 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegKAN: High-Resolution Medical Image Segmentation with Long-Distance Dependencies
Dec 28, 2024Hepatic vessels in computed tomography scans often suffer from image fragmentation and noise interference, making it difficult to maintain vessel integrity and posing significant challenges for vessel segmentation. To address this issue, we propose an innovative model: SegKAN. First, we improve the conventional embedding module by adopting a novel convolutional network structure for image embedding, which smooths out image noise and prevents issues such as gradient explosion in subsequent stages. Next, we transform the spatial relationships between Patch blocks into temporal relationships to solve the problem of capturing positional relationships between Patch blocks in traditional Vision Transformer models. We conducted experiments on a Hepatic vessel dataset, and compared to the existing state-of-the-art model, the Dice score improved by 1.78%. These results demonstrate that the proposed new structure effectively enhances the segmentation performance of high-resolution extended objects. Code will be available at https://github.com/goblin327/SegKAN
MR-GDINO: Efficient Open-World Continual Object Detection
Dec 23, 2024



Open-world (OW) recognition and detection models show strong zero- and few-shot adaptation abilities, inspiring their use as initializations in continual learning methods to improve performance. Despite promising results on seen classes, such OW abilities on unseen classes are largely degenerated due to catastrophic forgetting. To tackle this challenge, we propose an open-world continual object detection task, requiring detectors to generalize to old, new, and unseen categories in continual learning scenarios. Based on this task, we present a challenging yet practical OW-COD benchmark to assess detection abilities. The goal is to motivate OW detectors to simultaneously preserve learned classes, adapt to new classes, and maintain open-world capabilities under few-shot adaptations. To mitigate forgetting in unseen categories, we propose MR-GDINO, a strong, efficient and scalable baseline via memory and retrieval mechanisms within a highly scalable memory pool. Experimental results show that existing continual detectors suffer from severe forgetting for both seen and unseen categories. In contrast, MR-GDINO largely mitigates forgetting with only 0.1% activated extra parameters, achieving state-of-the-art performance for old, new, and unseen categories.
Imitate Before Detect: Aligning Machine Stylistic Preference for Machine-Revised Text Detection
Dec 22, 2024


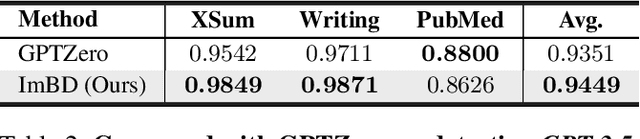
Large Language Models (LLMs) have revolutionized text generation, making detecting machine-generated text increasingly challenging. Although past methods have achieved good performance on detecting pure machine-generated text, those detectors have poor performance on distinguishing machine-revised text (rewriting, expansion, and polishing), which can have only minor changes from its original human prompt. As the content of text may originate from human prompts, detecting machine-revised text often involves identifying distinctive machine styles, e.g., worded favored by LLMs. However, existing methods struggle to detect machine-style phrasing hidden within the content contributed by humans. We propose the "Imitate Before Detect" (ImBD) approach, which first imitates the machine-style token distribution, and then compares the distribution of the text to be tested with the machine-style distribution to determine whether the text has been machine-revised. To this end, we introduce style preference optimization (SPO), which aligns a scoring LLM model to the preference of text styles generated by machines. The aligned scoring model is then used to calculate the style-conditional probability curvature (Style-CPC), quantifying the log probability difference between the original and conditionally sampled texts for effective detection. We conduct extensive comparisons across various scenarios, encompassing text revisions by six LLMs, four distinct text domains, and three machine revision types. Compared to existing state-of-the-art methods, our method yields a 13% increase in AUC for detecting text revised by open-source LLMs, and improves performance by 5% and 19% for detecting GPT-3.5 and GPT-4o revised text, respectively. Notably, our method surpasses the commercially trained GPT-Zero with just $1,000$ samples and five minutes of SPO, demonstrating its efficiency and effectiveness.
Generalizable Sensor-Based Activity Recognition via Categorical Concept Invariant Learning
Dec 18, 2024



Human Activity Recognition (HAR) aims to recognize activities by training models on massive sensor data. In real-world deployment, a crucial aspect of HAR that has been largely overlooked is that the test sets may have different distributions from training sets due to inter-subject variability including age, gender, behavioral habits, etc., which leads to poor generalization performance. One promising solution is to learn domain-invariant representations to enable a model to generalize on an unseen distribution. However, most existing methods only consider the feature-invariance of the penultimate layer for domain-invariant learning, which leads to suboptimal results. In this paper, we propose a Categorical Concept Invariant Learning (CCIL) framework for generalizable activity recognition, which introduces a concept matrix to regularize the model in the training stage by simultaneously concentrating on feature-invariance and logit-invariance. Our key idea is that the concept matrix for samples belonging to the same activity category should be similar. Extensive experiments on four public HAR benchmarks demonstrate that our CCIL substantially outperforms the state-of-the-art approaches under cross-person, cross-dataset, cross-position, and one-person-to-another settings.
Multi-Scale Cross-Fusion and Edge-Supervision Network for Image Splicing Localization
Dec 17, 2024



Image Splicing Localization (ISL) is a fundamental yet challenging task in digital forensics. Although current approaches have achieved promising performance, the edge information is insufficiently exploited, resulting in poor integrality and high false alarms. To tackle this problem, we propose a multi-scale cross-fusion and edge-supervision network for ISL. Specifically, our framework consists of three key steps: multi-scale features cross-fusion, edge mask prediction and edge-supervision localization. Firstly, we input the RGB image and its noise image into a segmentation network to learn multi-scale features, which are then aggregated via a cross-scale fusion followed by a cross-domain fusion to enhance feature representation. Secondly, we design an edge mask prediction module to effectively mine the reliable boundary artifacts. Finally, the cross-fused features and the reliable edge mask information are seamlessly integrated via an attention mechanism to incrementally supervise and facilitate model training. Extensive experiments on publicly available datasets demonstrate that our proposed method is superior to state-of-the-art schemes.
ChatTime: A Unified Multimodal Time Series Foundation Model Bridging Numerical and Textual Data
Dec 16, 2024



Human experts typically integrate numerical and textual multimodal information to analyze time series. However, most traditional deep learning predictors rely solely on unimodal numerical data, using a fixed-length window for training and prediction on a single dataset, and cannot adapt to different scenarios. The powered pre-trained large language model has introduced new opportunities for time series analysis. Yet, existing methods are either inefficient in training, incapable of handling textual information, or lack zero-shot forecasting capability. In this paper, we innovatively model time series as a foreign language and construct ChatTime, a unified framework for time series and text processing. As an out-of-the-box multimodal time series foundation model, ChatTime provides zero-shot forecasting capability and supports bimodal input/output for both time series and text. We design a series of experiments to verify the superior performance of ChatTime across multiple tasks and scenarios, and create four multimodal datasets to address data gaps. The experimental results demonstrate the potential and utility of ChatTime.
ExecRepoBench: Multi-level Executable Code Completion Evaluation
Dec 16, 2024



Code completion has become an essential tool for daily software development. Existing evaluation benchmarks often employ static methods that do not fully capture the dynamic nature of real-world coding environments and face significant challenges, including limited context length, reliance on superficial evaluation metrics, and potential overfitting to training datasets. In this work, we introduce a novel framework for enhancing code completion in software development through the creation of a repository-level benchmark ExecRepoBench and the instruction corpora Repo-Instruct, aim at improving the functionality of open-source large language models (LLMs) in real-world coding scenarios that involve complex interdependencies across multiple files. ExecRepoBench includes 1.2K samples from active Python repositories. Plus, we present a multi-level grammar-based completion methodology conditioned on the abstract syntax tree to mask code fragments at various logical units (e.g. statements, expressions, and functions). Then, we fine-tune the open-source LLM with 7B parameters on Repo-Instruct to produce a strong code completion baseline model Qwen2.5-Coder-Instruct-C based on the open-source model. Qwen2.5-Coder-Instruct-C is rigorously evaluated against existing benchmarks, including MultiPL-E and ExecRepoBench, which consistently outperforms prior baselines across all programming languages. The deployment of \ourmethod{} can be used as a high-performance, local service for programming development\footnote{\url{https://execrepobench.github.io/}}.
Unbiased General Annotated Dataset Generation
Dec 14, 2024



Pre-training backbone networks on a general annotated dataset (e.g., ImageNet) that comprises numerous manually collected images with category annotations has proven to be indispensable for enhancing the generalization capacity of downstream visual tasks. However, those manually collected images often exhibit bias, which is non-transferable across either categories or domains, thus causing the model's generalization capacity degeneration. To mitigate this problem, we present an unbiased general annotated dataset generation framework (ubGen). Instead of expensive manual collection, we aim at directly generating unbiased images with category annotations. To achieve this goal, we propose to leverage the advantage of a multimodal foundation model (e.g., CLIP), in terms of aligning images in an unbiased semantic space defined by language. Specifically, we develop a bi-level semantic alignment loss, which not only forces all generated images to be consistent with the semantic distribution of all categories belonging to the target dataset in an adversarial learning manner, but also requires each generated image to match the semantic description of its category name. In addition, we further cast an existing image quality scoring model into a quality assurance loss to preserve the quality of the generated image. By leveraging these two loss functions, we can obtain an unbiased image generation model by simply fine-tuning a pre-trained diffusion model using only all category names in the target dataset as input. Experimental results confirm that, compared with the manually labeled dataset or other synthetic datasets, the utilization of our generated unbiased datasets leads to stable generalization capacity enhancement of different backbone networks across various tasks, especially in tasks where the manually labeled samples are scarce.
Language model driven: a PROTAC generation pipeline with dual constraints of structure and property
Dec 12, 2024The imperfect modeling of ternary complexes has limited the application of computer-aided drug discovery tools in PROTAC research and development. In this study, an AI-assisted approach for PROTAC molecule design pipeline named LM-PROTAC was developed, which stands for language model driven Proteolysis Targeting Chimera, by embedding a transformer-based generative model with dual constraints on structure and properties, referred to as the DCT. This study utilized the fragmentation representation of molecules and developed a language model driven pipeline. Firstly, a language model driven affinity model for protein compounds to screen molecular fragments with high affinity for the target protein. Secondly, structural and physicochemical properties of these fragments were constrained during the generation process to meet specific scenario requirements. Finally, a two-round screening of the preliminary generated molecules using a multidimensional property prediction model to generate a batch of PROTAC molecules capable of degrading disease-relevant target proteins for validation in vitro experiments, thus achieving a complete solution for AI-assisted PROTAC drug generation. Taking the tumor key target Wnt3a as an example, the LM-PROTAC pipeline successfully generated PROTAC molecules capable of inhibiting Wnt3a. The results show that DCT can efficiently generate PROTAC that targets and hydrolyses Wnt3a.
Mining Word Boundaries from Speech-Text Parallel Data for Cross-domain Chinese Word Segmentation
Dec 12, 2024



Inspired by early research on exploring naturally annotated data for Chinese Word Segmentation (CWS), and also by recent research on integration of speech and text processing, this work for the first time proposes to explicitly mine word boundaries from speech-text parallel data. We employ the Montreal Forced Aligner (MFA) toolkit to perform character-level alignment on speech-text data, giving pauses as candidate word boundaries. Based on detailed analysis of collected pauses, we propose an effective probability-based strategy for filtering unreliable word boundaries. To more effectively utilize word boundaries as extra training data, we also propose a robust complete-then-train (CTT) strategy. We conduct cross-domain CWS experiments on two target domains, i.e., ZX and AISHELL2. We have annotated about 1,000 sentences as the evaluation data of AISHELL2. Experiments demonstrate the effectiveness of our proposed approach.