 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRe: Adaptive Interaction-Evaluation Routing with Per-Step Interaction Budgets for Iterative Graph Solvers
May 27, 2026Diffusion-based neural solvers for combinatorial optimization repeatedly re-evaluate dense edge/factor interactions, making inference expensive in wall-clock time and often memory-bound at scale. Inspired by the computational methodologies of many-body physics, we introduce LoRe, a training-free, inference-time drop-in wrapper that enforces per-step interaction-evaluation budgeting: at each iteration, it evaluates only a fixed fraction of interactions by dynamically routing computation to high-conflict or high-uncertainty interactions, instead of using a fixed sparsification (e.g., static kNN graphs or static masks). Under fully inclusive end-to-end wall-clock accounting, LoRe substantially improves scalability on the Maximum Independent Set (MIS) problem, extending feasible inference more than $3\times$ beyond the baseline's out-of-memory limit, delivering a $\sim 8\times$ speedup and a $\sim 12\times$ peak-memory reduction, with solution quality preserved in this regime. Demonstrating cross-task generality on the large-scale Traveling Salesperson Problem (TSP) and zero-shot robustness to topology shifts, LoRe achieves a $\sim 15\times$ speedup at $n=1000$ with a $44\times$ memory reduction and competitive tour quality.
DiveUp: Learning Feature Upsampling from Diverse Vision Foundation Models
Mar 13, 2026Recently, feature upsampling has gained increasing attention owing to its effectiveness in enhancing vision foundation models (VFMs) for pixel-level understanding tasks. Existing methods typically rely on high-resolution features from the same foundation model to achieve upsampling via self-reconstruction. However, relying solely on intra-model features forces the upsampler to overfit to the source model's inherent location misalignment and high-norm artifacts. To address this fundamental limitation, we propose DiveUp, a novel framework that breaks away from single-model dependency by introducing multi-VFM relational guidance. Instead of naive feature fusion, DiveUp leverages diverse VFMs as a panel of experts, utilizing their structural consensus to regularize the upsampler's learning process, effectively preventing the propagation of inaccurate spatial structures from the source model. To reconcile the unaligned feature spaces across different VFMs, we propose a universal relational feature representation, formulated as a local center-of-mass (COM) field, that extracts intrinsic geometric structures, enabling seamless cross-model interaction. Furthermore, we introduce a spikiness-aware selection strategy that evaluates the spatial reliability of each VFM, effectively filtering out high-norm artifacts to aggregate guidance from only the most reliable expert at each local region. DiveUp is a unified, encoder-agnostic framework; a jointly-trained model can universally upsample features from diverse VFMs without requiring per-model retraining. Extensive experiments demonstrate that DiveUp achieves state-of-the-art performance across various downstream dense prediction tasks, validating the efficacy of multi-expert relational guidance. Our code and models are available at: https://github.com/Xiaoqiong-Liu/DiveUp
Towards Visual Query Segmentation in the Wild
Mar 09, 2026In this paper, we introduce visual query segmentation (VQS), a new paradigm of visual query localization (VQL) that aims to segment all pixel-level occurrences of an object of interest in an untrimmed video, given an external visual query. Compared to existing VQL locating only the last appearance of a target using bounding boxes, VQS enables more comprehensive (i.e., all object occurrences) and precise (i.e., pixel-level masks) localization, making it more practical for real-world scenarios. To foster research on this task, we present VQS-4K, a large-scale benchmark dedicated to VQS. Specifically, VQS-4K contains 4,111 videos with more than 1.3 million frames and covers a diverse set of 222 object categories. Each video is paired with a visual query defined by a frame outside the search video and its target mask, and annotated with spatial-temporal masklets corresponding to the queried target. To ensure high quality, all videos in VQS-4K are manually labeled with meticulous inspection and iterative refinement. To the best of our knowledge, VQS-4K is the first benchmark specifically designed for VQS. Furthermore, to stimulate future research, we present a simple yet effective method, named VQ-SAM, which extends SAM 2 by leveraging target-specific and background distractor cues from the video to progressively evolve the memory through a novel multi-stage framework with an adaptive memory generation (AMG) module for VQS, significantly improving the performance. In our extensive experiments on VQS-4K, VQ-SAM achieves promising results and surpasses all existing approaches, demonstrating its effectiveness. With the proposed VQS-4K and VQ-SAM, we expect to go beyond the current VQL paradigm and inspire more future research and practical applications on VQS. Our benchmark, code, and results will be made publicly available.
Towards Long-Form Spatio-Temporal Video Grounding
Feb 26, 2026In real scenarios, videos can span several minutes or even hours. However, existing research on spatio-temporal video grounding (STVG), given a textual query, mainly focuses on localizing targets in short videos of tens of seconds, typically less than one minute, which limits real-world applications. In this paper, we explore Long-Form STVG (LF-STVG), which aims to locate targets in long-term videos. Compared with short videos, long-term videos contain much longer temporal spans and more irrelevant information, making it difficult for existing STVG methods that process all frames at once. To address this challenge, we propose an AutoRegressive Transformer architecture for LF-STVG, termed ART-STVG. Unlike conventional STVG methods that require the entire video sequence to make predictions at once, ART-STVG treats the video as streaming input and processes frames sequentially, enabling efficient handling of long videos. To model spatio-temporal context, we design spatial and temporal memory banks and apply them to the decoders. Since memories from different moments are not always relevant to the current frame, we introduce simple yet effective memory selection strategies to provide more relevant information to the decoders, significantly improving performance. Furthermore, instead of parallel spatial and temporal localization, we propose a cascaded spatio-temporal design that connects the spatial decoder to the temporal decoder, allowing fine-grained spatial cues to assist complex temporal localization in long videos. Experiments on newly extended LF-STVG datasets show that ART-STVG significantly outperforms state-of-the-art methods, while achieving competitive performance on conventional short-form STVG.
Learning to Segment Liquids in Real-world Images
Jan 02, 2026Different types of liquids such as water, wine and medicine appear in all aspects of daily life. However, limited attention has been given to the task, hindering the ability of robots to avoid or interact with liquids safely. The segmentation of liquids is difficult because liquids come in diverse appearances and shapes; moreover, they can be both transparent or reflective, taking on arbitrary objects and scenes from the background or surroundings. To take on this challenge, we construct a large-scale dataset of liquids named LQDS consisting of 5000 real-world images annotated into 14 distinct classes, and design a novel liquid detection model named LQDM, which leverages cross-attention between a dedicated boundary branch and the main segmentation branch to enhance segmentation predictions. Extensive experiments demonstrate the effectiveness of LQDM on the test set of LQDS, outperforming state-of-the-art methods and establishing a strong baseline for the semantic segmentation of liquids.
OLC-WA: Drift Aware Tuning-Free Online Classification with Weighted Average
Dec 14, 2025
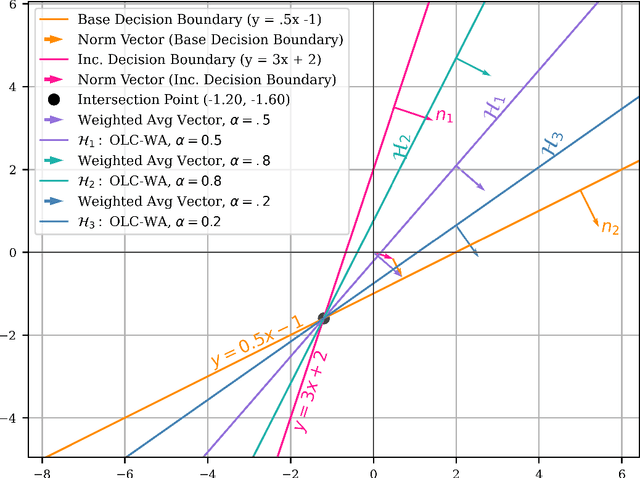

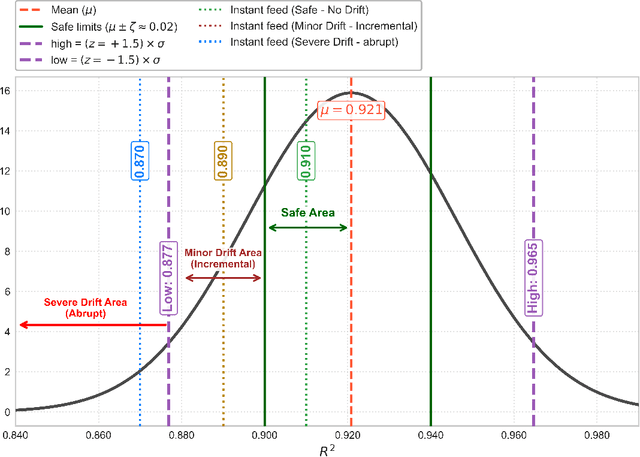
Real-world data sets often exhibit temporal dynamics characterized by evolving data distributions. Disregarding this phenomenon, commonly referred to as concept drift, can significantly diminish a model's predictive accuracy. Furthermore, the presence of hyperparameters in online models exacerbates this issue. These parameters are typically fixed and cannot be dynamically adjusted by the user in response to the evolving data distribution. This paper introduces Online Classification with Weighted Average (OLC-WA), an adaptive, hyperparameter-free online classification model equipped with an automated optimization mechanism. OLC-WA operates by blending incoming data streams with an existing base model. This blending is facilitated by an exponentially weighted moving average. Furthermore, an integrated optimization mechanism dynamically detects concept drift, quantifies its magnitude, and adjusts the model based on the observed data stream characteristics. This approach empowers the model to effectively adapt to evolving data distributions within streaming environments. Rigorous empirical evaluation across diverse benchmark datasets shows that OLC-WA achieves performance comparable to batch models in stationary environments, maintaining accuracy within 1-3%, and surpasses leading online baselines by 10-25% under drift, demonstrating its effectiveness in adapting to dynamic data streams.
Hybrid Quantum-Classical Neural Networks for Few-Shot Credit Risk Assessment
Sep 17, 2025Quantum Machine Learning (QML) offers a new paradigm for addressing complex financial problems intractable for classical methods. This work specifically tackles the challenge of few-shot credit risk assessment, a critical issue in inclusive finance where data scarcity and imbalance limit the effectiveness of conventional models. To address this, we design and implement a novel hybrid quantum-classical workflow. The methodology first employs an ensemble of classical machine learning models (Logistic Regression, Random Forest, XGBoost) for intelligent feature engineering and dimensionality reduction. Subsequently, a Quantum Neural Network (QNN), trained via the parameter-shift rule, serves as the core classifier. This framework was evaluated through numerical simulations and deployed on the Quafu Quantum Cloud Platform's ScQ-P21 superconducting processor. On a real-world credit dataset of 279 samples, our QNN achieved a robust average AUC of 0.852 +/- 0.027 in simulations and yielded an impressive AUC of 0.88 in the hardware experiment. This performance surpasses a suite of classical benchmarks, with a particularly strong result on the recall metric. This study provides a pragmatic blueprint for applying quantum computing to data-constrained financial scenarios in the NISQ era and offers valuable empirical evidence supporting its potential in high-stakes applications like inclusive finance.
IRDFusion: Iterative Relation-Map Difference guided Feature Fusion for Multispectral Object Detection
Sep 11, 2025Current multispectral object detection methods often retain extraneous background or noise during feature fusion, limiting perceptual performance.To address this, we propose an innovative feature fusion framework based on cross-modal feature contrastive and screening strategy, diverging from conventional approaches. The proposed method adaptively enhances salient structures by fusing object-aware complementary cross-modal features while suppressing shared background interference.Our solution centers on two novel, specially designed modules: the Mutual Feature Refinement Module (MFRM) and the Differential Feature Feedback Module (DFFM). The MFRM enhances intra- and inter-modal feature representations by modeling their relationships, thereby improving cross-modal alignment and discriminative power.Inspired by feedback differential amplifiers, the DFFM dynamically computes inter-modal differential features as guidance signals and feeds them back to the MFRM, enabling adaptive fusion of complementary information while suppressing common-mode noise across modalities. To enable robust feature learning, the MFRM and DFFM are integrated into a unified framework, which is formally formulated as an Iterative Relation-Map Differential Guided Feature Fusion mechanism, termed IRDFusion. IRDFusion enables high-quality cross-modal fusion by progressively amplifying salient relational signals through iterative feedback, while suppressing feature noise, leading to significant performance gains.In extensive experiments on FLIR, LLVIP and M$^3$FD datasets, IRDFusion achieves state-of-the-art performance and consistently outperforms existing methods across diverse challenging scenarios, demonstrating its robustness and effectiveness. Code will be available at https://github.com/61s61min/IRDFusion.git.
G3CN: Gaussian Topology Refinement Gated Graph Convolutional Network for Skeleton-Based Action Recognition
Sep 09, 2025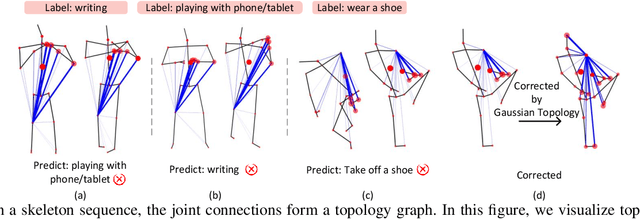
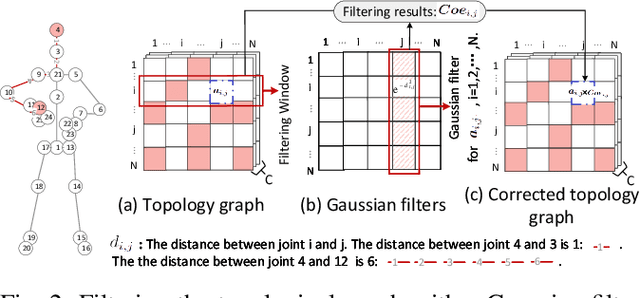
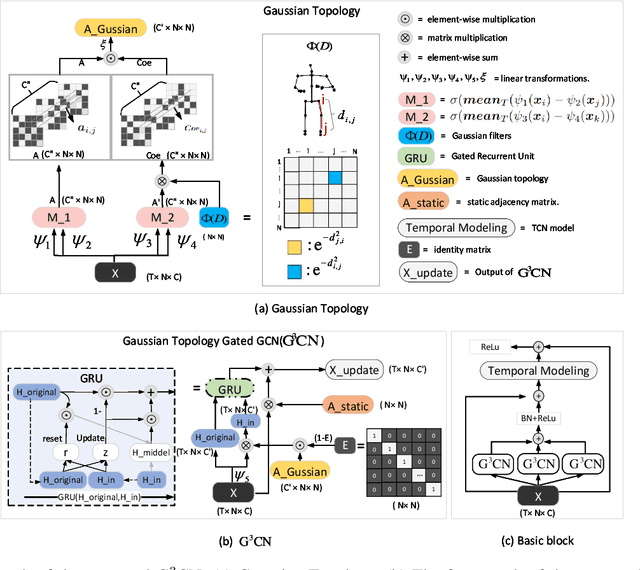
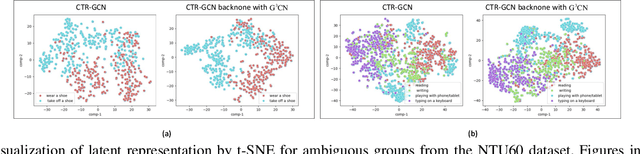
Graph Convolutional Networks (GCNs) have proven to be highly effective for skeleton-based action recognition, primarily due to their ability to leverage graph topology for feature aggregation, a key factor in extracting meaningful representations. However, despite their success, GCNs often struggle to effectively distinguish between ambiguous actions, revealing limitations in the representation of learned topological and spatial features. To address this challenge, we propose a novel approach, Gaussian Topology Refinement Gated Graph Convolution (G$^{3}$CN), to address the challenge of distinguishing ambiguous actions in skeleton-based action recognition. G$^{3}$CN incorporates a Gaussian filter to refine the skeleton topology graph, improving the representation of ambiguous actions. Additionally, Gated Recurrent Units (GRUs) are integrated into the GCN framework to enhance information propagation between skeleton points. Our method shows strong generalization across various GCN backbones. Extensive experiments on NTU RGB+D, NTU RGB+D 120, and NW-UCLA benchmarks demonstrate that G$^{3}$CN effectively improves action recognition, particularly for ambiguous samples.
CGTrack: Cascade Gating Network with Hierarchical Feature Aggregation for UAV Tracking
May 09, 2025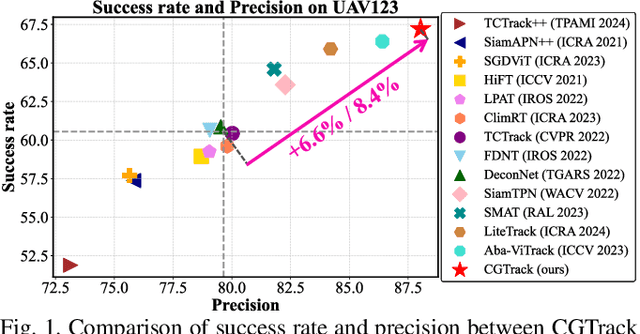
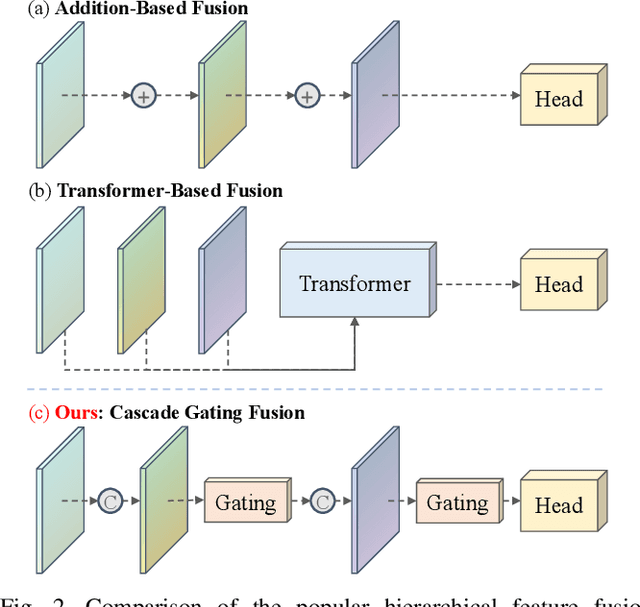
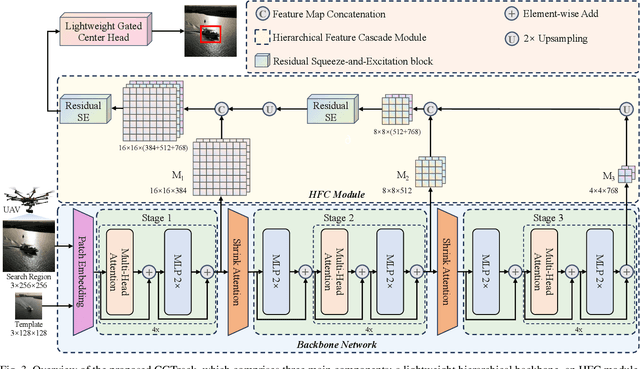
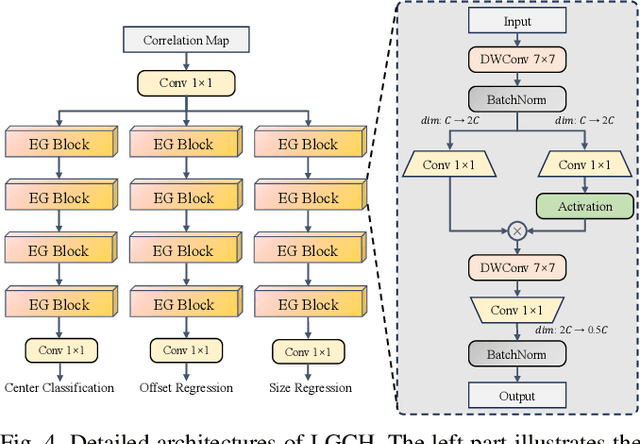
Recent advancements in visual object tracking have markedly improved the capabilities of unmanned aerial vehicle (UAV) tracking, which is a critical component in real-world robotics applications. While the integration of hierarchical lightweight networks has become a prevalent strategy for enhancing efficiency in UAV tracking, it often results in a significant drop in network capacity, which further exacerbates challenges in UAV scenarios, such as frequent occlusions and extreme changes in viewing angles. To address these issues, we introduce a novel family of UAV trackers, termed CGTrack, which combines explicit and implicit techniques to expand network capacity within a coarse-to-fine framework. Specifically, we first introduce a Hierarchical Feature Cascade (HFC) module that leverages the spirit of feature reuse to increase network capacity by integrating the deep semantic cues with the rich spatial information, incurring minimal computational costs while enhancing feature representation. Based on this, we design a novel Lightweight Gated Center Head (LGCH) that utilizes gating mechanisms to decouple target-oriented coordinates from previously expanded features, which contain dense local discriminative information. Extensive experiments on three challenging UAV tracking benchmarks demonstrate that CGTrack achieves state-of-the-art performance while running fast. Code will be available at https://github.com/Nightwatch-Fox11/CGTrack.