 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Learning Geometric Eigen-Lengths Crucial for Fitting Tasks
Dec 25, 2023Some extremely low-dimensional yet crucial geometric eigen-lengths often determine the success of some geometric tasks. For example, the height of an object is important to measure to check if it can fit between the shelves of a cabinet, while the width of a couch is crucial when trying to move it through a doorway. Humans have materialized such crucial geometric eigen-lengths in common sense since they are very useful in serving as succinct yet effective, highly interpretable, and universal object representations. However, it remains obscure and underexplored if learning systems can be equipped with similar capabilities of automatically discovering such key geometric quantities from doing tasks. In this work, we therefore for the first time formulate and propose a novel learning problem on this question and set up a benchmark suite including tasks, data, and evaluation metrics for studying the problem. We focus on a family of common fitting tasks as the testbed for the proposed learning problem. We explore potential solutions and demonstrate the feasibility of learning eigen-lengths from simply observing successful and failed fitting trials. We also attempt geometric grounding for more accurate eigen-length measurement and study the reusability of the learned eigen-lengths across multiple tasks. Our work marks the first exploratory step toward learning crucial geometric eigen-lengths and we hope it can inspire future research in tackling this important yet underexplored problem.
* ICML 2023. Project page: https://yijiaweng.github.io/geo-eigen-length
STOW: Discrete-Frame Segmentation and Tracking of Unseen Objects for Warehouse Picking Robots
Nov 04, 2023



Segmentation and tracking of unseen object instances in discrete frames pose a significant challenge in dynamic industrial robotic contexts, such as distribution warehouses. Here, robots must handle object rearrangement, including shifting, removal, and partial occlusion by new items, and track these items after substantial temporal gaps. The task is further complicated when robots encounter objects not learned in their training sets, which requires the ability to segment and track previously unseen items. Considering that continuous observation is often inaccessible in such settings, our task involves working with a discrete set of frames separated by indefinite periods during which substantial changes to the scene may occur. This task also translates to domestic robotic applications, such as rearrangement of objects on a table. To address these demanding challenges, we introduce new synthetic and real-world datasets that replicate these industrial and household scenarios. We also propose a novel paradigm for joint segmentation and tracking in discrete frames along with a transformer module that facilitates efficient inter-frame communication. The experiments we conduct show that our approach significantly outperforms recent methods. For additional results and videos, please visit \href{https://sites.google.com/view/stow-corl23}{website}. Code and dataset will be released.
Where2Explore: Few-shot Affordance Learning for Unseen Novel Categories of Articulated Objects
Sep 14, 2023



Articulated object manipulation is a fundamental yet challenging task in robotics. Due to significant geometric and semantic variations across object categories, previous manipulation models struggle to generalize to novel categories. Few-shot learning is a promising solution for alleviating this issue by allowing robots to perform a few interactions with unseen objects. However, extant approaches often necessitate costly and inefficient test-time interactions with each unseen instance. Recognizing this limitation, we observe that despite their distinct shapes, different categories often share similar local geometries essential for manipulation, such as pullable handles and graspable edges - a factor typically underutilized in previous few-shot learning works. To harness this commonality, we introduce 'Where2Explore', an affordance learning framework that effectively explores novel categories with minimal interactions on a limited number of instances. Our framework explicitly estimates the geometric similarity across different categories, identifying local areas that differ from shapes in the training categories for efficient exploration while concurrently transferring affordance knowledge to similar parts of the objects. Extensive experiments in simulated and real-world environments demonstrate our framework's capacity for efficient few-shot exploration and generalization.
JacobiNeRF: NeRF Shaping with Mutual Information Gradients
Apr 01, 2023We propose a method that trains a neural radiance field (NeRF) to encode not only the appearance of the scene but also semantic correlations between scene points, regions, or entities -- aiming to capture their mutual co-variation patterns. In contrast to the traditional first-order photometric reconstruction objective, our method explicitly regularizes the learning dynamics to align the Jacobians of highly-correlated entities, which proves to maximize the mutual information between them under random scene perturbations. By paying attention to this second-order information, we can shape a NeRF to express semantically meaningful synergies when the network weights are changed by a delta along the gradient of a single entity, region, or even a point. To demonstrate the merit of this mutual information modeling, we leverage the coordinated behavior of scene entities that emerges from our shaping to perform label propagation for semantic and instance segmentation. Our experiments show that a JacobiNeRF is more efficient in propagating annotations among 2D pixels and 3D points compared to NeRFs without mutual information shaping, especially in extremely sparse label regimes -- thus reducing annotation burden. The same machinery can further be used for entity selection or scene modifications.
Category-Level Multi-Part Multi-Joint 3D Shape Assembly
Mar 10, 2023



Shape assembly composes complex shapes geometries by arranging simple part geometries and has wide applications in autonomous robotic assembly and CAD modeling. Existing works focus on geometry reasoning and neglect the actual physical assembly process of matching and fitting joints, which are the contact surfaces connecting different parts. In this paper, we consider contacting joints for the task of multi-part assembly. A successful joint-optimized assembly needs to satisfy the bilateral objectives of shape structure and joint alignment. We propose a hierarchical graph learning approach composed of two levels of graph representation learning. The part graph takes part geometries as input to build the desired shape structure. The joint-level graph uses part joints information and focuses on matching and aligning joints. The two kinds of information are combined to achieve the bilateral objectives. Extensive experiments demonstrate that our method outperforms previous methods, achieving better shape structure and higher joint alignment accuracy.
SceneHGN: Hierarchical Graph Networks for 3D Indoor Scene Generation with Fine-Grained Geometry
Feb 16, 2023



3D indoor scenes are widely used in computer graphics, with applications ranging from interior design to gaming to virtual and augmented reality. They also contain rich information, including room layout, as well as furniture type, geometry, and placement. High-quality 3D indoor scenes are highly demanded while it requires expertise and is time-consuming to design high-quality 3D indoor scenes manually. Existing research only addresses partial problems: some works learn to generate room layout, and other works focus on generating detailed structure and geometry of individual furniture objects. However, these partial steps are related and should be addressed together for optimal synthesis. We propose SCENEHGN, a hierarchical graph network for 3D indoor scenes that takes into account the full hierarchy from the room level to the object level, then finally to the object part level. Therefore for the first time, our method is able to directly generate plausible 3D room content, including furniture objects with fine-grained geometry, and their layout. To address the challenge, we introduce functional regions as intermediate proxies between the room and object levels to make learning more manageable. To ensure plausibility, our graph-based representation incorporates both vertical edges connecting child nodes with parent nodes from different levels, and horizontal edges encoding relationships between nodes at the same level. Extensive experiments demonstrate that our method produces superior generation results, even when comparing results of partial steps with alternative methods that can only achieve these. We also demonstrate that our method is effective for various applications such as part-level room editing, room interpolation, and room generation by arbitrary room boundaries.
Seg&Struct: The Interplay Between Part Segmentation and Structure Inference for 3D Shape Parsing
Nov 01, 2022We propose Seg&Struct, a supervised learning framework leveraging the interplay between part segmentation and structure inference and demonstrating their synergy in an integrated framework. Both part segmentation and structure inference have been extensively studied in the recent deep learning literature, while the supervisions used for each task have not been fully exploited to assist the other task. Namely, structure inference has been typically conducted with an autoencoder that does not leverage the point-to-part associations. Also, segmentation has been mostly performed without structural priors that tell the plausibility of the output segments. We present how these two tasks can be best combined while fully utilizing supervision to improve performance. Our framework first decomposes a raw input shape into part segments using an off-the-shelf algorithm, whose outputs are then mapped to nodes in a part hierarchy, establishing point-to-part associations. Following this, ours predicts the structural information, e.g., part bounding boxes and part relationships. Lastly, the segmentation is rectified by examining the confusion of part boundaries using the structure-based part features. Our experimental results based on the StructureNet and PartNet demonstrate that the interplay between the two tasks results in remarkable improvements in both tasks: 27.91% in structure inference and 0.5% in segmentation.
COPILOT: Human Collision Prediction and Localization from Multi-view Egocentric Videos
Oct 04, 2022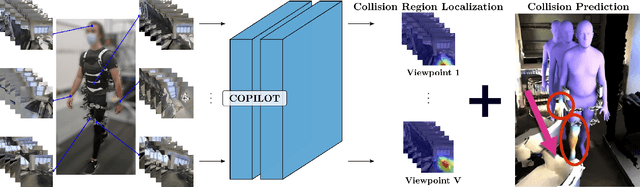
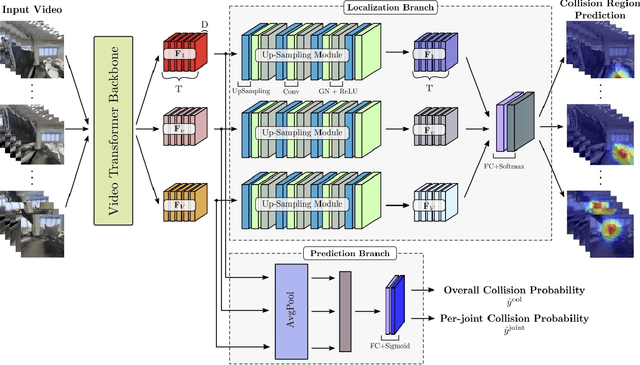
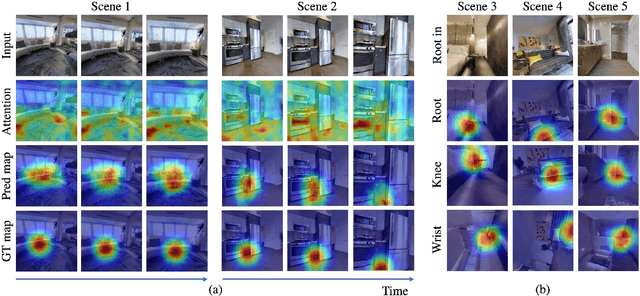
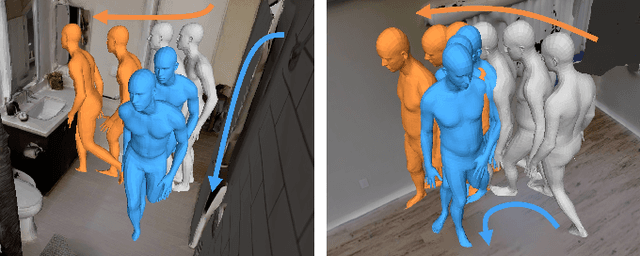
To produce safe human motions, assistive wearable exoskeletons must be equipped with a perception system that enables anticipating potential collisions from egocentric observations. However, previous approaches to exoskeleton perception greatly simplify the problem to specific types of environments, limiting their scalability. In this paper, we propose the challenging and novel problem of predicting human-scene collisions for diverse environments from multi-view egocentric RGB videos captured from an exoskeleton. By classifying which body joints will collide with the environment and predicting a collision region heatmap that localizes potential collisions in the environment, we aim to develop an exoskeleton perception system that generalizes to complex real-world scenes and provides actionable outputs for downstream control. We propose COPILOT, a video transformer-based model that performs both collision prediction and localization simultaneously, leveraging multi-view video inputs via a proposed joint space-time-viewpoint attention operation. To train and evaluate the model, we build a synthetic data generation framework to simulate virtual humans moving in photo-realistic 3D environments. This framework is then used to establish a dataset consisting of 8.6M egocentric RGBD frames to enable future work on the problem. Extensive experiments suggest that our model achieves promising performance and generalizes to unseen scenes as well as real world. We apply COPILOT to a downstream collision avoidance task, and successfully reduce collision cases by 29% on unseen scenes using a simple closed-loop control algorithm.
DualAfford: Learning Collaborative Visual Affordance for Dual-gripper Object Manipulation
Jul 05, 2022
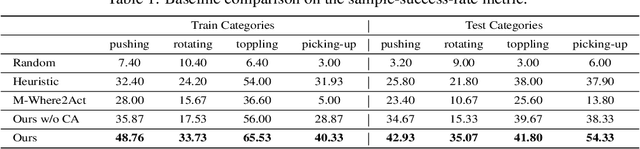


It is essential yet challenging for future home-assistant robots to understand and manipulate diverse 3D objects in daily human environments. Towards building scalable systems that can perform diverse manipulation tasks over various 3D shapes, recent works have advocated and demonstrated promising results learning visual actionable affordance, which labels every point over the input 3D geometry with an action likelihood of accomplishing the downstream task (e.g., pushing or picking-up). However, these works only studied single-gripper manipulation tasks, yet many real-world tasks require two hands to achieve collaboratively. In this work, we propose a novel learning framework, DualAfford, to learn collaborative affordance for dual-gripper manipulation tasks. The core design of the approach is to reduce the quadratic problem for two grippers into two disentangled yet interconnected subtasks for efficient learning. Using the large-scale PartNet-Mobility and ShapeNet datasets, we set up four benchmark tasks for dual-gripper manipulation. Experiments prove the effectiveness and superiority of our method over three baselines. Additional results and videos can be found at https://hyperplane-lab.github.io/DualAfford .
Fixing Malfunctional Objects With Learned Physical Simulation and Functional Prediction
May 05, 2022
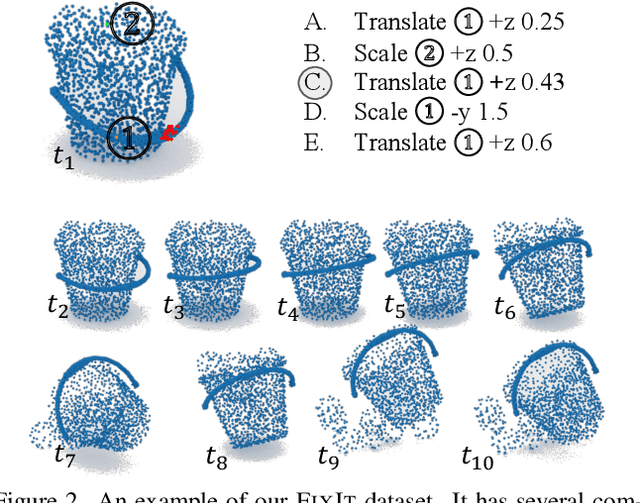
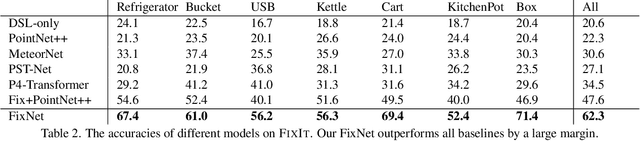
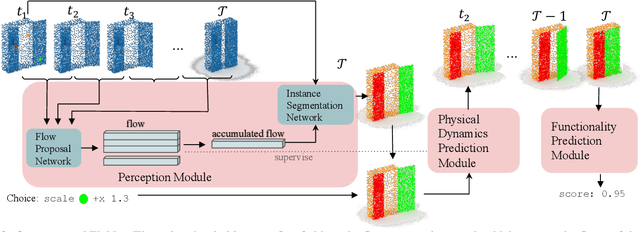
This paper studies the problem of fixing malfunctional 3D objects. While previous works focus on building passive perception models to learn the functionality from static 3D objects, we argue that functionality is reckoned with respect to the physical interactions between the object and the user. Given a malfunctional object, humans can perform mental simulations to reason about its functionality and figure out how to fix it. Inspired by this, we propose FixIt, a dataset that contains about 5k poorly-designed 3D physical objects paired with choices to fix them. To mimic humans' mental simulation process, we present FixNet, a novel framework that seamlessly incorporates perception and physical dynamics. Specifically, FixNet consists of a perception module to extract the structured representation from the 3D point cloud, a physical dynamics prediction module to simulate the results of interactions on 3D objects, and a functionality prediction module to evaluate the functionality and choose the correct fix. Experimental results show that our framework outperforms baseline models by a large margin, and can generalize well to objects with similar interaction types.