-space hand pose estimation (HPE) is essential for immersive human-computer interaction and robotics. However, most existing methods predict poses in a root-relative coordinate system and cannot estimate the hand in absolute metric scale. In this work, we observe that the intrinsic proportional relationships among human hand bones encode stable anthropometric priors that implicitly correlate with the overall metric size of the hand. Leveraging this insight, we present ScaleHP, an end-to-end one-stage hand pose estimation framework that bypasses fragile extrinsic depth modules to recover the hand in metric space. ScaleHP employs a transformer-based decoder with a novel scale token to fuse multi-scale morphological and appearance features. By solving for metric coordinates through a perspective-constrained least-squares approach, we achieve high-precision pose estimation in the camera coordinate system. ScaleHP delivers state-of-the-art performance, including 35.8 CS-MPJPE on FreiHand and 4.6/5.9 PA-MPJPE on DexYCB and HO3Dv3. These results demonstrate that internal biological constraints significantly reduce relative geometry and absolute metric errors, offering a robust solution for generalized, real-world hand tracking.
SegDINO3D: 3D Instance Segmentation Empowered by Both Image-Level and Object-Level 2D Features
Sep 19, 2025In this paper, we present SegDINO3D, a novel Transformer encoder-decoder framework for 3D instance segmentation. As 3D training data is generally not as sufficient as 2D training images, SegDINO3D is designed to fully leverage 2D representation from a pre-trained 2D detection model, including both image-level and object-level features, for improving 3D representation. SegDINO3D takes both a point cloud and its associated 2D images as input. In the encoder stage, it first enriches each 3D point by retrieving 2D image features from its corresponding image views and then leverages a 3D encoder for 3D context fusion. In the decoder stage, it formulates 3D object queries as 3D anchor boxes and performs cross-attention from 3D queries to 2D object queries obtained from 2D images using the 2D detection model. These 2D object queries serve as a compact object-level representation of 2D images, effectively avoiding the challenge of keeping thousands of image feature maps in the memory while faithfully preserving the knowledge of the pre-trained 2D model. The introducing of 3D box queries also enables the model to modulate cross-attention using the predicted boxes for more precise querying. SegDINO3D achieves the state-of-the-art performance on the ScanNetV2 and ScanNet200 3D instance segmentation benchmarks. Notably, on the challenging ScanNet200 dataset, SegDINO3D significantly outperforms prior methods by +8.7 and +6.8 mAP on the validation and hidden test sets, respectively, demonstrating its superiority.
OA-Bug: An Olfactory-Auditory Augmented Bug Algorithm for Swarm Robots in a Denied Environment
Sep 28, 2022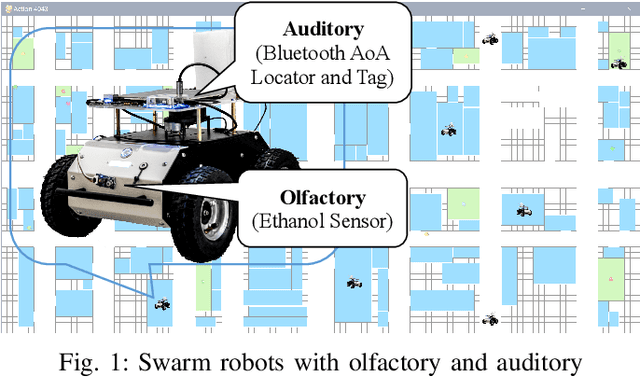
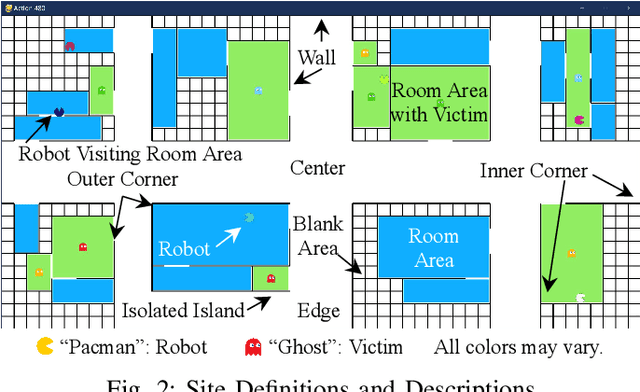
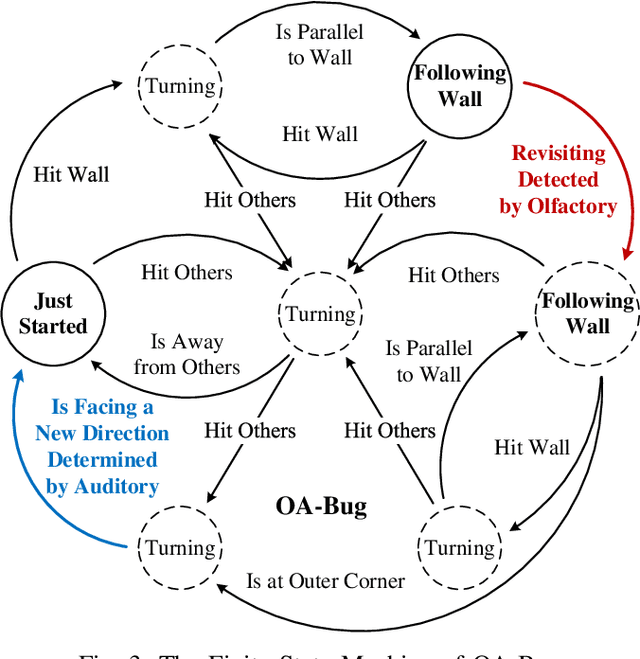
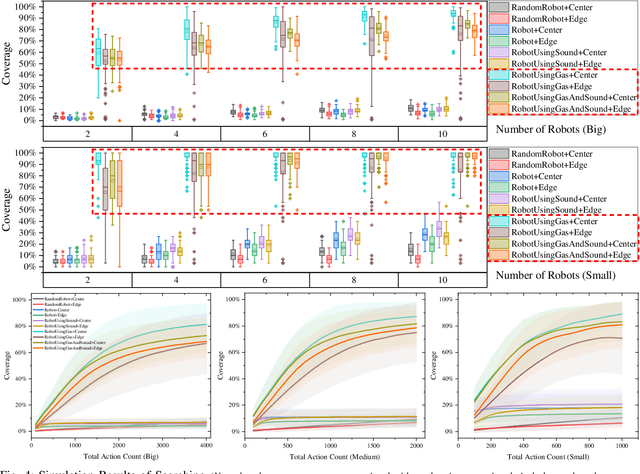
Searching in a denied environment is challenging for swarm robots as no assistance from GNSS, mapping, data sharing, and central processing are allowed. However, using olfactory and auditory to cooperate like animals could be an important way to improve the collaboration of swarm robots. In this paper, an Olfactory-Auditory augmented Bug algorithm (OA-Bug) is proposed for a swarm of autonomous robots to explore a denied environment. A simulation environment is built to measure the performance of OA-Bug. The coverage of the search task using OA-Bug can reach 96.93%, with the most significant improvement of 40.55% compared with a similar algorithm, SGBA. Furthermore, experiments are conducted on real swarm robots to prove the validity of OA-Bug. Results show that OA-Bug can improve the performance of swarm robots in a denied environment.