 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-Level Ordinal Modeling for Multimodal Essay Scoring with Large Language Models
Mar 16, 2026Automated essay scoring (AES) predicts multiple rubric-defined trait scores for each essay, where each trait follows an ordered discrete rating scale. Most LLM-based AES methods cast scoring as autoregressive token generation and obtain the final score via decoding and parsing, making the decision implicit. This formulation is particularly sensitive in multimodal AES, where the usefulness of visual inputs varies across essays and traits. To address these limitations, we propose Decision-Level Ordinal Modeling (DLOM), which makes scoring an explicit ordinal decision by reusing the language model head to extract score-wise logits on predefined score tokens, enabling direct optimization and analysis in the score space. For multimodal AES, DLOM-GF introduces a gated fusion module that adaptively combines textual and multimodal score logits. For text-only AES, DLOM-DA adds a distance-aware regularization term to better reflect ordinal distances. Experiments on the multimodal EssayJudge dataset show that DLOM improves over a generation-based SFT baseline across scoring traits, and DLOM-GF yields further gains when modality relevance is heterogeneous. On the text-only ASAP/ASAP++ benchmarks, DLOM remains effective without visual inputs, and DLOM-DA further improves performance and outperforms strong representative baselines.
Quantum-Enhanced Multi-Task Learning with Learnable Weighting for Pharmacokinetic and Toxicity Prediction
Sep 04, 2025Prediction for ADMET (Absorption, Distribution, Metabolism, Excretion, and Toxicity) plays a crucial role in drug discovery and development, accelerating the screening and optimization of new drugs. Existing methods primarily rely on single-task learning (STL), which often fails to fully exploit the complementarities between tasks. Besides, it requires more computational resources while training and inference of each task independently. To address these issues, we propose a new unified Quantum-enhanced and task-Weighted Multi-Task Learning (QW-MTL) framework, specifically designed for ADMET classification tasks. Built upon the Chemprop-RDKit backbone, QW-MTL adopts quantum chemical descriptors to enrich molecular representations with additional information about the electronic structure and interactions. Meanwhile, it introduces a novel exponential task weighting scheme that combines dataset-scale priors with learnable parameters to achieve dynamic loss balancing across tasks. To the best of our knowledge, this is the first work to systematically conduct joint multi-task training across all 13 Therapeutics Data Commons (TDC) classification benchmarks, using leaderboard-style data splits to ensure a standardized and realistic evaluation setting. Extensive experimental results show that QW-MTL significantly outperforms single-task baselines on 12 out of 13 tasks, achieving high predictive performance with minimal model complexity and fast inference, demonstrating the effectiveness and efficiency of multi-task molecular learning enhanced by quantum-informed features and adaptive task weighting.
PhysicsArena: The First Multimodal Physics Reasoning Benchmark Exploring Variable, Process, and Solution Dimensions
May 21, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in diverse reasoning tasks, yet their application to complex physics reasoning remains underexplored. Physics reasoning presents unique challenges, requiring grounding in physical conditions and the interpretation of multimodal information. Current physics benchmarks are limited, often focusing on text-only inputs or solely on problem-solving, thereby overlooking the critical intermediate steps of variable identification and process formulation. To address these limitations, we introduce PhysicsArena, the first multimodal physics reasoning benchmark designed to holistically evaluate MLLMs across three critical dimensions: variable identification, physical process formulation, and solution derivation. PhysicsArena aims to provide a comprehensive platform for assessing and advancing the multimodal physics reasoning abilities of MLLMs.
CAFES: A Collaborative Multi-Agent Framework for Multi-Granular Multimodal Essay Scoring
May 20, 2025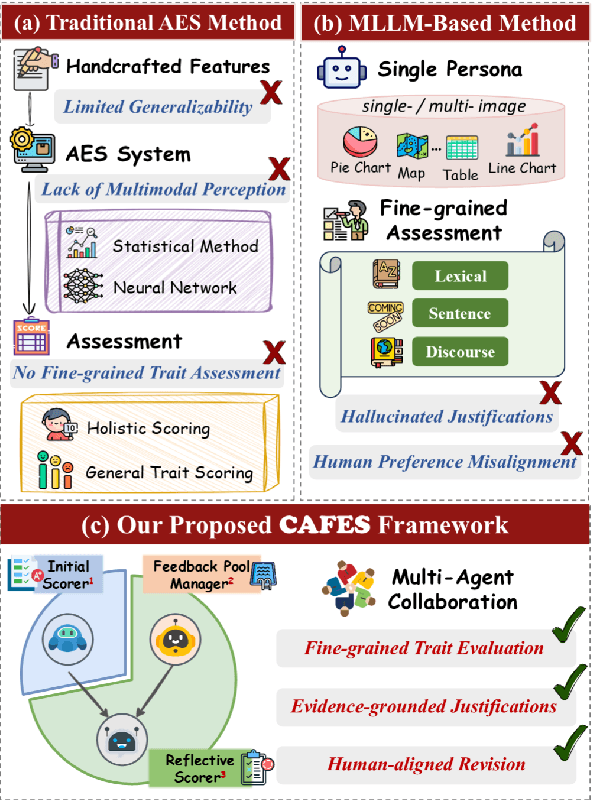
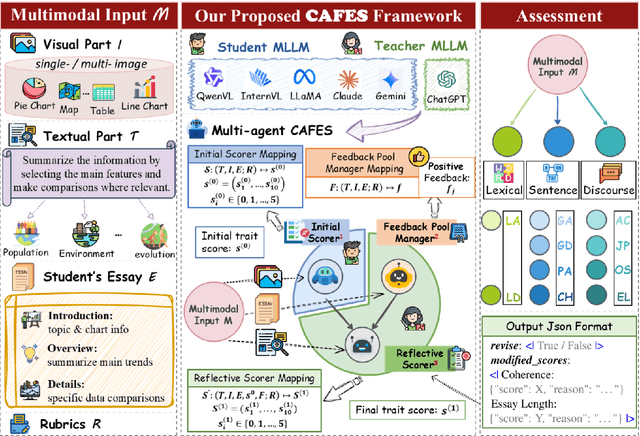
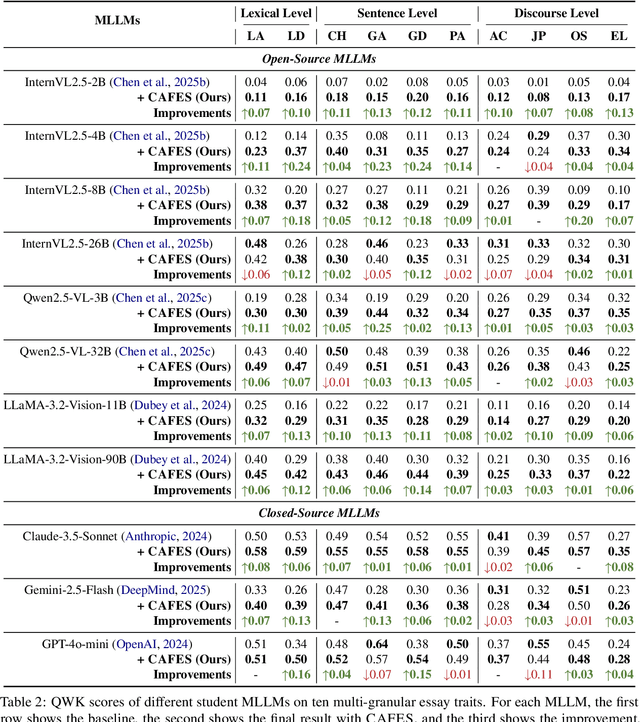
Automated Essay Scoring (AES) is crucial for modern education, particularly with the increasing prevalence of multimodal assessments. However, traditional AES methods struggle with evaluation generalizability and multimodal perception, while even recent Multimodal Large Language Model (MLLM)-based approaches can produce hallucinated justifications and scores misaligned with human judgment. To address the limitations, we introduce CAFES, the first collaborative multi-agent framework specifically designed for AES. It orchestrates three specialized agents: an Initial Scorer for rapid, trait-specific evaluations; a Feedback Pool Manager to aggregate detailed, evidence-grounded strengths; and a Reflective Scorer that iteratively refines scores based on this feedback to enhance human alignment. Extensive experiments, using state-of-the-art MLLMs, achieve an average relative improvement of 21% in Quadratic Weighted Kappa (QWK) against ground truth, especially for grammatical and lexical diversity. Our proposed CAFES framework paves the way for an intelligent multimodal AES system. The code will be available upon acceptance.
EssayJudge: A Multi-Granular Benchmark for Assessing Automated Essay Scoring Capabilities of Multimodal Large Language Models
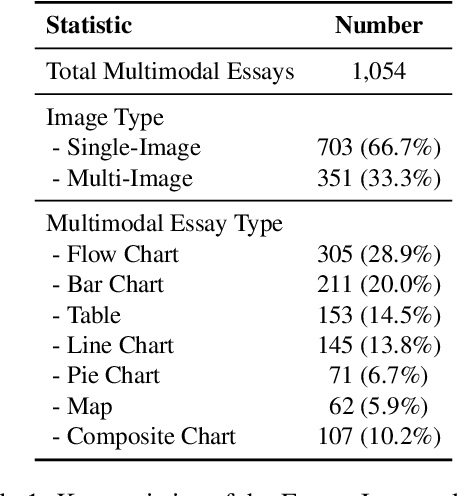
Feb 17, 2025Automated Essay Scoring (AES) plays a crucial role in educational assessment by providing scalable and consistent evaluations of writing tasks. However, traditional AES systems face three major challenges: (1) reliance on handcrafted features that limit generalizability, (2) difficulty in capturing fine-grained traits like coherence and argumentation, and (3) inability to handle multimodal contexts. In the era of Multimodal Large Language Models (MLLMs), we propose EssayJudge, the first multimodal benchmark to evaluate AES capabilities across lexical-, sentence-, and discourse-level traits. By leveraging MLLMs' strengths in trait-specific scoring and multimodal context understanding, EssayJudge aims to offer precise, context-rich evaluations without manual feature engineering, addressing longstanding AES limitations. Our experiments with 18 representative MLLMs reveal gaps in AES performance compared to human evaluation, particularly in discourse-level traits, highlighting the need for further advancements in MLLM-based AES research. Our dataset and code will be available upon acceptance.
A Survey of Mathematical Reasoning in the Era of Multimodal Large Language Model: Benchmark, Method & Challenges
Dec 16, 2024Mathematical reasoning, a core aspect of human cognition, is vital across many domains, from educational problem-solving to scientific advancements. As artificial general intelligence (AGI) progresses, integrating large language models (LLMs) with mathematical reasoning tasks is becoming increasingly significant. This survey provides the first comprehensive analysis of mathematical reasoning in the era of multimodal large language models (MLLMs). We review over 200 studies published since 2021, and examine the state-of-the-art developments in Math-LLMs, with a focus on multimodal settings. We categorize the field into three dimensions: benchmarks, methodologies, and challenges. In particular, we explore multimodal mathematical reasoning pipeline, as well as the role of (M)LLMs and the associated methodologies. Finally, we identify five major challenges hindering the realization of AGI in this domain, offering insights into the future direction for enhancing multimodal reasoning capabilities. This survey serves as a critical resource for the research community in advancing the capabilities of LLMs to tackle complex multimodal reasoning tasks.
ErrorRadar: Benchmarking Complex Mathematical Reasoning of Multimodal Large Language Models Via Error Detection
Oct 06, 2024



As the field of Multimodal Large Language Models (MLLMs) continues to evolve, their potential to revolutionize artificial intelligence is particularly promising, especially in addressing mathematical reasoning tasks. Current mathematical benchmarks predominantly focus on evaluating MLLMs' problem-solving ability, yet there is a crucial gap in addressing more complex scenarios such as error detection, for enhancing reasoning capability in complicated settings. To fill this gap, we formally formulate the new task: multimodal error detection, and introduce ErrorRadar, the first benchmark designed to assess MLLMs' capabilities in such a task. ErrorRadar evaluates two sub-tasks: error step identification and error categorization, providing a comprehensive framework for evaluating MLLMs' complex mathematical reasoning ability. It consists of 2,500 high-quality multimodal K-12 mathematical problems, collected from real-world student interactions in an educational organization, with rigorous annotation and rich metadata such as problem type and error category. Through extensive experiments, we evaluated both open-source and closed-source representative MLLMs, benchmarking their performance against educational expert evaluators. Results indicate significant challenges still remain, as GPT-4o with best performance is still around 10% behind human evaluation. The dataset will be available upon acceptance.