 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAIROS: Unified Training for Universal Non-Autoregressive Time Series Forecasting
Oct 02, 2025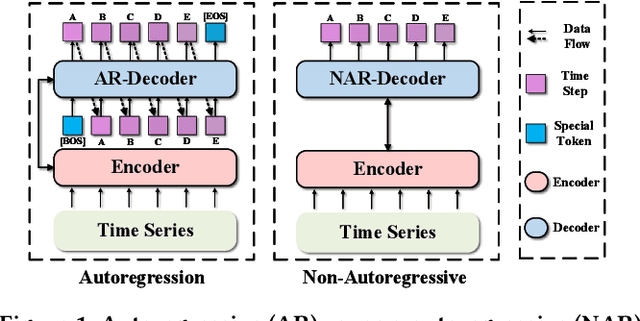

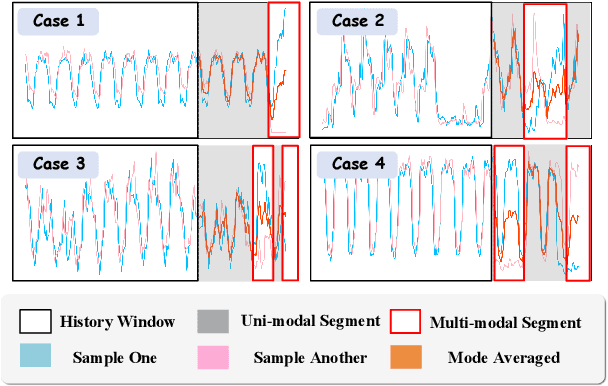
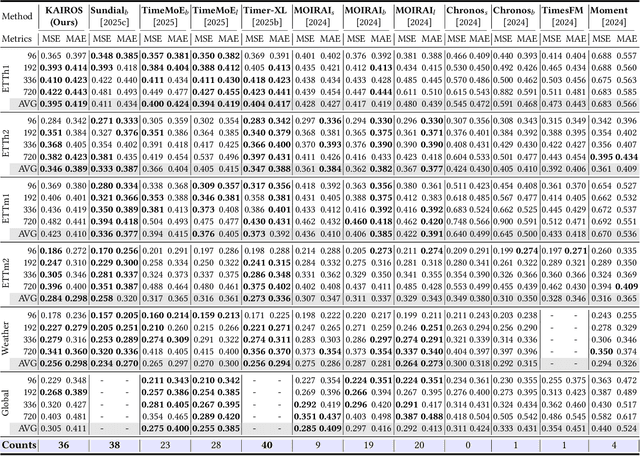
In the World Wide Web, reliable time series forecasts provide the forward-looking signals that drive resource planning, cache placement, and anomaly response, enabling platforms to operate efficiently as user behavior and content distributions evolve. Compared with other domains, time series forecasting for Web applications requires much faster responsiveness to support real-time decision making. We present KAIROS, a non-autoregressive time series forecasting framework that directly models segment-level multi-peak distributions. Unlike autoregressive approaches, KAIROS avoids error accumulation and achieves just-in-time inference, while improving over existing non-autoregressive models that collapse to over-smoothed predictions. Trained on the large-scale corpus, KAIROS demonstrates strong zero-shot generalization on six widely used benchmarks, delivering forecasting performance comparable to state-of-the-art foundation models with similar scale, at a fraction of their inference cost. Beyond empirical results, KAIROS highlights the importance of non-autoregressive design as a scalable paradigm for foundation models in time series.
Adaptive LoRA Experts Allocation and Selection for Federated Fine-Tuning
Sep 18, 2025Large Language Models (LLMs) have demonstrated impressive capabilities across various tasks, but fine-tuning them for domain-specific applications often requires substantial domain-specific data that may be distributed across multiple organizations. Federated Learning (FL) offers a privacy-preserving solution, but faces challenges with computational constraints when applied to LLMs. Low-Rank Adaptation (LoRA) has emerged as a parameter-efficient fine-tuning approach, though a single LoRA module often struggles with heterogeneous data across diverse domains. This paper addresses two critical challenges in federated LoRA fine-tuning: 1. determining the optimal number and allocation of LoRA experts across heterogeneous clients, and 2. enabling clients to selectively utilize these experts based on their specific data characteristics. We propose FedLEASE (Federated adaptive LoRA Expert Allocation and SElection), a novel framework that adaptively clusters clients based on representation similarity to allocate and train domain-specific LoRA experts. It also introduces an adaptive top-$M$ Mixture-of-Experts mechanism that allows each client to select the optimal number of utilized experts. Our extensive experiments on diverse benchmark datasets demonstrate that FedLEASE significantly outperforms existing federated fine-tuning approaches in heterogeneous client settings while maintaining communication efficiency.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
Improving Anomalous Sound Detection with Attribute-aware Representation from Domain-adaptive Pre-training
Sep 16, 2025Anomalous Sound Detection (ASD) is often formulated as a machine attribute classification task, a strategy necessitated by the common scenario where only normal data is available for training. However, the exhaustive collection of machine attribute labels is laborious and impractical. To address the challenge of missing attribute labels, this paper proposes an agglomerative hierarchical clustering method for the assignment of pseudo-attribute labels using representations derived from a domain-adaptive pre-trained model, which are expected to capture machine attribute characteristics. We then apply model adaptation to this pre-trained model through supervised fine-tuning for machine attribute classification, resulting in a new state-of-the-art performance. Evaluation on the Detection and Classification of Acoustic Scenes and Events (DCASE) 2025 Challenge dataset demonstrates that our proposed approach yields significant performance gains, ultimately outperforming our previous top-ranking system in the challenge.
Video Understanding by Design: How Datasets Shape Architectures and Insights
Sep 11, 2025Video understanding has advanced rapidly, fueled by increasingly complex datasets and powerful architectures. Yet existing surveys largely classify models by task or family, overlooking the structural pressures through which datasets guide architectural evolution. This survey is the first to adopt a dataset-driven perspective, showing how motion complexity, temporal span, hierarchical composition, and multimodal richness impose inductive biases that models should encode. We reinterpret milestones, from two-stream and 3D CNNs to sequential, transformer, and multimodal foundation models, as concrete responses to these dataset-driven pressures. Building on this synthesis, we offer practical guidance for aligning model design with dataset invariances while balancing scalability and task demands. By unifying datasets, inductive biases, and architectures into a coherent framework, this survey provides both a comprehensive retrospective and a prescriptive roadmap for advancing general-purpose video understanding.
Over-the-Air Adversarial Attack Detection: from Datasets to Defenses
Sep 11, 2025



Automatic Speaker Verification (ASV) systems can be used for voice-enabled applications for identity verification. However, recent studies have exposed these systems' vulnerabilities to both over-the-line (OTL) and over-the-air (OTA) adversarial attacks. Although various detection methods have been proposed to counter these threats, they have not been thoroughly tested due to the lack of a comprehensive data set. To address this gap, we developed the AdvSV 2.0 dataset, which contains 628k samples with a total duration of 800 hours. This dataset incorporates classical adversarial attack algorithms, ASV systems, and encompasses both OTL and OTA scenarios. Furthermore, we introduce a novel adversarial attack method based on a Neural Replay Simulator (NRS), which enhances the potency of adversarial OTA attacks, thereby presenting a greater threat to ASV systems. To defend against these attacks, we propose CODA-OCC, a contrastive learning approach within the one-class classification framework. Experimental results show that CODA-OCC achieves an EER of 11.2% and an AUC of 0.95 on the AdvSV 2.0 dataset, outperforming several state-of-the-art detection methods.
Quantum-Enhanced Multi-Task Learning with Learnable Weighting for Pharmacokinetic and Toxicity Prediction
Sep 04, 2025Prediction for ADMET (Absorption, Distribution, Metabolism, Excretion, and Toxicity) plays a crucial role in drug discovery and development, accelerating the screening and optimization of new drugs. Existing methods primarily rely on single-task learning (STL), which often fails to fully exploit the complementarities between tasks. Besides, it requires more computational resources while training and inference of each task independently. To address these issues, we propose a new unified Quantum-enhanced and task-Weighted Multi-Task Learning (QW-MTL) framework, specifically designed for ADMET classification tasks. Built upon the Chemprop-RDKit backbone, QW-MTL adopts quantum chemical descriptors to enrich molecular representations with additional information about the electronic structure and interactions. Meanwhile, it introduces a novel exponential task weighting scheme that combines dataset-scale priors with learnable parameters to achieve dynamic loss balancing across tasks. To the best of our knowledge, this is the first work to systematically conduct joint multi-task training across all 13 Therapeutics Data Commons (TDC) classification benchmarks, using leaderboard-style data splits to ensure a standardized and realistic evaluation setting. Extensive experimental results show that QW-MTL significantly outperforms single-task baselines on 12 out of 13 tasks, achieving high predictive performance with minimal model complexity and fast inference, demonstrating the effectiveness and efficiency of multi-task molecular learning enhanced by quantum-informed features and adaptive task weighting.
LabelGS: Label-Aware 3D Gaussian Splatting for 3D Scene Segmentation
Aug 27, 20253D Gaussian Splatting (3DGS) has emerged as a novel explicit representation for 3D scenes, offering both high-fidelity reconstruction and efficient rendering. However, 3DGS lacks 3D segmentation ability, which limits its applicability in tasks that require scene understanding. The identification and isolating of specific object components is crucial. To address this limitation, we propose Label-aware 3D Gaussian Splatting (LabelGS), a method that augments the Gaussian representation with object label.LabelGS introduces cross-view consistent semantic masks for 3D Gaussians and employs a novel Occlusion Analysis Model to avoid overfitting occlusion during optimization, Main Gaussian Labeling model to lift 2D semantic prior to 3D Gaussian and Gaussian Projection Filter to avoid Gaussian label conflict. Our approach achieves effective decoupling of Gaussian representations and refines the 3DGS optimization process through a random region sampling strategy, significantly improving efficiency. Extensive experiments demonstrate that LabelGS outperforms previous state-of-the-art methods, including Feature-3DGS, in the 3D scene segmentation task. Notably, LabelGS achieves a remarkable 22X speedup in training compared to Feature-3DGS, at a resolution of 1440X1080. Our code will be at https://github.com/garrisonz/LabelGS.
Prototype-Guided Curriculum Learning for Zero-Shot Learning
Aug 11, 2025In Zero-Shot Learning (ZSL), embedding-based methods enable knowledge transfer from seen to unseen classes by learning a visual-semantic mapping from seen-class images to class-level semantic prototypes (e.g., attributes). However, these semantic prototypes are manually defined and may introduce noisy supervision for two main reasons: (i) instance-level mismatch: variations in perspective, occlusion, and annotation bias will cause discrepancies between individual sample and the class-level semantic prototypes; and (ii) class-level imprecision: the manually defined semantic prototypes may not accurately reflect the true semantics of the class. Consequently, the visual-semantic mapping will be misled, reducing the effectiveness of knowledge transfer to unseen classes. In this work, we propose a prototype-guided curriculum learning framework (dubbed as CLZSL), which mitigates instance-level mismatches through a Prototype-Guided Curriculum Learning (PCL) module and addresses class-level imprecision via a Prototype Update (PUP) module. Specifically, the PCL module prioritizes samples with high cosine similarity between their visual mappings and the class-level semantic prototypes, and progressively advances to less-aligned samples, thereby reducing the interference of instance-level mismatches to achieve accurate visual-semantic mapping. Besides, the PUP module dynamically updates the class-level semantic prototypes by leveraging the visual mappings learned from instances, thereby reducing class-level imprecision and further improving the visual-semantic mapping. Experiments were conducted on standard benchmark datasets-AWA2, SUN, and CUB-to verify the effectiveness of our method.
HSA-Net: Hierarchical and Structure-Aware Framework for Efficient and Scalable Molecular Language Modeling
Aug 10, 2025Molecular representation learning, a cornerstone for downstream tasks like molecular captioning and molecular property prediction, heavily relies on Graph Neural Networks (GNN). However, GNN suffers from the over-smoothing problem, where node-level features collapse in deep GNN layers. While existing feature projection methods with cross-attention have been introduced to mitigate this issue, they still perform poorly in deep features. This motivated our exploration of using Mamba as an alternative projector for its ability to handle complex sequences. However, we observe that while Mamba excels at preserving global topological information from deep layers, it neglects fine-grained details in shallow layers. The capabilities of Mamba and cross-attention exhibit a global-local trade-off. To resolve this critical global-local trade-off, we propose Hierarchical and Structure-Aware Network (HSA-Net), a novel framework with two modules that enables a hierarchical feature projection and fusion. Firstly, a Hierarchical Adaptive Projector (HAP) module is introduced to process features from different graph layers. It learns to dynamically switch between a cross-attention projector for shallow layers and a structure-aware Graph-Mamba projector for deep layers, producing high-quality, multi-level features. Secondly, to adaptively merge these multi-level features, we design a Source-Aware Fusion (SAF) module, which flexibly selects fusion experts based on the characteristics of the aggregation features, ensuring a precise and effective final representation fusion. Extensive experiments demonstrate that our HSA-Net framework quantitatively and qualitatively outperforms current state-of-the-art (SOTA) methods.