 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrucTexT: Structured Text Understanding with Multi-Modal Transformers
Aug 10, 2021
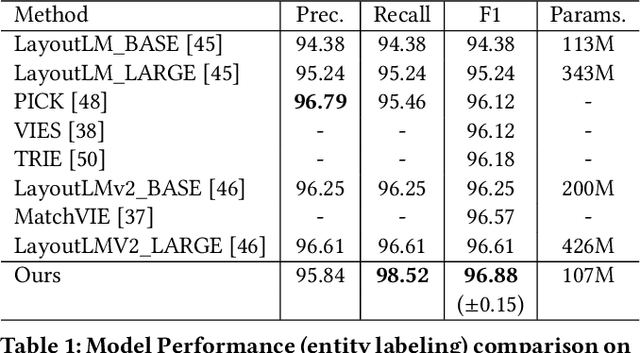
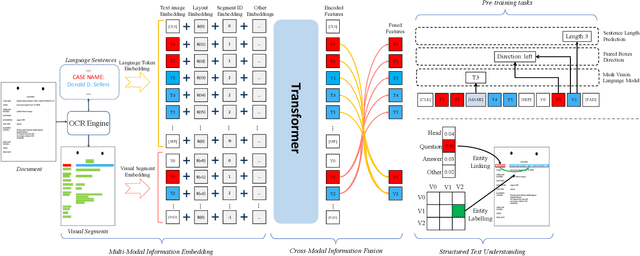
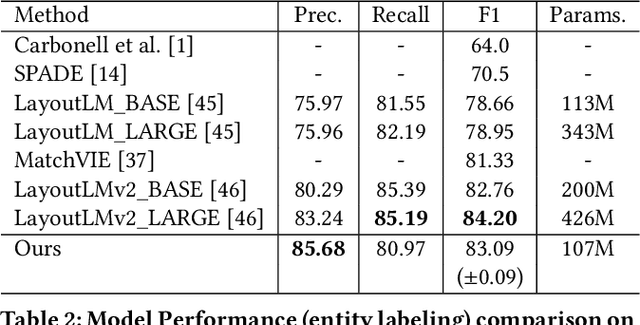
Structured text understanding on Visually Rich Documents (VRDs) is a crucial part of Document Intelligence. Due to the complexity of content and layout in VRDs, structured text understanding has been a challenging task. Most existing studies decoupled this problem into two sub-tasks: entity labeling and entity linking, which require an entire understanding of the context of documents at both token and segment levels. However, little work has been concerned with the solutions that efficiently extract the structured data from different levels. This paper proposes a unified framework named StrucTexT, which is flexible and effective for handling both sub-tasks. Specifically, based on the transformer, we introduce a segment-token aligned encoder to deal with the entity labeling and entity linking tasks at different levels of granularity. Moreover, we design a novel pre-training strategy with three self-supervised tasks to learn a richer representation. StrucTexT uses the existing Masked Visual Language Modeling task and the new Sentence Length Prediction and Paired Boxes Direction tasks to incorporate the multi-modal information across text, image, and layout. We evaluate our method for structured text understanding at segment-level and token-level and show it outperforms the state-of-the-art counterparts with significantly superior performance on the FUNSD, SROIE, and EPHOIE datasets.
Dynamic Class Queue for Large Scale Face Recognition In the Wild
May 24, 2021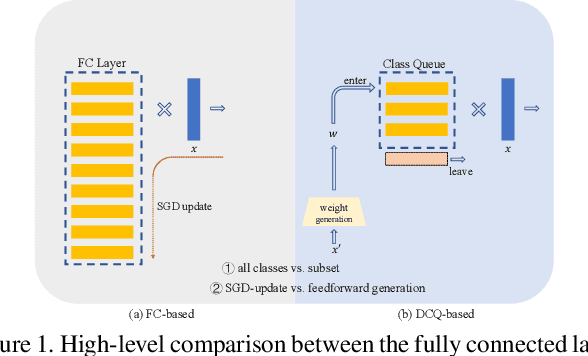

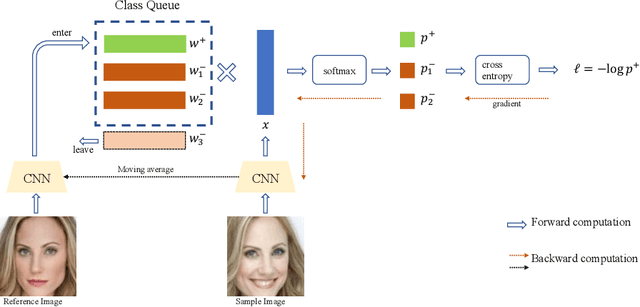
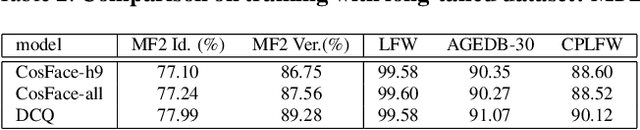
Learning discriminative representation using large-scale face datasets in the wild is crucial for real-world applications, yet it remains challenging. The difficulties lie in many aspects and this work focus on computing resource constraint and long-tailed class distribution. Recently, classification-based representation learning with deep neural networks and well-designed losses have demonstrated good recognition performance. However, the computing and memory cost linearly scales up to the number of identities (classes) in the training set, and the learning process suffers from unbalanced classes. In this work, we propose a dynamic class queue (DCQ) to tackle these two problems. Specifically, for each iteration during training, a subset of classes for recognition are dynamically selected and their class weights are dynamically generated on-the-fly which are stored in a queue. Since only a subset of classes is selected for each iteration, the computing requirement is reduced. By using a single server without model parallel, we empirically verify in large-scale datasets that 10% of classes are sufficient to achieve similar performance as using all classes. Moreover, the class weights are dynamically generated in a few-shot manner and therefore suitable for tail classes with only a few instances. We show clear improvement over a strong baseline in the largest public dataset Megaface Challenge2 (MF2) which has 672K identities and over 88% of them have less than 10 instances. Code is available at https://github.com/bilylee/DCQ
PGNet: Real-time Arbitrarily-Shaped Text Spotting with Point Gathering Network
Apr 12, 2021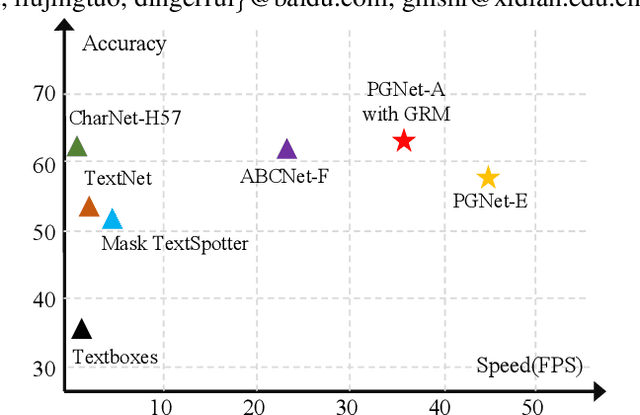
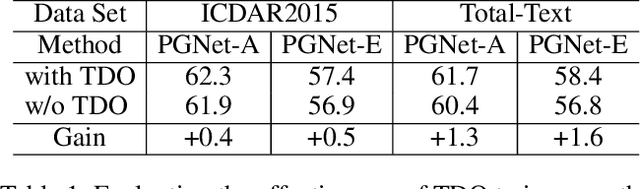
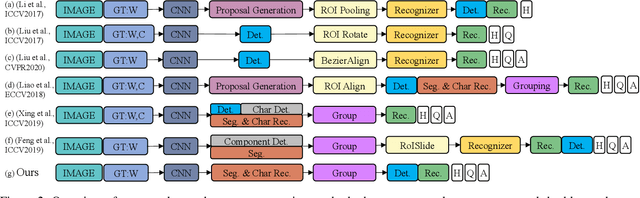
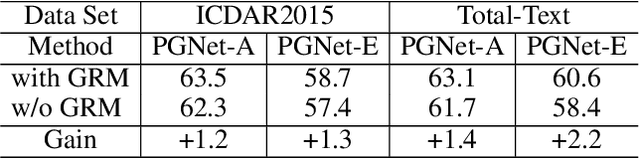
The reading of arbitrarily-shaped text has received increasing research attention. However, existing text spotters are mostly built on two-stage frameworks or character-based methods, which suffer from either Non-Maximum Suppression (NMS), Region-of-Interest (RoI) operations, or character-level annotations. In this paper, to address the above problems, we propose a novel fully convolutional Point Gathering Network (PGNet) for reading arbitrarily-shaped text in real-time. The PGNet is a single-shot text spotter, where the pixel-level character classification map is learned with proposed PG-CTC loss avoiding the usage of character-level annotations. With a PG-CTC decoder, we gather high-level character classification vectors from two-dimensional space and decode them into text symbols without NMS and RoI operations involved, which guarantees high efficiency. Additionally, reasoning the relations between each character and its neighbors, a graph refinement module (GRM) is proposed to optimize the coarse recognition and improve the end-to-end performance. Experiments prove that the proposed method achieves competitive accuracy, meanwhile significantly improving the running speed. In particular, in Total-Text, it runs at 46.7 FPS, surpassing the previous spotters with a large margin.
FaceController: Controllable Attribute Editing for Face in the Wild
Feb 23, 2021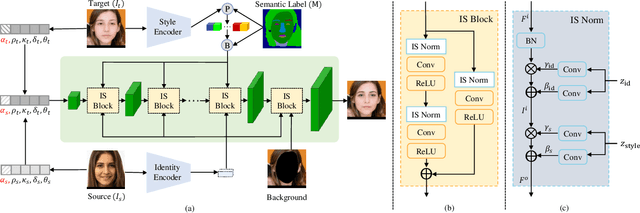
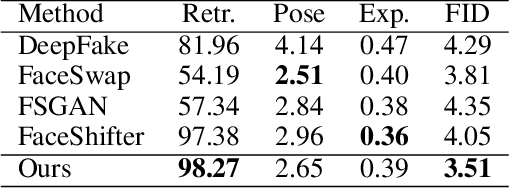
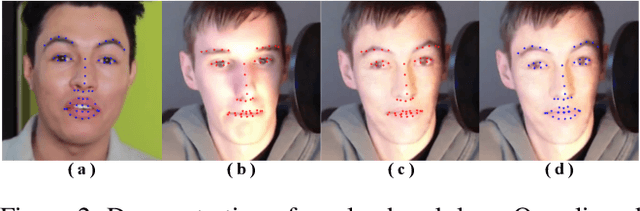
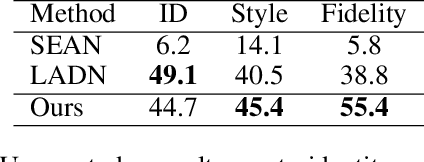
Face attribute editing aims to generate faces with one or multiple desired face attributes manipulated while other details are preserved. Unlike prior works such as GAN inversion, which has an expensive reverse mapping process, we propose a simple feed-forward network to generate high-fidelity manipulated faces. By simply employing some existing and easy-obtainable prior information, our method can control, transfer, and edit diverse attributes of faces in the wild. The proposed method can consequently be applied to various applications such as face swapping, face relighting, and makeup transfer. In our method, we decouple identity, expression, pose, and illumination using 3D priors; separate texture and colors by using region-wise style codes. All the information is embedded into adversarial learning by our identity-style normalization module. Disentanglement losses are proposed to enhance the generator to extract information independently from each attribute. Comprehensive quantitative and qualitative evaluations have been conducted. In a single framework, our method achieves the best or competitive scores on a variety of face applications.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020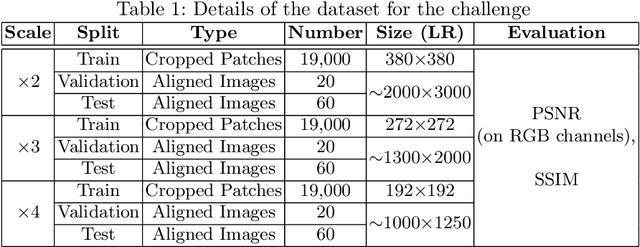
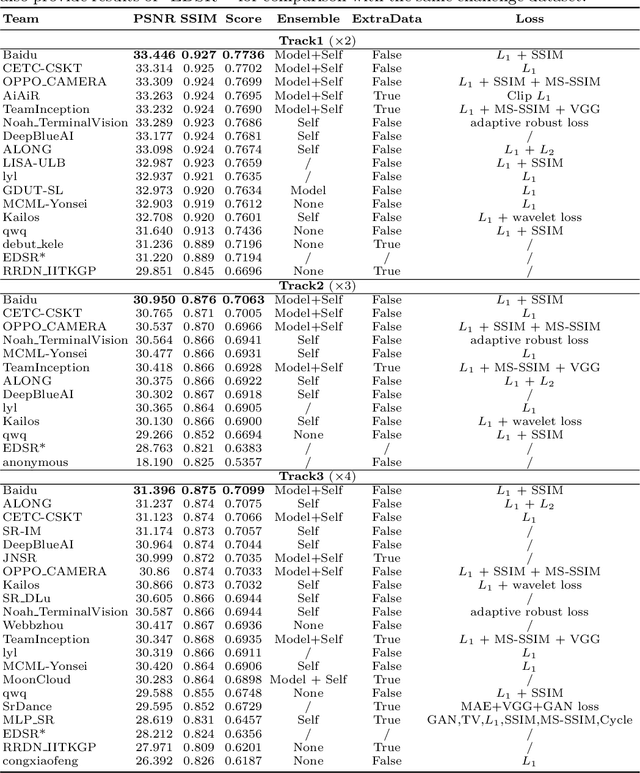
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.
Real Image Super Resolution Via Heterogeneous Model using GP-NAS
Sep 02, 2020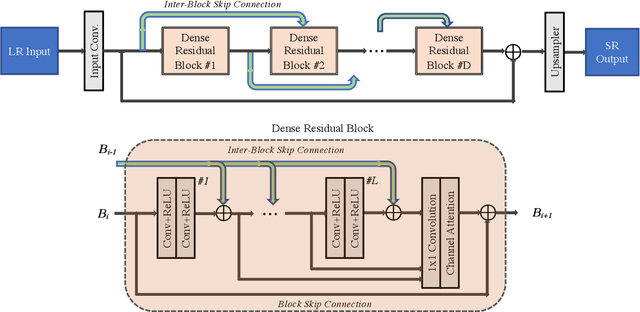
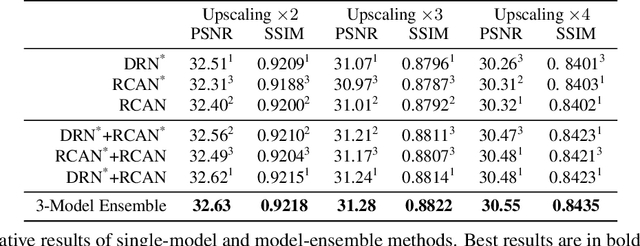
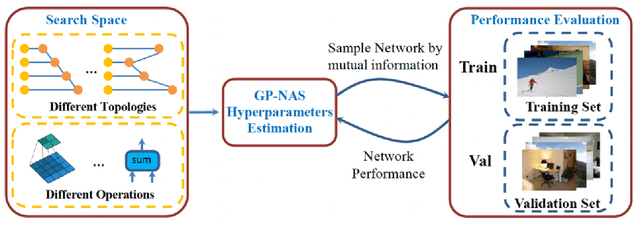
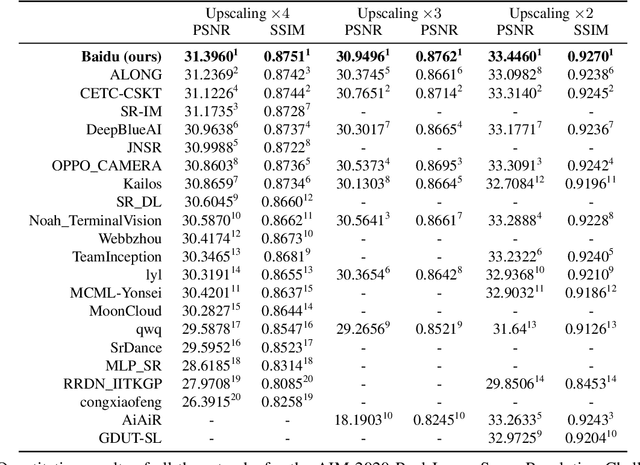
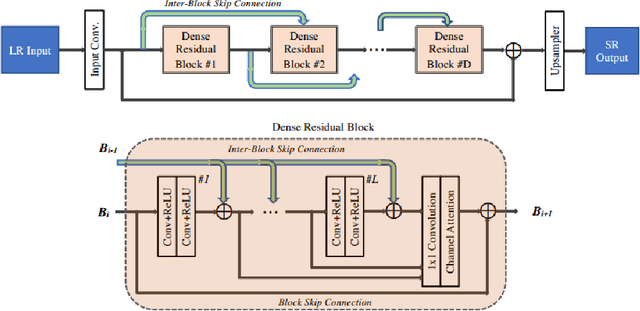
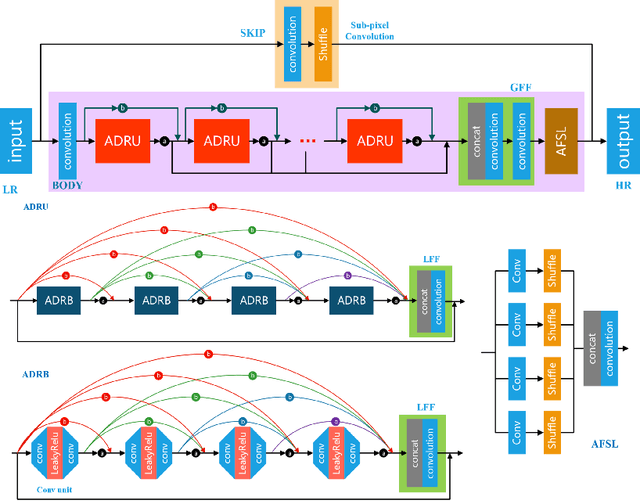
With advancement in deep neural network (DNN), recent state-of-the-art (SOTA) image superresolution (SR) methods have achieved impressive performance using deep residual network with dense skip connections. While these models perform well on benchmark dataset where low-resolution (LR) images are constructed from high-resolution (HR) references with known blur kernel, real image SR is more challenging when both images in the LR-HR pair are collected from real cameras. Based on existing dense residual networks, a Gaussian process based neural architecture search (GP-NAS) scheme is utilized to find candidate network architectures using a large search space by varying the number of dense residual blocks, the block size and the number of features. A suite of heterogeneous models with diverse network structure and hyperparameter are selected for model-ensemble to achieve outstanding performance in real image SR. The proposed method won the first place in all three tracks of the AIM 2020 Real Image Super-Resolution Challenge.
Learning Global Structure Consistency for Robust Object Tracking
Aug 26, 2020
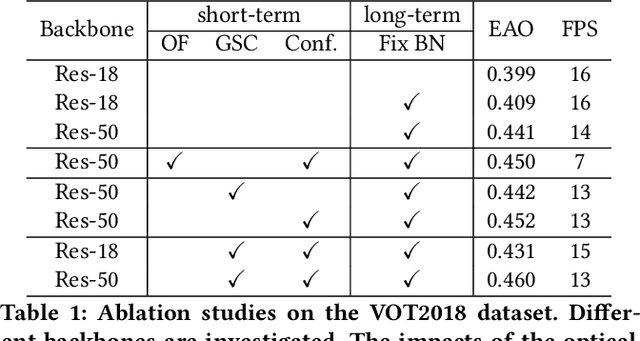
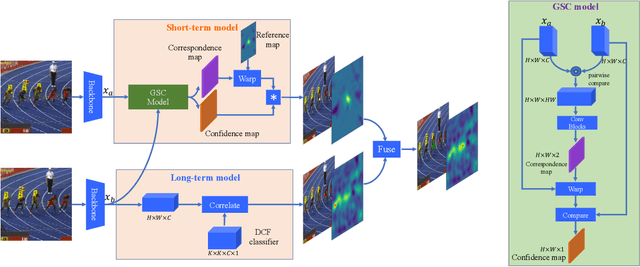
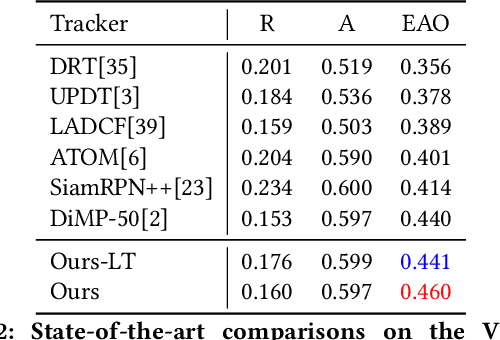
Fast appearance variations and the distractions of similar objects are two of the most challenging problems in visual object tracking. Unlike many existing trackers that focus on modeling only the target, in this work, we consider the \emph{transient variations of the whole scene}. The key insight is that the object correspondence and spatial layout of the whole scene are consistent (i.e., global structure consistency) in consecutive frames which helps to disambiguate the target from distractors. Moreover, modeling transient variations enables to localize the target under fast variations. Specifically, we propose an effective and efficient short-term model that learns to exploit the global structure consistency in a short time and thus can handle fast variations and distractors. Since short-term modeling falls short of handling occlusion and out of the views, we adopt the long-short term paradigm and use a long-term model that corrects the short-term model when it drifts away from the target or the target is not present. These two components are carefully combined to achieve the balance of stability and plasticity during tracking. We empirically verify that the proposed tracker can tackle the two challenging scenarios and validate it on large scale benchmarks. Remarkably, our tracker improves state-of-the-art-performance on VOT2018 from 0.440 to 0.460, GOT-10k from 0.611 to 0.640, and NFS from 0.619 to 0.629.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020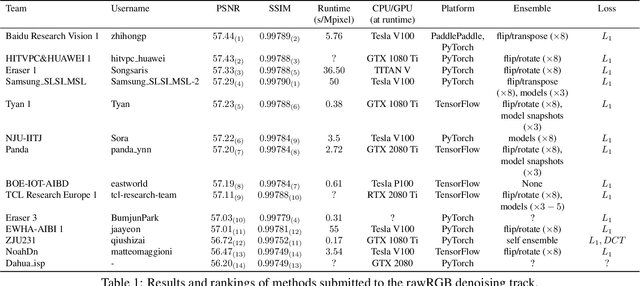
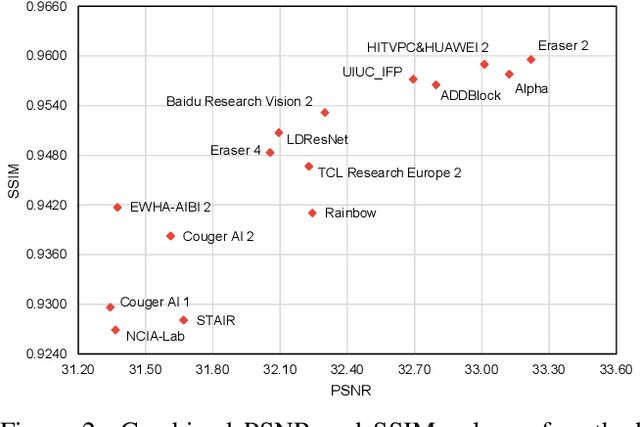
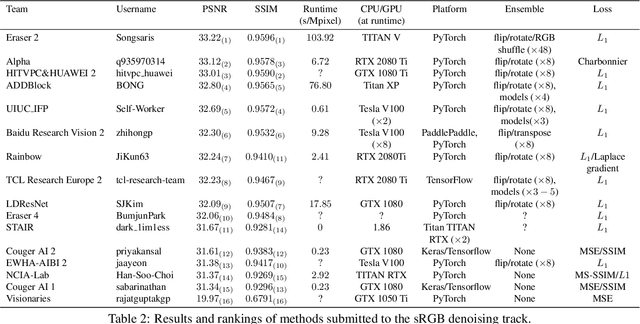
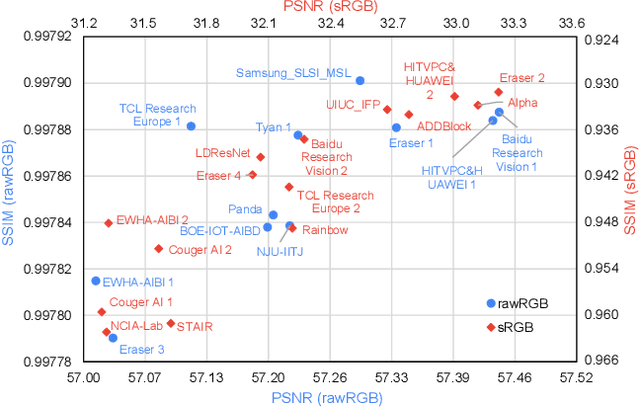
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
Learning Generalized Spoof Cues for Face Anti-spoofing
May 08, 2020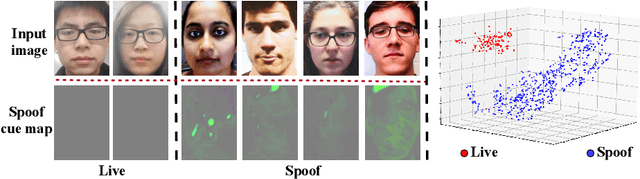
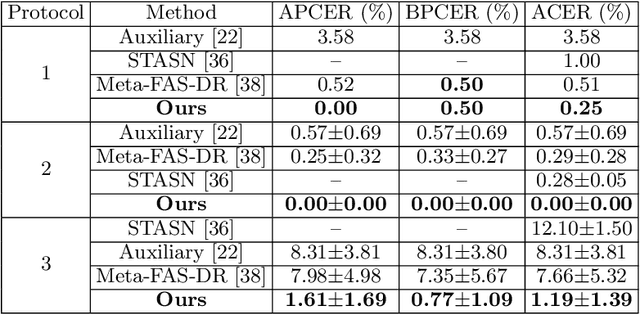
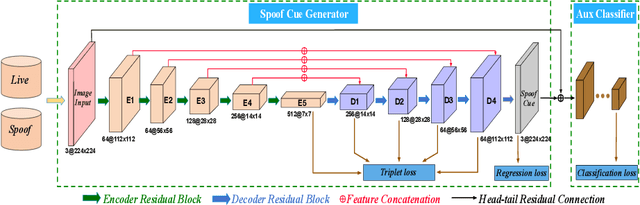
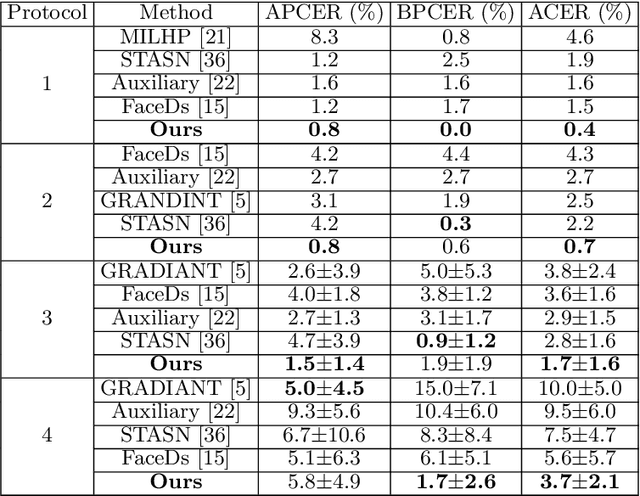
Many existing face anti-spoofing (FAS) methods focus on modeling the decision boundaries for some predefined spoof types. However, the diversity of the spoof samples including the unknown ones hinders the effective decision boundary modeling and leads to weak generalization capability. In this paper, we reformulate FAS in an anomaly detection perspective and propose a residual-learning framework to learn the discriminative live-spoof differences which are defined as the spoof cues. The proposed framework consists of a spoof cue generator and an auxiliary classifier. The generator minimizes the spoof cues of live samples while imposes no explicit constraint on those of spoof samples to generalize well to unseen attacks. In this way, anomaly detection is implicitly used to guide spoof cue generation, leading to discriminative feature learning. The auxiliary classifier serves as a spoof cue amplifier and makes the spoof cues more discriminative. We conduct extensive experiments and the experimental results show the proposed method consistently outperforms the state-of-the-art methods. The code will be publicly available at https://github.com/vis-var/lgsc-for-fas.
Towards Accurate Scene Text Recognition with Semantic Reasoning Networks
Mar 27, 2020
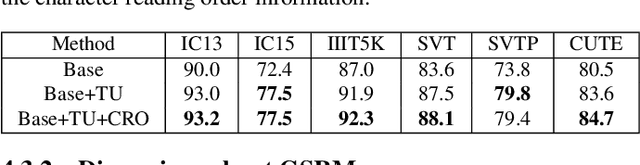
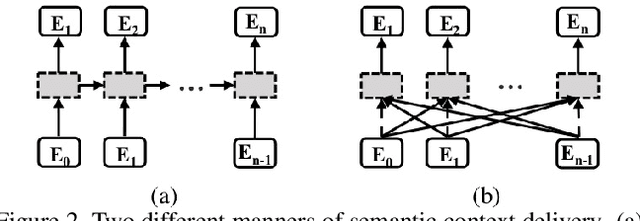
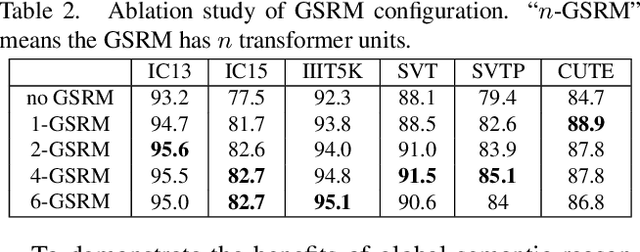
Scene text image contains two levels of contents: visual texture and semantic information. Although the previous scene text recognition methods have made great progress over the past few years, the research on mining semantic information to assist text recognition attracts less attention, only RNN-like structures are explored to implicitly model semantic information. However, we observe that RNN based methods have some obvious shortcomings, such as time-dependent decoding manner and one-way serial transmission of semantic context, which greatly limit the help of semantic information and the computation efficiency. To mitigate these limitations, we propose a novel end-to-end trainable framework named semantic reasoning network (SRN) for accurate scene text recognition, where a global semantic reasoning module (GSRM) is introduced to capture global semantic context through multi-way parallel transmission. The state-of-the-art results on 7 public benchmarks, including regular text, irregular text and non-Latin long text, verify the effectiveness and robustness of the proposed method. In addition, the speed of SRN has significant advantages over the RNN based methods, demonstrating its value in practical use.