 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypergraph Convolutional Networks via Equivalency between Hypergraphs and Undirected Graphs
Apr 06, 2022
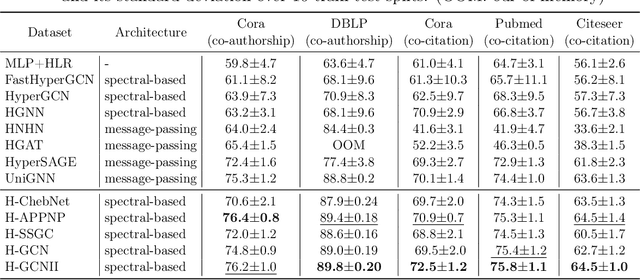
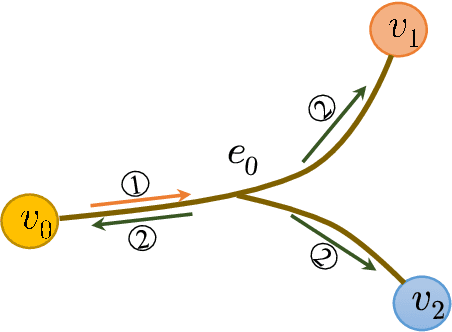

As a powerful tool for modeling complex relationships, hypergraphs are gaining popularity from the graph learning community. However, commonly used frameworks in deep hypergraph learning focus on hypergraphs with \textit{edge-independent vertex weights}(EIVWs), without considering hypergraphs with \textit{edge-dependent vertex weights} (EDVWs) that have more modeling power. To compensate for this, in this paper, we present General Hypergraph Spectral Convolution(GHSC), a general learning framework that not only can handle EDVW and EIVW hypergraphs, but more importantly, enables theoretically explicitly utilizing the existing powerful Graph Convolutional Neural Networks (GCNNs) such that largely ease the design of Hypergraph Neural Networks. In this framework, the graph Laplacian of the given undirected GCNNs is replaced with a unified hypergraph Laplacian that incorporates vertex weight information from a random walk perspective by equating our defined generalized hypergraphs with simple undirected graphs. Extensive experiments from various domains including social network analysis, visual objective classification, protein learning demonstrate that the proposed framework can achieve state-of-the-art performance.
Vision-Language Pre-Training with Triple Contrastive Learning
Mar 28, 2022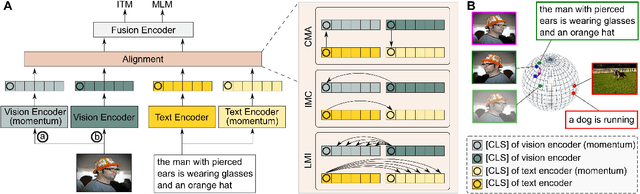

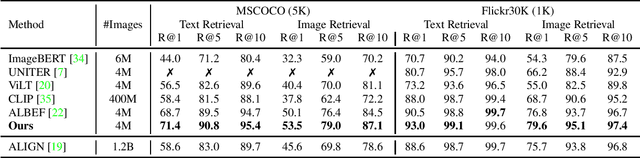
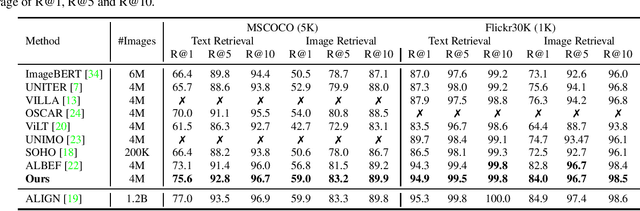
Vision-language representation learning largely benefits from image-text alignment through contrastive losses (e.g., InfoNCE loss). The success of this alignment strategy is attributed to its capability in maximizing the mutual information (MI) between an image and its matched text. However, simply performing cross-modal alignment (CMA) ignores data potential within each modality, which may result in degraded representations. For instance, although CMA-based models are able to map image-text pairs close together in the embedding space, they fail to ensure that similar inputs from the same modality stay close by. This problem can get even worse when the pre-training data is noisy. In this paper, we propose triple contrastive learning (TCL) for vision-language pre-training by leveraging both cross-modal and intra-modal self-supervision. Besides CMA, TCL introduces an intra-modal contrastive objective to provide complementary benefits in representation learning. To take advantage of localized and structural information from image and text input, TCL further maximizes the average MI between local regions of image/text and their global summary. To the best of our knowledge, ours is the first work that takes into account local structure information for multi-modality representation learning. Experimental evaluations show that our approach is competitive and achieves the new state of the art on various common down-stream vision-language tasks such as image-text retrieval and visual question answering.
Boost Test-Time Performance with Closed-Loop Inference
Mar 26, 2022
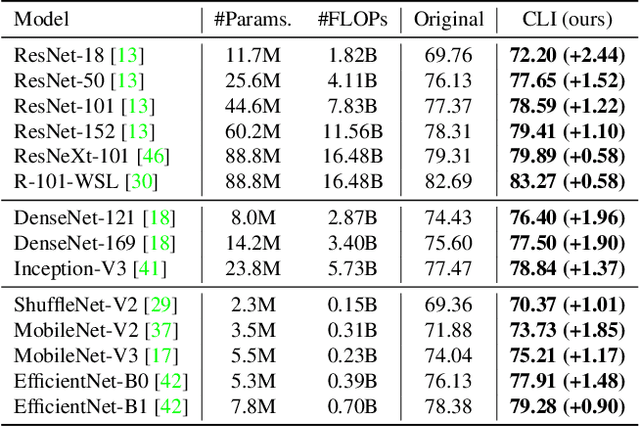
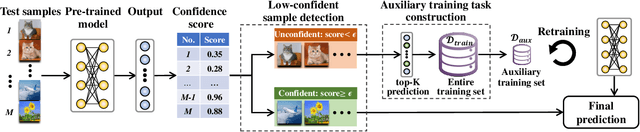
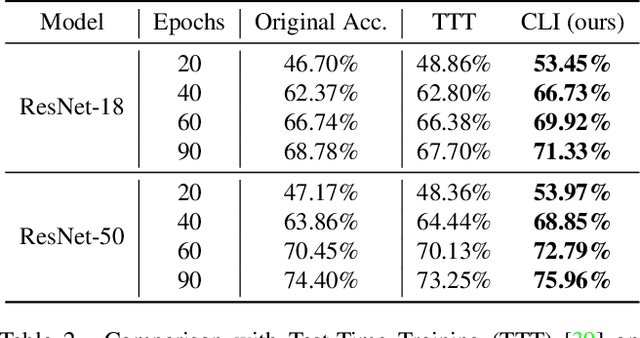
Conventional deep models predict a test sample with a single forward propagation, which, however, may not be sufficient for predicting hard-classified samples. On the contrary, we human beings may need to carefully check the sample many times before making a final decision. During the recheck process, one may refine/adjust the prediction by referring to related samples. Motivated by this, we propose to predict those hard-classified test samples in a looped manner to boost the model performance. However, this idea may pose a critical challenge: how to construct looped inference, so that the original erroneous predictions on these hard test samples can be corrected with little additional effort. To address this, we propose a general Closed-Loop Inference (CLI) method. Specifically, we first devise a filtering criterion to identify those hard-classified test samples that need additional inference loops. For each hard sample, we construct an additional auxiliary learning task based on its original top-$K$ predictions to calibrate the model, and then use the calibrated model to obtain the final prediction. Promising results on ImageNet (in-distribution test samples) and ImageNet-C (out-of-distribution test samples) demonstrate the effectiveness of CLI in improving the performance of any pre-trained model.
Equivariant Graph Mechanics Networks with Constraints
Mar 12, 2022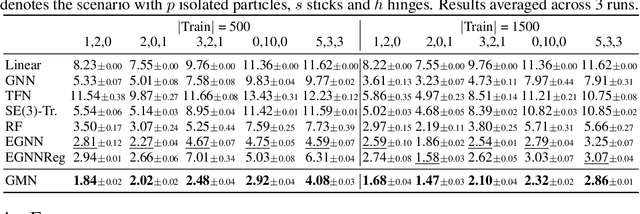
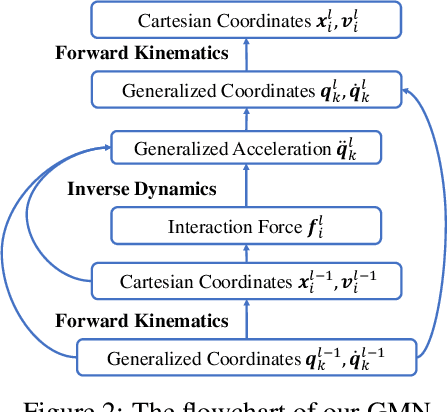
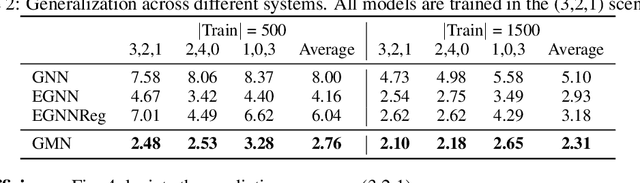
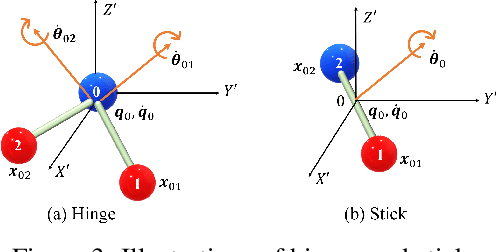
Learning to reason about relations and dynamics over multiple interacting objects is a challenging topic in machine learning. The challenges mainly stem from that the interacting systems are exponentially-compositional, symmetrical, and commonly geometrically-constrained. Current methods, particularly the ones based on equivariant Graph Neural Networks (GNNs), have targeted on the first two challenges but remain immature for constrained systems. In this paper, we propose Graph Mechanics Network (GMN) which is combinatorially efficient, equivariant and constraint-aware. The core of GMN is that it represents, by generalized coordinates, the forward kinematics information (positions and velocities) of a structural object. In this manner, the geometrical constraints are implicitly and naturally encoded in the forward kinematics. Moreover, to allow equivariant message passing in GMN, we have developed a general form of orthogonality-equivariant functions, given that the dynamics of constrained systems are more complicated than the unconstrained counterparts. Theoretically, the proposed equivariant formulation is proved to be universally expressive under certain conditions. Extensive experiments support the advantages of GMN compared to the state-of-the-art GNNs in terms of prediction accuracy, constraint satisfaction and data efficiency on the simulated systems consisting of particles, sticks and hinges, as well as two real-world datasets for molecular dynamics prediction and human motion capture.
Transformer for Graphs: An Overview from Architecture Perspective
Feb 17, 2022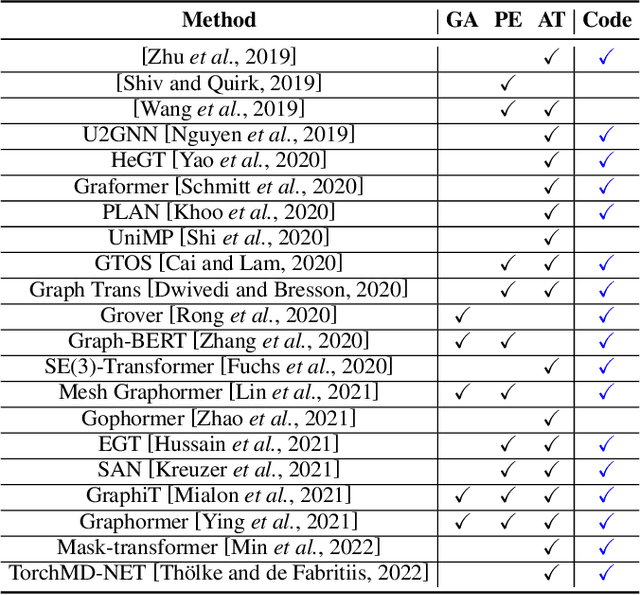
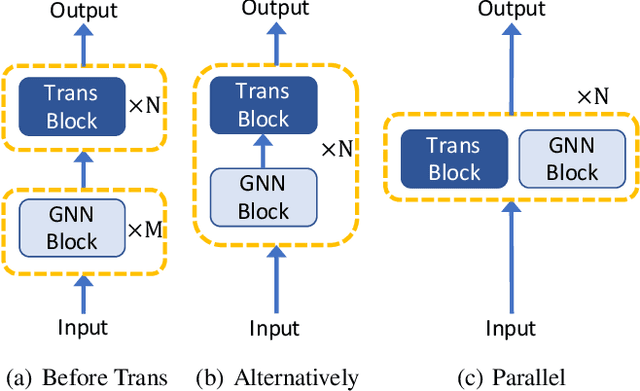
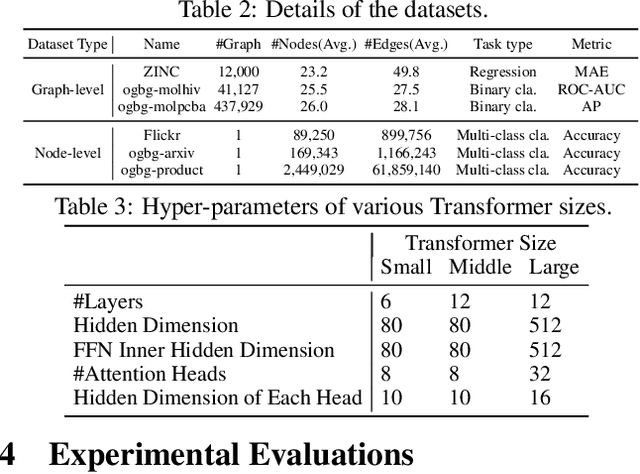
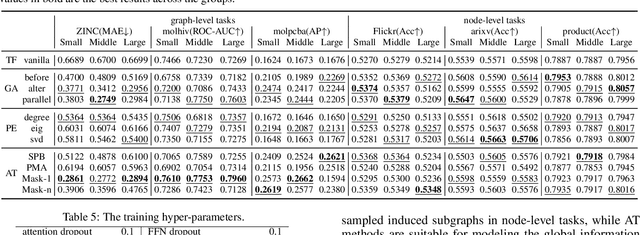
Recently, Transformer model, which has achieved great success in many artificial intelligence fields, has demonstrated its great potential in modeling graph-structured data. Till now, a great variety of Transformers has been proposed to adapt to the graph-structured data. However, a comprehensive literature review and systematical evaluation of these Transformer variants for graphs are still unavailable. It's imperative to sort out the existing Transformer models for graphs and systematically investigate their effectiveness on various graph tasks. In this survey, we provide a comprehensive review of various Graph Transformer models from the architectural design perspective. We first disassemble the existing models and conclude three typical ways to incorporate the graph information into the vanilla Transformer: 1) GNNs as Auxiliary Modules, 2) Improved Positional Embedding from Graphs, and 3) Improved Attention Matrix from Graphs. Furthermore, we implement the representative components in three groups and conduct a comprehensive comparison on various kinds of famous graph data benchmarks to investigate the real performance gain of each component. Our experiments confirm the benefits of current graph-specific modules on Transformer and reveal their advantages on different kinds of graph tasks.
Recent Advances in Reliable Deep Graph Learning: Adversarial Attack, Inherent Noise, and Distribution Shift
Feb 15, 2022


Deep graph learning (DGL) has achieved remarkable progress in both business and scientific areas ranging from finance and e-commerce to drug and advanced material discovery. Despite the progress, applying DGL to real-world applications faces a series of reliability threats including adversarial attacks, inherent noise, and distribution shift. This survey aims to provide a comprehensive review of recent advances for improving the reliability of DGL algorithms against the above threats. In contrast to prior related surveys which mainly focus on adversarial attacks and defense, our survey covers more reliability-related aspects of DGL, i.e., inherent noise and distribution shift. Additionally, we discuss the relationships among above aspects and highlight some important issues to be explored in future research.
Masked Transformer for Neighhourhood-aware Click-Through Rate Prediction
Jan 25, 2022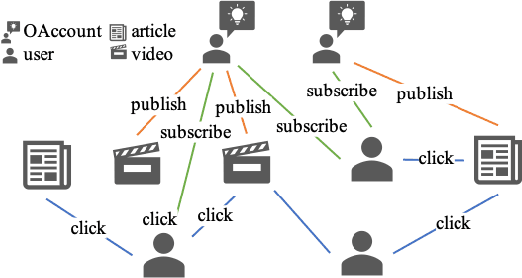
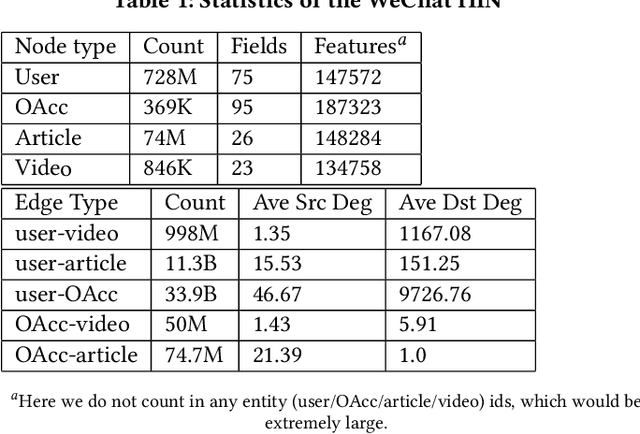
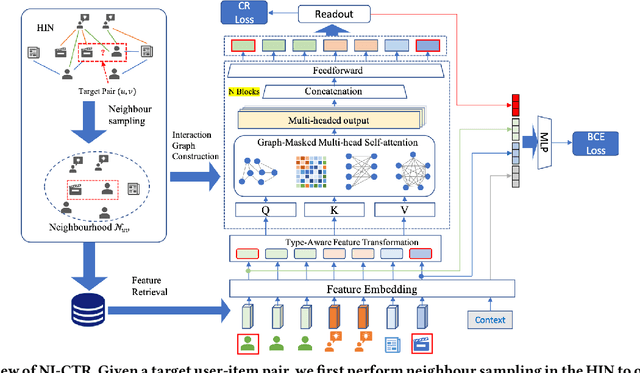
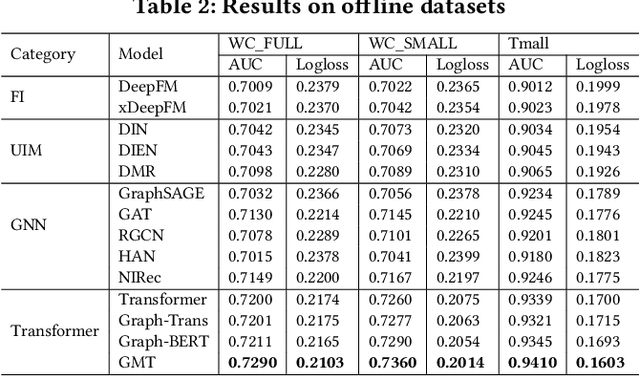
Click-Through Rate (CTR) prediction, is an essential component of online advertising. The mainstream techniques mostly focus on feature interaction or user interest modeling, which rely on users' directly interacted items. The performance of these methods are usally impeded by inactive behaviours and system's exposure, incurring that the features extracted do not contain enough information to represent all potential interests. For this sake, we propose Neighbor-Interaction based CTR prediction, which put this task into a Heterogeneous Information Network (HIN) setting, then involves local neighborhood of the target user-item pair in the HIN to predict their linkage. In order to enhance the representation of the local neighbourhood, we consider four types of topological interaction among the nodes, and propose a novel Graph-masked Transformer architecture to effectively incorporates both feature and topological information. We conduct comprehensive experiments on two real world datasets and the experimental results show that our proposed method outperforms state-of-the-art CTR models significantly.
DrugOOD: Out-of-Distribution (OOD) Dataset Curator and Benchmark for AI-aided Drug Discovery -- A Focus on Affinity Prediction Problems with Noise Annotations
Jan 24, 2022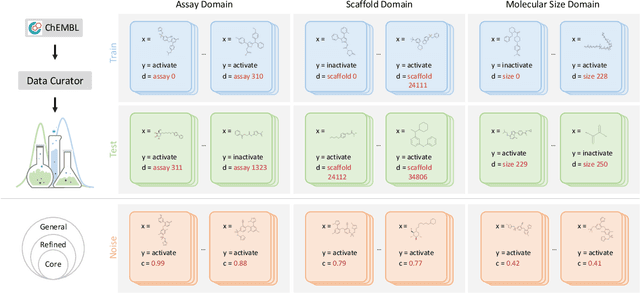

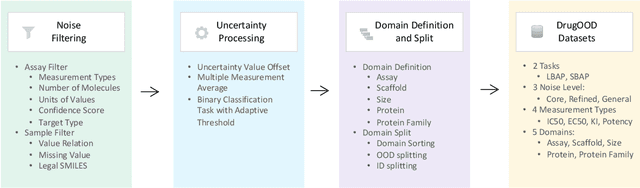
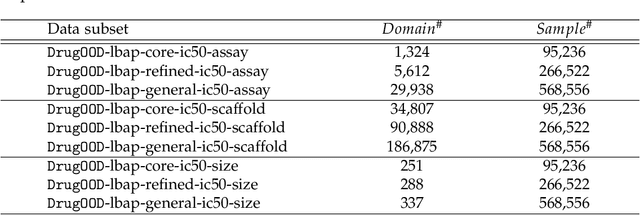
AI-aided drug discovery (AIDD) is gaining increasing popularity due to its promise of making the search for new pharmaceuticals quicker, cheaper and more efficient. In spite of its extensive use in many fields, such as ADMET prediction, virtual screening, protein folding and generative chemistry, little has been explored in terms of the out-of-distribution (OOD) learning problem with \emph{noise}, which is inevitable in real world AIDD applications. In this work, we present DrugOOD, a systematic OOD dataset curator and benchmark for AI-aided drug discovery, which comes with an open-source Python package that fully automates the data curation and OOD benchmarking processes. We focus on one of the most crucial problems in AIDD: drug target binding affinity prediction, which involves both macromolecule (protein target) and small-molecule (drug compound). In contrast to only providing fixed datasets, DrugOOD offers automated dataset curator with user-friendly customization scripts, rich domain annotations aligned with biochemistry knowledge, realistic noise annotations and rigorous benchmarking of state-of-the-art OOD algorithms. Since the molecular data is often modeled as irregular graphs using graph neural network (GNN) backbones, DrugOOD also serves as a valuable testbed for \emph{graph OOD learning} problems. Extensive empirical studies have shown a significant performance gap between in-distribution and out-of-distribution experiments, which highlights the need to develop better schemes that can allow for OOD generalization under noise for AIDD.
RetroComposer: Discovering Novel Reactions by Composing Templates for Retrosynthesis Prediction
Dec 20, 2021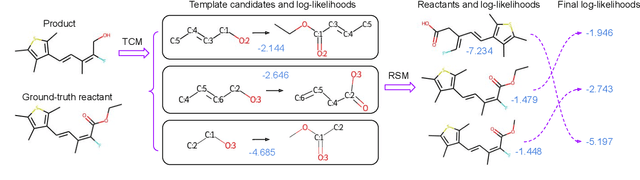
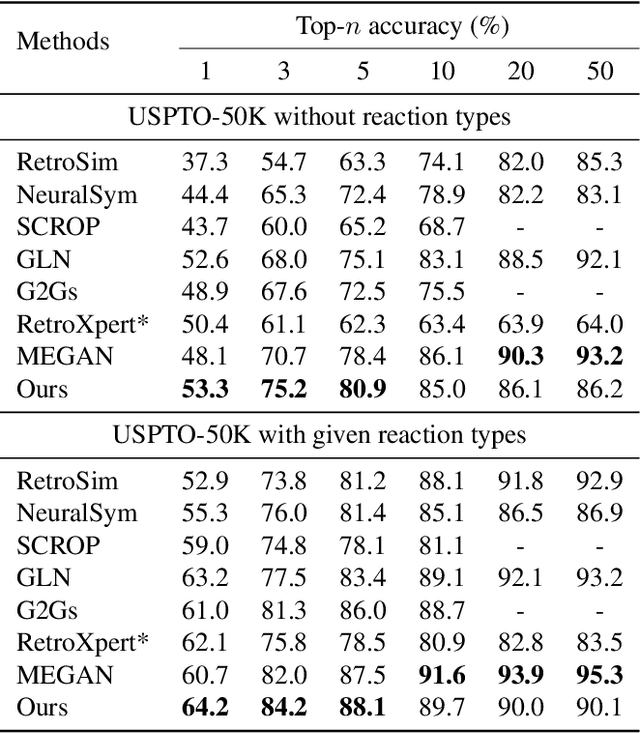
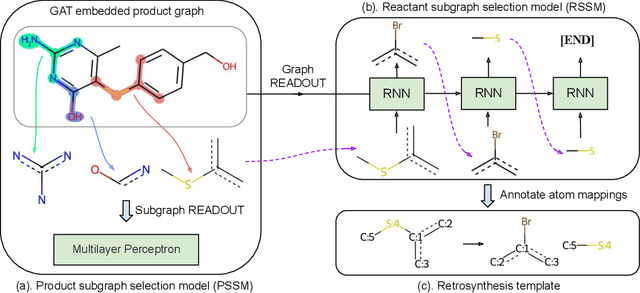
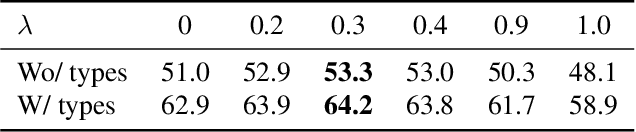
The main target of retrosynthesis is to recursively decompose desired molecules into available building blocks. Existing template-based retrosynthesis methods follow a template selection stereotype and suffer from the limited training templates, which prevents them from discovering novel reactions. To overcome the limitation, we propose an innovative retrosynthesis prediction framework that can compose novel templates beyond training templates. So far as we know, this is the first method that can find novel templates for retrosynthesis prediction. Besides, we propose an effective reactant candidates scoring model that can capture atom-level transformation information, and it helps our method outperform existing methods by a large margin. Experimental results show that our method can produce novel templates for 328 test reactions in the USPTO-50K dataset, including 21 test reactions that are not covered by the training templates.
Generalization Bounds for Stochastic Gradient Langevin Dynamics: A Unified View via Information Leakage Analysis
Dec 14, 2021

Recently, generalization bounds of the non-convex empirical risk minimization paradigm using Stochastic Gradient Langevin Dynamics (SGLD) have been extensively studied. Several theoretical frameworks have been presented to study this problem from different perspectives, such as information theory and stability. In this paper, we present a unified view from privacy leakage analysis to investigate the generalization bounds of SGLD, along with a theoretical framework for re-deriving previous results in a succinct manner. Aside from theoretical findings, we conduct various numerical studies to empirically assess the information leakage issue of SGLD. Additionally, our theoretical and empirical results provide explanations for prior works that study the membership privacy of SGLD.