 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
CGTrack: Cascade Gating Network with Hierarchical Feature Aggregation for UAV Tracking
May 09, 2025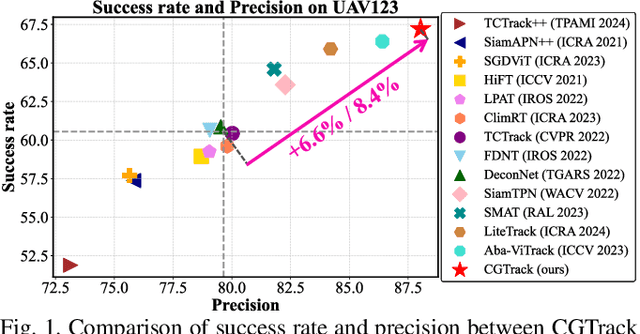
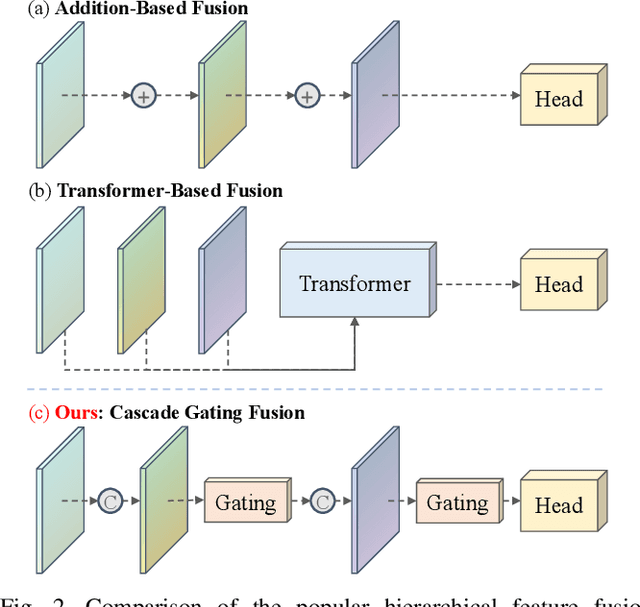
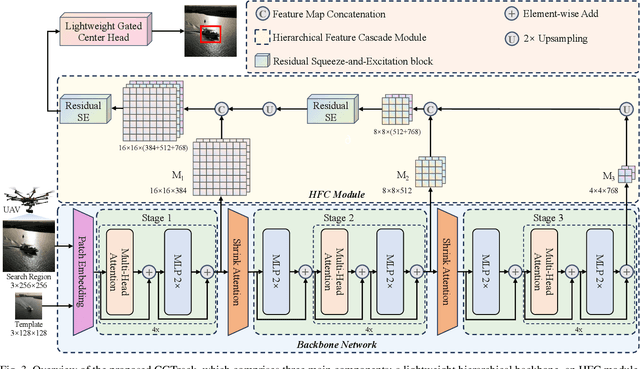
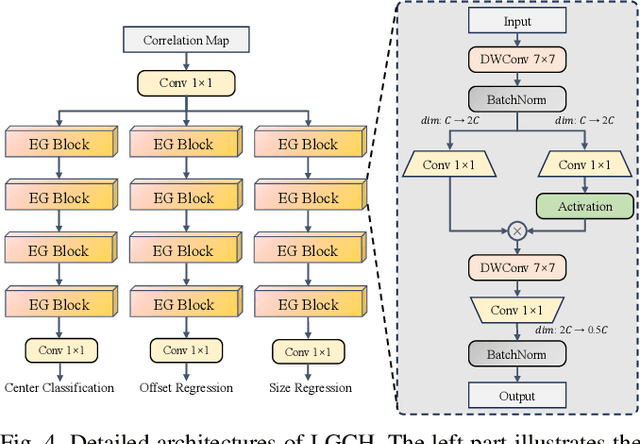
Recent advancements in visual object tracking have markedly improved the capabilities of unmanned aerial vehicle (UAV) tracking, which is a critical component in real-world robotics applications. While the integration of hierarchical lightweight networks has become a prevalent strategy for enhancing efficiency in UAV tracking, it often results in a significant drop in network capacity, which further exacerbates challenges in UAV scenarios, such as frequent occlusions and extreme changes in viewing angles. To address these issues, we introduce a novel family of UAV trackers, termed CGTrack, which combines explicit and implicit techniques to expand network capacity within a coarse-to-fine framework. Specifically, we first introduce a Hierarchical Feature Cascade (HFC) module that leverages the spirit of feature reuse to increase network capacity by integrating the deep semantic cues with the rich spatial information, incurring minimal computational costs while enhancing feature representation. Based on this, we design a novel Lightweight Gated Center Head (LGCH) that utilizes gating mechanisms to decouple target-oriented coordinates from previously expanded features, which contain dense local discriminative information. Extensive experiments on three challenging UAV tracking benchmarks demonstrate that CGTrack achieves state-of-the-art performance while running fast. Code will be available at https://github.com/Nightwatch-Fox11/CGTrack.
DebiasDiff: Debiasing Text-to-image Diffusion Models with Self-discovering Latent Attribute Directions
Dec 25, 2024While Diffusion Models (DM) exhibit remarkable performance across various image generative tasks, they nonetheless reflect the inherent bias presented in the training set. As DMs are now widely used in real-world applications, these biases could perpetuate a distorted worldview and hinder opportunities for minority groups. Existing methods on debiasing DMs usually requires model re-training with a human-crafted reference dataset or additional classifiers, which suffer from two major limitations: (1) collecting reference datasets causes expensive annotation cost; (2) the debiasing performance is heavily constrained by the quality of the reference dataset or the additional classifier. To address the above limitations, we propose DebiasDiff, a plug-and-play method that learns attribute latent directions in a self-discovering manner, thus eliminating the reliance on such reference dataset. Specifically, DebiasDiff consists of two parts: a set of attribute adapters and a distribution indicator. Each adapter in the set aims to learn an attribute latent direction, and is optimized via noise composition through a self-discovering process. Then, the distribution indicator is multiplied by the set of adapters to guide the generation process towards the prescribed distribution. Our method enables debiasing multiple attributes in DMs simultaneously, while remaining lightweight and easily integrable with other DMs, eliminating the need for re-training. Extensive experiments on debiasing gender, racial, and their intersectional biases show that our method outperforms previous SOTA by a large margin.
BIFRÖST: 3D-Aware Image compositing with Language Instructions
Oct 24, 2024This paper introduces Bifr\"ost, a novel 3D-aware framework that is built upon diffusion models to perform instruction-based image composition. Previous methods concentrate on image compositing at the 2D level, which fall short in handling complex spatial relationships ($\textit{e.g.}$, occlusion). Bifr\"ost addresses these issues by training MLLM as a 2.5D location predictor and integrating depth maps as an extra condition during the generation process to bridge the gap between 2D and 3D, which enhances spatial comprehension and supports sophisticated spatial interactions. Our method begins by fine-tuning MLLM with a custom counterfactual dataset to predict 2.5D object locations in complex backgrounds from language instructions. Then, the image-compositing model is uniquely designed to process multiple types of input features, enabling it to perform high-fidelity image compositions that consider occlusion, depth blur, and image harmonization. Extensive qualitative and quantitative evaluations demonstrate that Bifr\"ost significantly outperforms existing methods, providing a robust solution for generating realistically composed images in scenarios demanding intricate spatial understanding. This work not only pushes the boundaries of generative image compositing but also reduces reliance on expensive annotated datasets by effectively utilizing existing resources in innovative ways.
VastTrack: Vast Category Visual Object Tracking
Mar 06, 2024In this paper, we introduce a novel benchmark, dubbed VastTrack, towards facilitating the development of more general visual tracking via encompassing abundant classes and videos. VastTrack possesses several attractive properties: (1) Vast Object Category. In particular, it covers target objects from 2,115 classes, largely surpassing object categories of existing popular benchmarks (e.g., GOT-10k with 563 classes and LaSOT with 70 categories). With such vast object classes, we expect to learn more general object tracking. (2) Larger scale. Compared with current benchmarks, VastTrack offers 50,610 sequences with 4.2 million frames, which makes it to date the largest benchmark regarding the number of videos, and thus could benefit training even more powerful visual trackers in the deep learning era. (3) Rich Annotation. Besides conventional bounding box annotations, VastTrack also provides linguistic descriptions for the videos. The rich annotations of VastTrack enables development of both the vision-only and the vision-language tracking. To ensure precise annotation, all videos are manually labeled with multiple rounds of careful inspection and refinement. To understand performance of existing trackers and to provide baselines for future comparison, we extensively assess 25 representative trackers. The results, not surprisingly, show significant drops compared to those on current datasets due to lack of abundant categories and videos from diverse scenarios for training, and more efforts are required to improve general tracking. Our VastTrack and all the evaluation results will be made publicly available https://github.com/HengLan/VastTrack.
Deep Residual Networks with a Fully Connected Recon-struction Layer for Single Image Super-Resolution
May 24, 2018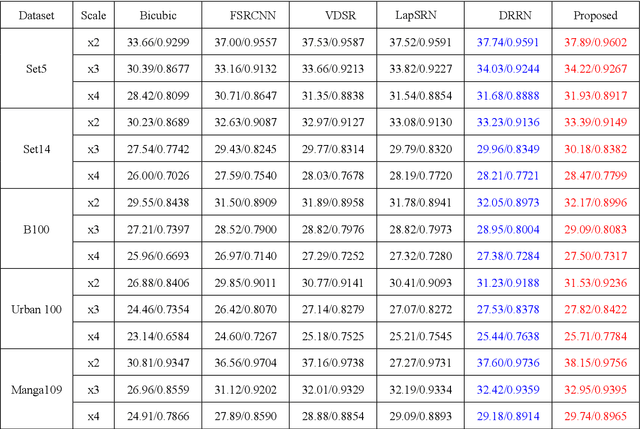
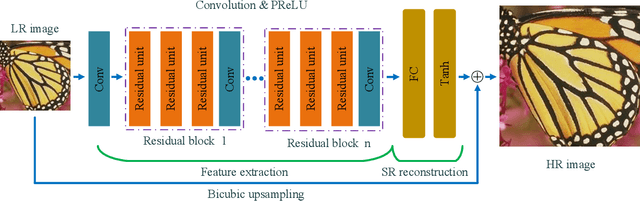
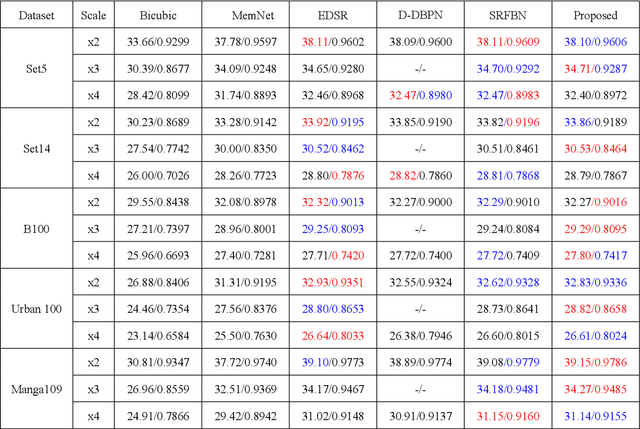
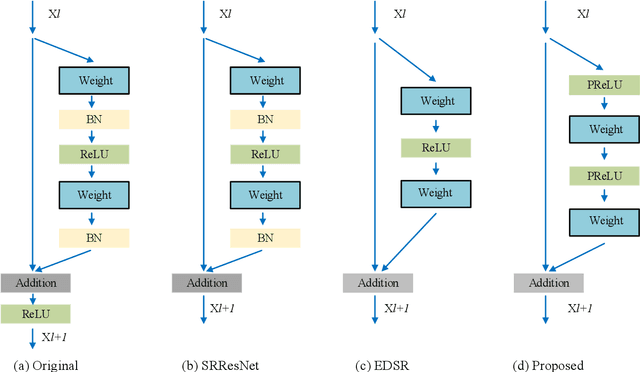
Recently, deep neural networks have achieved impressive performance in terms of both reconstruction accuracy and efficiency for single image super-resolution (SISR). However, the network model of these methods is a fully convolutional neural network, which is limit to exploit contextual information over the global region of the input image. In this paper, we discuss a new SR architecture where features are extracted in the low-resolution (LR) space, and then we use a fully connected layer which learns an array of upsampling weights to reconstruct the desired high-resolution (HR) image from the final LR features. By doing so, we effectively exploit global context information over the input image region, whilst maintaining the low computational complexity for the overall SR operation. In addition, we introduce an edge difference constraint into our loss function to pre-serve edges and texture structures. Extensive experiments validate that our meth-od outperforms the existing state-of-the-art methods
Deep Inception-Residual Laplacian Pyramid Networks for Accurate Single Image Super-Resolution
Nov 15, 2017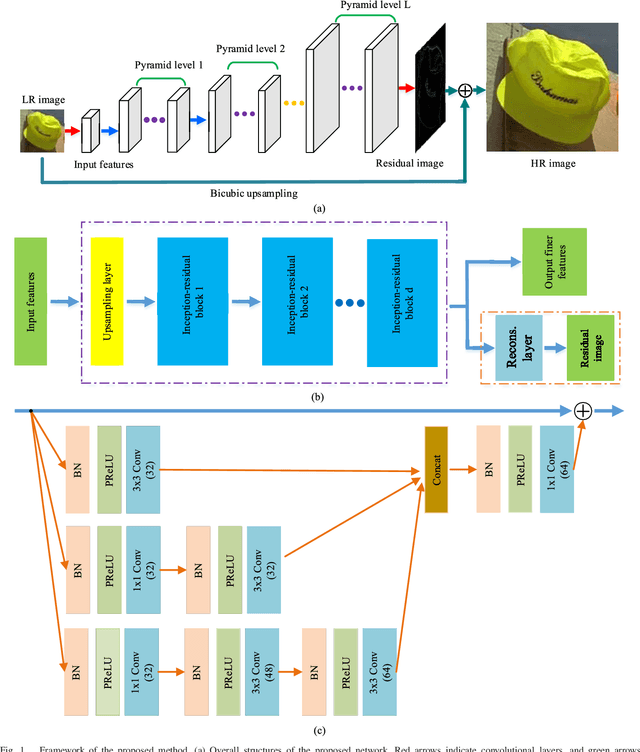

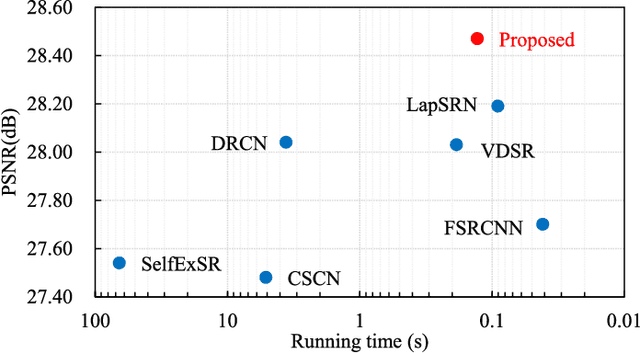
With exploiting contextual information over large image regions in an efficient way, the deep convolutional neural network has shown an impressive performance for single image super-resolution (SR). In this paper, we propose a deep convolutional network by cascading the well-designed inception-residual blocks within the deep Laplacian pyramid framework to progressively restore the missing high-frequency details of high-resolution (HR) images. By optimizing our network structure, the trainable depth of the proposed network gains a significant improvement, which in turn improves super-resolving accuracy. With our network depth increasing, however, the saturation and degradation of training accuracy continues to be a critical problem. As regard to this, we propose an effective two-stage training strategy, in which we firstly use images downsampled from the ground-truth HR images as the optimal objective to train the inception-residual blocks in each pyramid level with an extremely high learning rate enabled by gradient clipping, and then the ground-truth HR images are used to fine-tune all the pre-trained inception-residual blocks for obtaining the final SR model. Furthermore, we present a new loss function operating in both image space and local rank space to optimize our network for exploiting the contextual information among different output components. Extensive experiments on benchmark datasets validate that the proposed method outperforms existing state-of-the-art SR methods in terms of the objective evaluation as well as the visual quality.