 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Conditional Hidden Markov Model for Weakly Supervised Named Entity Recognition
Jun 07, 2022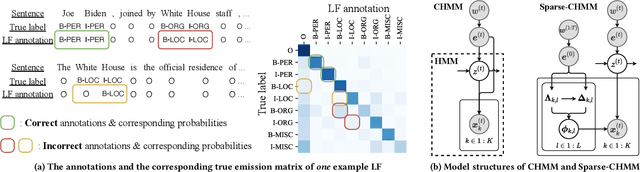

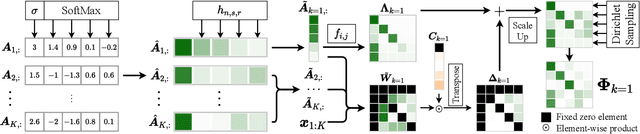
Weakly supervised named entity recognition methods train label models to aggregate the token annotations of multiple noisy labeling functions (LFs) without seeing any manually annotated labels. To work well, the label model needs to contextually identify and emphasize well-performed LFs while down-weighting the under-performers. However, evaluating the LFs is challenging due to the lack of ground truths. To address this issue, we propose the sparse conditional hidden Markov model (Sparse-CHMM). Instead of predicting the entire emission matrix as other HMM-based methods, Sparse-CHMM focuses on estimating its diagonal elements, which are considered as the reliability scores of the LFs. The sparse scores are then expanded to the full-fledged emission matrix with pre-defined expansion functions. We also augment the emission with weighted XOR scores, which track the probabilities of an LF observing incorrect entities. Sparse-CHMM is optimized through unsupervised learning with a three-stage training pipeline that reduces the training difficulty and prevents the model from falling into local optima. Compared with the baselines in the Wrench benchmark, Sparse-CHMM achieves a 3.01 average F1 score improvement on five comprehensive datasets. Experiments show that each component of Sparse-CHMM is effective, and the estimated LF reliabilities strongly correlate with true LF F1 scores.
PRBoost: Prompt-Based Rule Discovery and Boosting for Interactive Weakly-Supervised Learning
Mar 18, 2022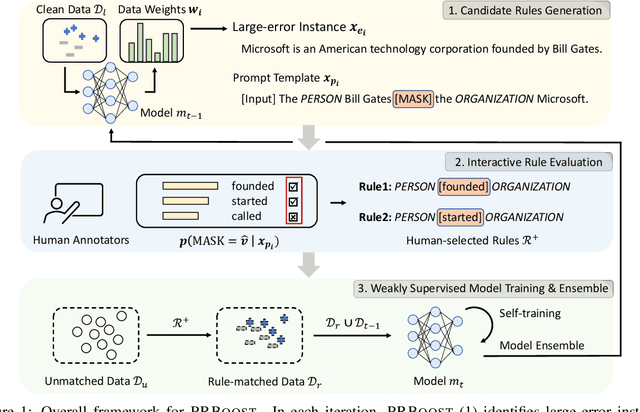

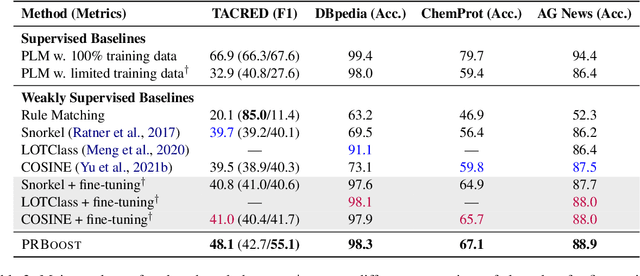
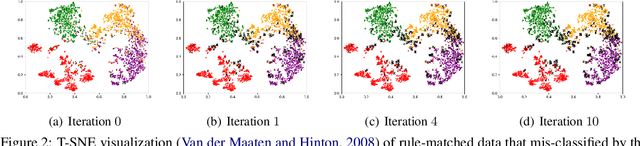
Weakly-supervised learning (WSL) has shown promising results in addressing label scarcity on many NLP tasks, but manually designing a comprehensive, high-quality labeling rule set is tedious and difficult. We study interactive weakly-supervised learning -- the problem of iteratively and automatically discovering novel labeling rules from data to improve the WSL model. Our proposed model, named PRBoost, achieves this goal via iterative prompt-based rule discovery and model boosting. It uses boosting to identify large-error instances and then discovers candidate rules from them by prompting pre-trained LMs with rule templates. The candidate rules are judged by human experts, and the accepted rules are used to generate complementary weak labels and strengthen the current model. Experiments on four tasks show PRBoost outperforms state-of-the-art WSL baselines up to 7.1% and bridges the gaps with fully supervised models. Our Implementation is available at \url{https://github.com/rz-zhang/PRBoost}.
* ACL 2022 (Main Conference). Code: https://github.com/rz-zhang/PRBoost
Molecule Generation for Drug Design: a Graph Learning Perspective
Feb 18, 2022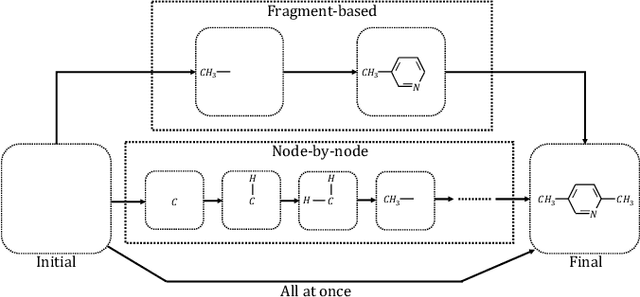
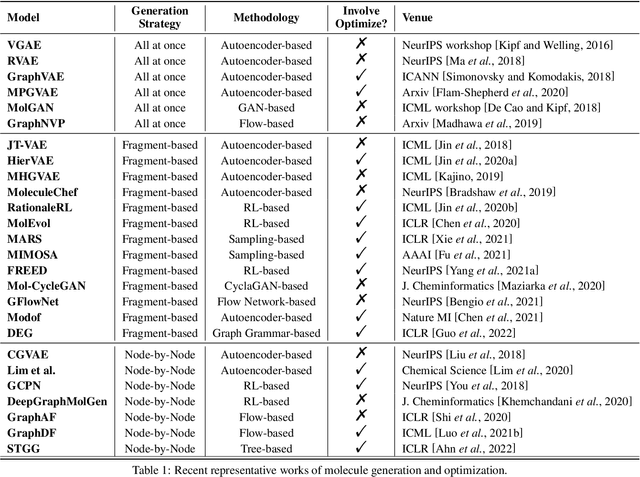
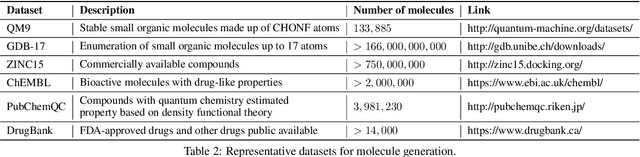
Machine learning has revolutionized many fields, and graph learning is recently receiving increasing attention. From the application perspective, one of the emerging and attractive areas is aiding the design and discovery of molecules, especially in drug industry. In this survey, we provide an overview of the state-of-the-art molecule (and mostly for de novo drug) design and discovery aiding methods whose methodology involves (deep) graph learning. Specifically, we propose to categorize these methods into three groups: i) all at once, ii) fragment-based and iii) node-by-node. We further present some representative public datasets and summarize commonly utilized evaluation metrics for generation and optimization, respectively. Finally, we discuss challenges and directions for future research, from the drug design perspective.
Learning Temporal Rules from Noisy Timeseries Data
Feb 11, 2022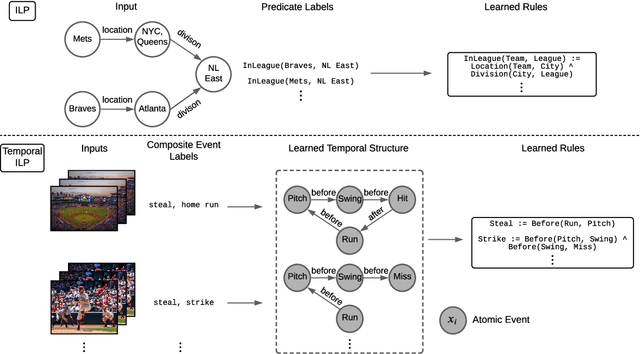
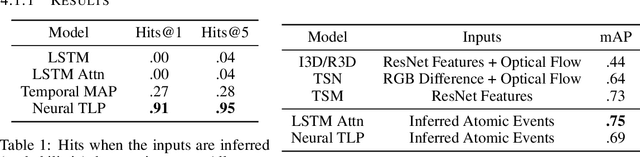
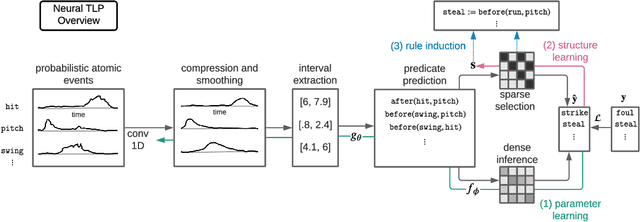
Events across a timeline are a common data representation, seen in different temporal modalities. Individual atomic events can occur in a certain temporal ordering to compose higher level composite events. Examples of a composite event are a patient's medical symptom or a baseball player hitting a home run, caused distinct temporal orderings of patient vitals and player movements respectively. Such salient composite events are provided as labels in temporal datasets and most works optimize models to predict these composite event labels directly. We focus on uncovering the underlying atomic events and their relations that lead to the composite events within a noisy temporal data setting. We propose Neural Temporal Logic Programming (Neural TLP) which first learns implicit temporal relations between atomic events and then lifts logic rules for composite events, given only the composite events labels for supervision. This is done through efficiently searching through the combinatorial space of all temporal logic rules in an end-to-end differentiable manner. We evaluate our method on video and healthcare datasets where it outperforms the baseline methods for rule discovery.
Efficient Dynamic Graph Representation Learning at Scale
Dec 14, 2021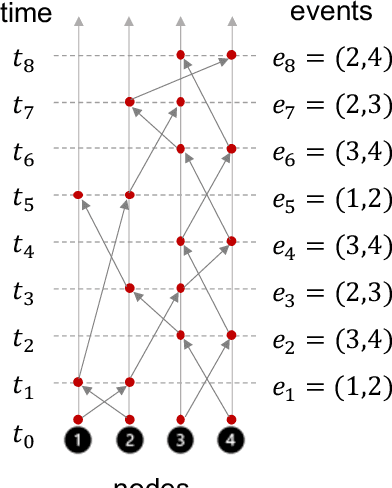
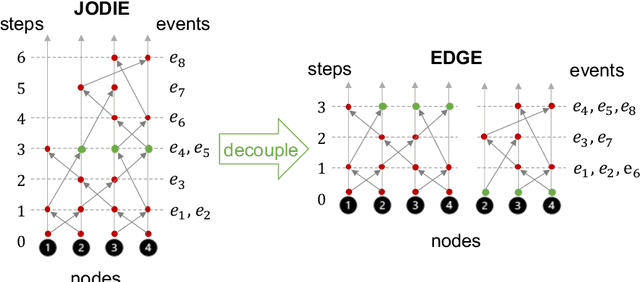
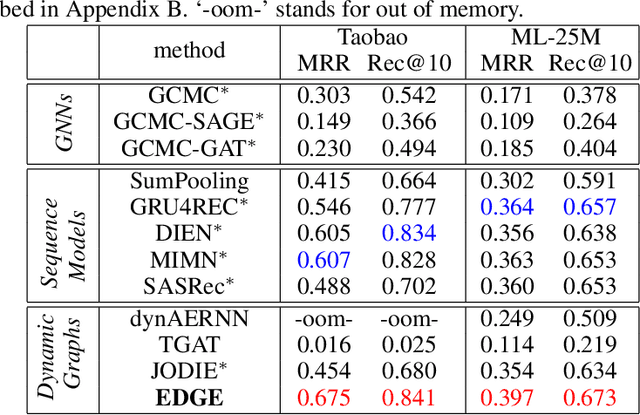
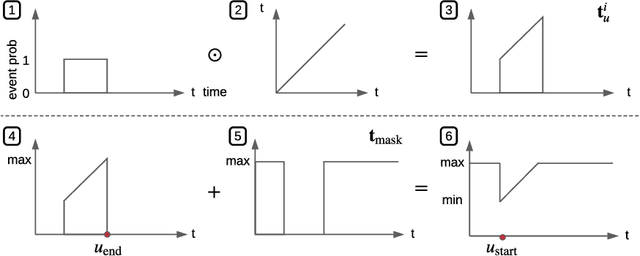
Dynamic graphs with ordered sequences of events between nodes are prevalent in real-world industrial applications such as e-commerce and social platforms. However, representation learning for dynamic graphs has posed great computational challenges due to the time and structure dependency and irregular nature of the data, preventing such models from being deployed to real-world applications. To tackle this challenge, we propose an efficient algorithm, Efficient Dynamic Graph lEarning (EDGE), which selectively expresses certain temporal dependency via training loss to improve the parallelism in computations. We show that EDGE can scale to dynamic graphs with millions of nodes and hundreds of millions of temporal events and achieve new state-of-the-art (SOTA) performance.
Molecular Attributes Transfer from Non-Parallel Data
Nov 30, 2021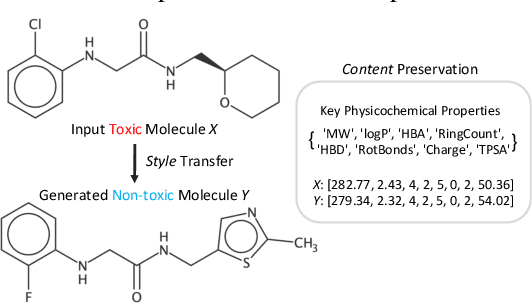
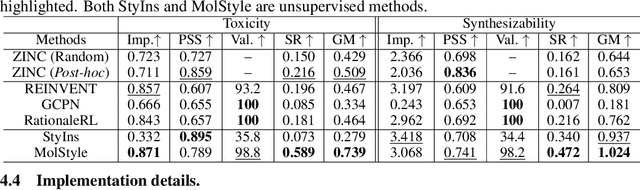
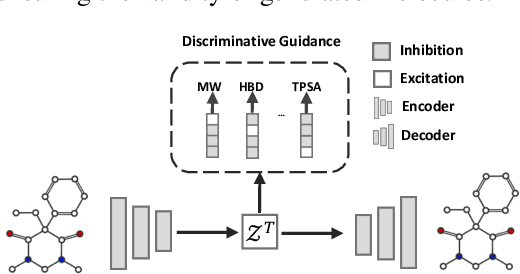
Optimizing chemical molecules for desired properties lies at the core of drug development. Despite initial successes made by deep generative models and reinforcement learning methods, these methods were mostly limited by the requirement of predefined attribute functions or parallel data with manually pre-compiled pairs of original and optimized molecules. In this paper, for the first time, we formulate molecular optimization as a style transfer problem and present a novel generative model that could automatically learn internal differences between two groups of non-parallel data through adversarial training strategies. Our model further enables both preservation of molecular contents and optimization of molecular properties through combining auxiliary guided-variational autoencoders and generative flow techniques. Experiments on two molecular optimization tasks, toxicity modification and synthesizability improvement, demonstrate that our model significantly outperforms several state-of-the-art methods.
A General Framework for Lifelong Localization and Mapping in Changing Environment
Nov 22, 2021
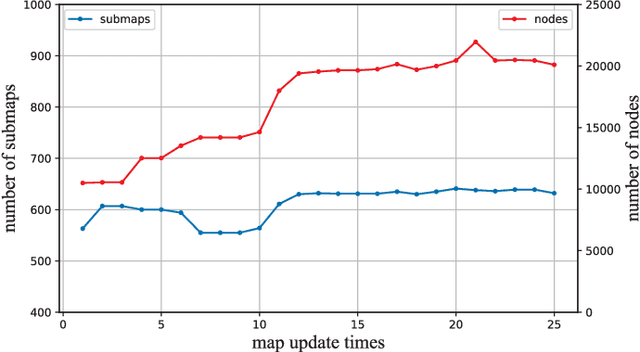
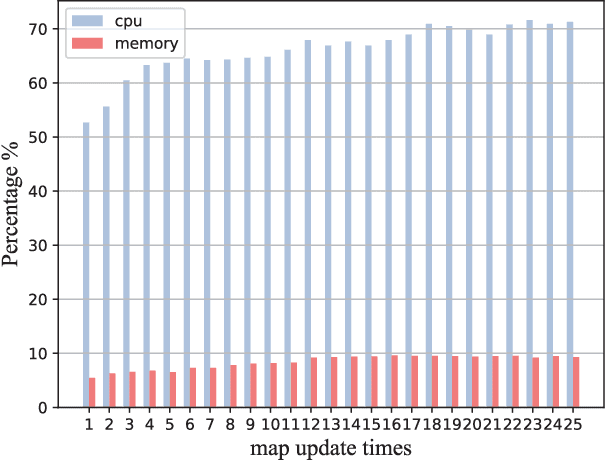
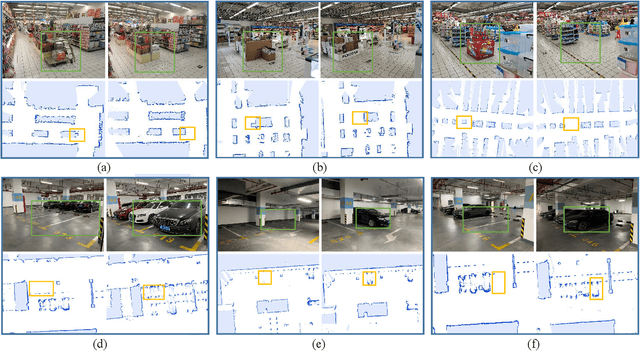
The environment of most real-world scenarios such as malls and supermarkets changes at all times. A pre-built map that does not account for these changes becomes out-of-date easily. Therefore, it is necessary to have an up-to-date model of the environment to facilitate long-term operation of a robot. To this end, this paper presents a general lifelong simultaneous localization and mapping (SLAM) framework. Our framework uses a multiple session map representation, and exploits an efficient map updating strategy that includes map building, pose graph refinement and sparsification. To mitigate the unbounded increase of memory usage, we propose a map-trimming method based on the Chow-Liu maximum-mutual-information spanning tree. The proposed SLAM framework has been comprehensively validated by over a month of robot deployment in real supermarket environment. Furthermore, we release the dataset collected from the indoor and outdoor changing environment with the hope to accelerate lifelong SLAM research in the community. Our dataset is available at https://github.com/sanduan168/lifelong-SLAM-dataset.
Multi-task Learning of Order-Consistent Causal Graphs
Nov 03, 2021


We consider the problem of discovering $K$ related Gaussian directed acyclic graphs (DAGs), where the involved graph structures share a consistent causal order and sparse unions of supports. Under the multi-task learning setting, we propose a $l_1/l_2$-regularized maximum likelihood estimator (MLE) for learning $K$ linear structural equation models. We theoretically show that the joint estimator, by leveraging data across related tasks, can achieve a better sample complexity for recovering the causal order (or topological order) than separate estimations. Moreover, the joint estimator is able to recover non-identifiable DAGs, by estimating them together with some identifiable DAGs. Lastly, our analysis also shows the consistency of union support recovery of the structures. To allow practical implementation, we design a continuous optimization problem whose optimizer is the same as the joint estimator and can be approximated efficiently by an iterative algorithm. We validate the theoretical analysis and the effectiveness of the joint estimator in experiments.
RoMA: Robust Model Adaptation for Offline Model-based Optimization
Oct 27, 2021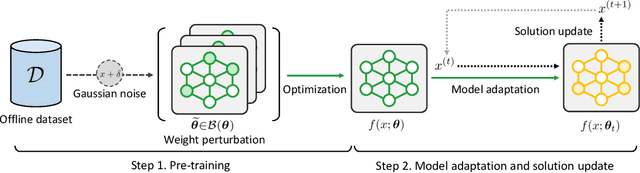
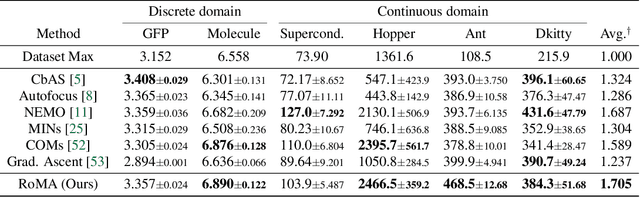
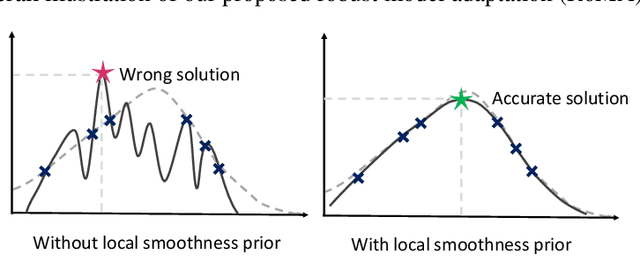
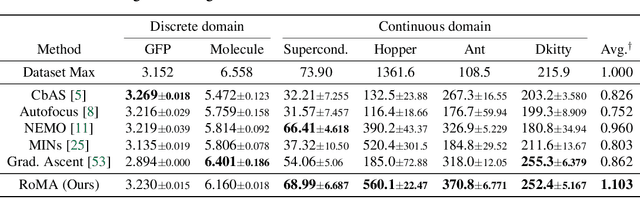
We consider the problem of searching an input maximizing a black-box objective function given a static dataset of input-output queries. A popular approach to solving this problem is maintaining a proxy model, e.g., a deep neural network (DNN), that approximates the true objective function. Here, the main challenge is how to avoid adversarially optimized inputs during the search, i.e., the inputs where the DNN highly overestimates the true objective function. To handle the issue, we propose a new framework, coined robust model adaptation (RoMA), based on gradient-based optimization of inputs over the DNN. Specifically, it consists of two steps: (a) a pre-training strategy to robustly train the proxy model and (b) a novel adaptation procedure of the proxy model to have robust estimates for a specific set of candidate solutions. At a high level, our scheme utilizes the local smoothness prior to overcome the brittleness of the DNN. Experiments under various tasks show the effectiveness of RoMA compared with previous methods, obtaining state-of-the-art results, e.g., RoMA outperforms all at 4 out of 6 tasks and achieves runner-up results at the remaining tasks.
Efficient Learning and Decoding of the Continuous-Time Hidden Markov Model for Disease Progression Modeling
Oct 26, 2021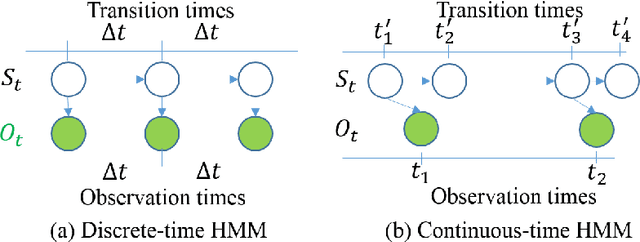

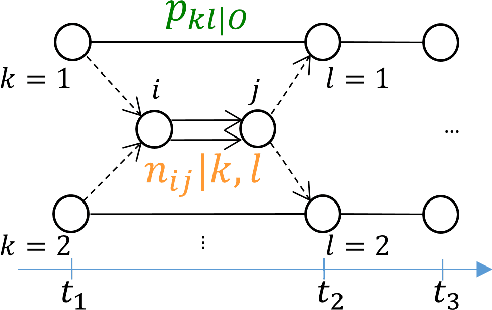
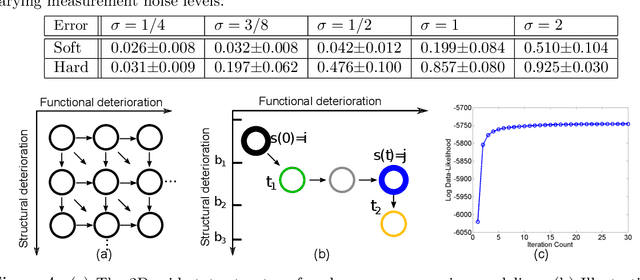
The Continuous-Time Hidden Markov Model (CT-HMM) is an attractive approach to modeling disease progression due to its ability to describe noisy observations arriving irregularly in time. However, the lack of an efficient parameter learning algorithm for CT-HMM restricts its use to very small models or requires unrealistic constraints on the state transitions. In this paper, we present the first complete characterization of efficient EM-based learning methods for CT-HMM models, as well as the first solution to decoding the optimal state transition sequence and the corresponding state dwelling time. We show that EM-based learning consists of two challenges: the estimation of posterior state probabilities and the computation of end-state conditioned statistics. We solve the first challenge by reformulating the estimation problem as an equivalent discrete time-inhomogeneous hidden Markov model. The second challenge is addressed by adapting three distinct approaches from the continuous time Markov chain (CTMC) literature to the CT-HMM domain. Additionally, we further improve the efficiency of the most efficient method by a factor of the number of states. Then, for decoding, we incorporate a state-of-the-art method from the (CTMC) literature, and extend the end-state conditioned optimal state sequence decoding to the CT-HMM case with the computation of the expected state dwelling time. We demonstrate the use of CT-HMMs with more than 100 states to visualize and predict disease progression using a glaucoma dataset and an Alzheimer's disease dataset, and to decode and visualize the most probable state transition trajectory for individuals on the glaucoma dataset, which helps to identify progressing phenotypes in a comprehensive way. Finally, we apply the CT-HMM modeling and decoding strategy to investigate the progression of language acquisition and development.