 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsat Core Prediction through Polarity-Aware Representation Learning over Clause-Literal Hypergraphs
May 06, 2026Graph neural networks have been widely used in Boolean satisfiability (SAT) tasks to learn structural information from SAT formulas. The goal of these studies is to solve SAT instances or to enhance SAT solvers, including tasks such as unsat-core prediction. However, most existing approaches model a SAT formula as a bipartite graph or a directed acyclic graph, which are less expressive in capturing higher-order interactions among literals and clauses. Moreover, these approaches are limited in modeling intrinsic polarity-related properties of SAT, such as the complementary relationship between the positive and negative literals of a variable. To address these limitations, we propose a polarity-aware representation learning framework over clause-literal hypergraphs. We model SAT formulas as clause-literal hypergraphs augmented with a clause incidence graph to capture higher-order structural interactions. We then introduce a polarity-aware decomposed mechanism that separates variable representations into polarity invariant and equivariant components, explicitly modeling the relationship between positive and negative literals, with the resulting literal representations propagated along the hypergraph structure. We further incorporate a polarity-inversion consistency regularization to reinforce polarity-consistent representations during training. Experimental results on multiple SAT datasets demonstrate the effectiveness of the proposed approach.
How Vulnerable Are Edge LLMs?
Mar 25, 2026Large language models (LLMs) are increasingly deployed on edge devices under strict computation and quantization constraints, yet their security implications remain unclear. We study query-based knowledge extraction from quantized edge-deployed LLMs under realistic query budgets and show that, although quantization introduces noise, it does not remove the underlying semantic knowledge, allowing substantial behavioral recovery through carefully designed queries. To systematically analyze this risk, we propose \textbf{CLIQ} (\textbf{Cl}ustered \textbf{I}nstruction \textbf{Q}uerying), a structured query construction framework that improves semantic coverage while reducing redundancy. Experiments on quantized Qwen models (INT8/INT4) demonstrate that CLIQ consistently outperforms original queries across BERTScore, BLEU, and ROUGE, enabling more efficient extraction under limited budgets. These results indicate that quantization alone does not provide effective protection against query-based extraction, highlighting a previously underexplored security risk in edge-deployed LLMs.
LabelGS: Label-Aware 3D Gaussian Splatting for 3D Scene Segmentation
Aug 27, 20253D Gaussian Splatting (3DGS) has emerged as a novel explicit representation for 3D scenes, offering both high-fidelity reconstruction and efficient rendering. However, 3DGS lacks 3D segmentation ability, which limits its applicability in tasks that require scene understanding. The identification and isolating of specific object components is crucial. To address this limitation, we propose Label-aware 3D Gaussian Splatting (LabelGS), a method that augments the Gaussian representation with object label.LabelGS introduces cross-view consistent semantic masks for 3D Gaussians and employs a novel Occlusion Analysis Model to avoid overfitting occlusion during optimization, Main Gaussian Labeling model to lift 2D semantic prior to 3D Gaussian and Gaussian Projection Filter to avoid Gaussian label conflict. Our approach achieves effective decoupling of Gaussian representations and refines the 3DGS optimization process through a random region sampling strategy, significantly improving efficiency. Extensive experiments demonstrate that LabelGS outperforms previous state-of-the-art methods, including Feature-3DGS, in the 3D scene segmentation task. Notably, LabelGS achieves a remarkable 22X speedup in training compared to Feature-3DGS, at a resolution of 1440X1080. Our code will be at https://github.com/garrisonz/LabelGS.
Improving Subgraph Matching by Combining Algorithms and Graph Neural Networks
Jul 27, 2025Homomorphism is a key mapping technique between graphs that preserves their structure. Given a graph and a pattern, the subgraph homomorphism problem involves finding a mapping from the pattern to the graph, ensuring that adjacent vertices in the pattern are mapped to adjacent vertices in the graph. Unlike subgraph isomorphism, which requires a one-to-one mapping, homomorphism allows multiple vertices in the pattern to map to the same vertex in the graph, making it more complex. We propose HFrame, the first graph neural network-based framework for subgraph homomorphism, which integrates traditional algorithms with machine learning techniques. We demonstrate that HFrame outperforms standard graph neural networks by being able to distinguish more graph pairs where the pattern is not homomorphic to the graph. Additionally, we provide a generalization error bound for HFrame. Through experiments on both real-world and synthetic graphs, we show that HFrame is up to 101.91 times faster than exact matching algorithms and achieves an average accuracy of 0.962.
Dynamic-DINO: Fine-Grained Mixture of Experts Tuning for Real-time Open-Vocabulary Object Detection
Jul 23, 2025



The Mixture of Experts (MoE) architecture has excelled in Large Vision-Language Models (LVLMs), yet its potential in real-time open-vocabulary object detectors, which also leverage large-scale vision-language datasets but smaller models, remains unexplored. This work investigates this domain, revealing intriguing insights. In the shallow layers, experts tend to cooperate with diverse peers to expand the search space. While in the deeper layers, fixed collaborative structures emerge, where each expert maintains 2-3 fixed partners and distinct expert combinations are specialized in processing specific patterns. Concretely, we propose Dynamic-DINO, which extends Grounding DINO 1.5 Edge from a dense model to a dynamic inference framework via an efficient MoE-Tuning strategy. Additionally, we design a granularity decomposition mechanism to decompose the Feed-Forward Network (FFN) of base model into multiple smaller expert networks, expanding the subnet search space. To prevent performance degradation at the start of fine-tuning, we further propose a pre-trained weight allocation strategy for the experts, coupled with a specific router initialization. During inference, only the input-relevant experts are activated to form a compact subnet. Experiments show that, pretrained with merely 1.56M open-source data, Dynamic-DINO outperforms Grounding DINO 1.5 Edge, pretrained on the private Grounding20M dataset.
Crowd Detection Using Very-Fine-Resolution Satellite Imagery
Apr 28, 2025Accurate crowd detection (CD) is critical for public safety and historical pattern analysis, yet existing methods relying on ground and aerial imagery suffer from limited spatio-temporal coverage. The development of very-fine-resolution (VFR) satellite sensor imagery (e.g., ~0.3 m spatial resolution) provides unprecedented opportunities for large-scale crowd activity analysis, but it has never been considered for this task. To address this gap, we proposed CrowdSat-Net, a novel point-based convolutional neural network, which features two innovative components: Dual-Context Progressive Attention Network (DCPAN) to improve feature representation of individuals by aggregating scene context and local individual characteristics, and High-Frequency Guided Deformable Upsampler (HFGDU) that recovers high-frequency information during upsampling through frequency-domain guided deformable convolutions. To validate the effectiveness of CrowdSat-Net, we developed CrowdSat, the first VFR satellite imagery dataset designed specifically for CD tasks, comprising over 120k manually labeled individuals from multi-source satellite platforms (Beijing-3N, Jilin-1 Gaofen-04A and Google Earth) across China. In the experiments, CrowdSat-Net was compared with five state-of-the-art point-based CD methods (originally designed for ground or aerial imagery) using CrowdSat and achieved the largest F1-score of 66.12% and Precision of 73.23%, surpassing the second-best method by 1.71% and 2.42%, respectively. Moreover, extensive ablation experiments validated the importance of the DCPAN and HFGDU modules. Furthermore, cross-regional evaluation further demonstrated the spatial generalizability of CrowdSat-Net. This research advances CD capability by providing both a newly developed network architecture for CD and a pioneering benchmark dataset to facilitate future CD development.
Reflective Instruction Tuning: Mitigating Hallucinations in Large Vision-Language Models
Jul 16, 2024



Large vision-language models (LVLMs) have shown promising performance on a variety of vision-language tasks. However, they remain susceptible to hallucinations, generating outputs misaligned with visual content or instructions. While various mitigation strategies have been proposed, they often neglect a key contributor to hallucinations: lack of fine-grained reasoning supervision during training. Without intermediate reasoning steps, models may establish superficial shortcuts between instructions and responses, failing to internalize the inherent reasoning logic. To address this challenge, we propose reflective instruction tuning, which integrates rationale learning into visual instruction tuning. Unlike previous methods that learning from responses only, our approach entails the model predicting rationales justifying why responses are correct or incorrect. This fosters a deeper engagement with the fine-grained reasoning underlying each response, thus enhancing the model's reasoning proficiency. To facilitate this approach, we propose REVERIE, the first large-scale instruction-tuning dataset with ReflEctiVE RatIonalE annotations. REVERIE comprises 115k machine-generated reasoning instructions, each meticulously annotated with a corresponding pair of correct and confusing responses, alongside comprehensive rationales elucidating the justification behind the correctness or erroneousness of each response. Experimental results on multiple LVLM benchmarks reveal that reflective instruction tuning with the REVERIE dataset yields noticeable performance gain over the baseline model, demonstrating the effectiveness of reflecting from the rationales. Project page is at https://zjr2000.github.io/projects/reverie.
A Brief Review of Hypernetworks in Deep Learning
Jun 12, 2023Hypernetworks, or hypernets in short, are neural networks that generate weights for another neural network, known as the target network. They have emerged as a powerful deep learning technique that allows for greater flexibility, adaptability, faster training, information sharing, and model compression etc. Hypernets have shown promising results in a variety of deep learning problems, including continual learning, causal inference, transfer learning, weight pruning, uncertainty quantification, zero-shot learning, natural language processing, and reinforcement learning etc. Despite their success across different problem settings, currently, there is no review available to inform the researchers about the developments and help in utilizing hypernets. To fill this gap, we review the progress in hypernets. We present an illustrative example to train deep neural networks using hypernets and propose to categorize hypernets on five criteria that affect the design of hypernets as inputs, outputs, variability of inputs and outputs, and architecture of hypernets. We also review applications of hypernets across different deep learning problem settings. Finally, we discuss the challenges and future directions that remain under-explored in the field of hypernets. We believe that hypernetworks have the potential to revolutionize the field of deep learning. They offer a new way to design and train neural networks, and they have the potential to improve the performance of deep learning models on a variety of tasks. Through this review, we aim to inspire further advancements in deep learning through hypernetworks.
Channel Estimation for Wideband MmWave MIMO OFDM System Exploiting Block Sparsity
Mar 12, 2022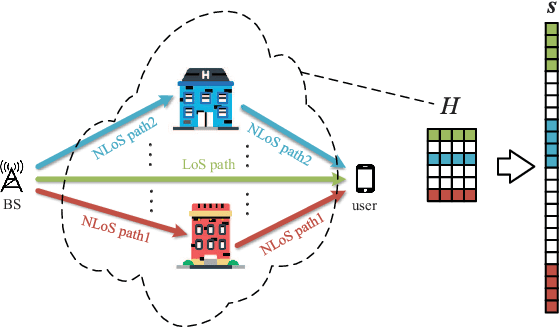
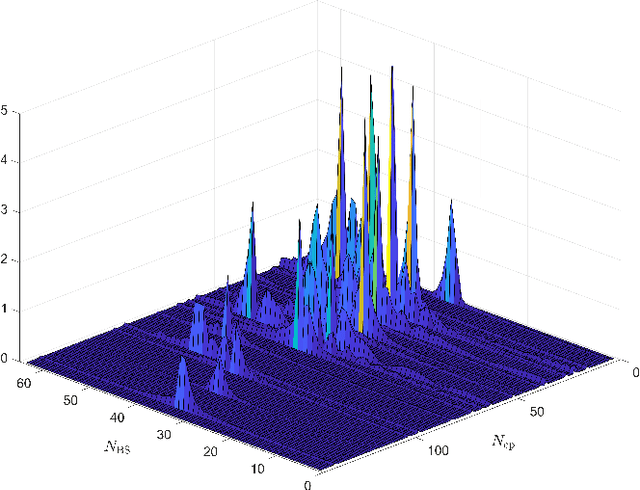
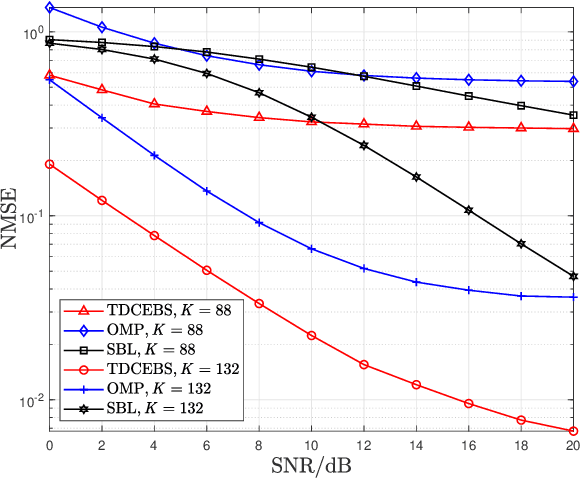
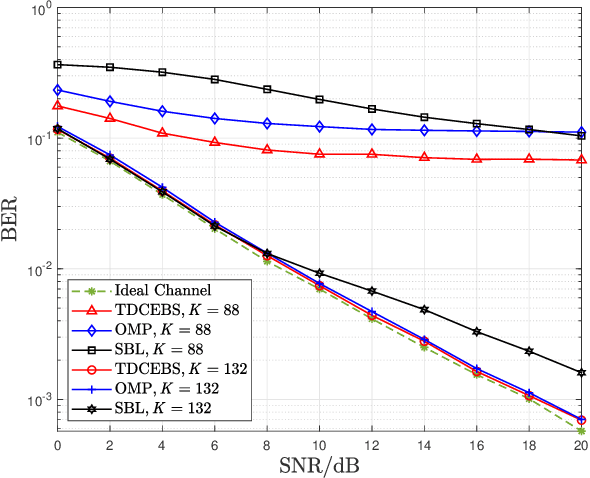
In this letter, we investigate time-domain channel estimation for wideband millimeter wave (mmWave) MIMO OFDM system. By transmitting frequency-domain pilot symbols as well as different beamforming vectors, we observe that the time-domain mmWave MIMO channels exhibit channel delay sparsity and especially block sparsity among different spatial directions. Then we propose a time-domain channel estimation exploiting block sparsity (TDCEBS) scheme, which always aims at finding the best nonzero block achieving the largest projection of the residue at each iterations. In particular, we evaluate the system performance using the QuaDRiGa which is recommended by 5G New Radio to generate wideband mmWave MIMO channels. The effectiveness of the proposed TDCEBS scheme is verified by the simulation results, as the proposed scheme outperforms the existing schemes.
Attenuating Random Noise in Seismic Data by a Deep Learning Approach
Oct 28, 2019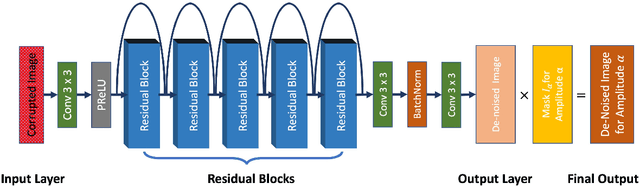
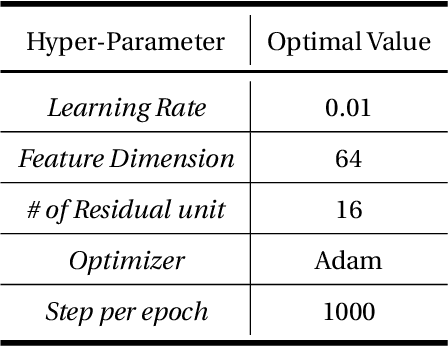
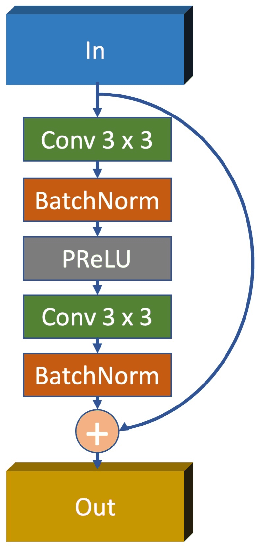
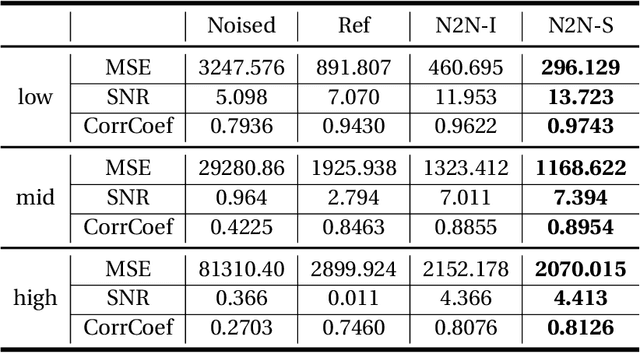
In the geophysical field, seismic noise attenuation has been considered as a critical and long-standing problem, especially for the pre-stack data processing. Here, we propose a model to leverage the deep-learning model for this task. Rather than directly applying an existing de-noising model from ordinary images to the seismic data, we have designed a particular deep-learning model, based on residual neural networks. It is named as N2N-Seismic, which has a strong ability to recover the seismic signals back to intact condition with the preservation of primary signals. The proposed model, achieving with great success in attenuating noise, has been tested on two different seismic datasets. Several metrics show that our method outperforms conventional approaches in terms of Signal-to-Noise-Ratio, Mean-Squared-Error, Phase Spectrum, etc. Moreover, robust tests in terms of effectively removing random noise from any dataset with strong and weak noises have been extensively scrutinized in making sure that the proposed model is able to maintain a good level of adaptation while dealing with large variations of noise characteristics and intensities.