 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextFormer: A Query-based End-to-End Text Spotter with Mixed Supervision
Jun 06, 2023End-to-end text spotting is a vital computer vision task that aims to integrate scene text detection and recognition into a unified framework. Typical methods heavily rely on Region-of-Interest (RoI) operations to extract local features and complex post-processing steps to produce final predictions. To address these limitations, we propose TextFormer, a query-based end-to-end text spotter with Transformer architecture. Specifically, using query embedding per text instance, TextFormer builds upon an image encoder and a text decoder to learn a joint semantic understanding for multi-task modeling. It allows for mutual training and optimization of classification, segmentation, and recognition branches, resulting in deeper feature sharing without sacrificing flexibility or simplicity. Additionally, we design an Adaptive Global aGgregation (AGG) module to transfer global features into sequential features for reading arbitrarily-shaped texts, which overcomes the sub-optimization problem of RoI operations. Furthermore, potential corpus information is utilized from weak annotations to full labels through mixed supervision, further improving text detection and end-to-end text spotting results. Extensive experiments on various bilingual (i.e., English and Chinese) benchmarks demonstrate the superiority of our method. Especially on TDA-ReCTS dataset, TextFormer surpasses the state-of-the-art method in terms of 1-NED by 13.2%.
StrucTexTv2: Masked Visual-Textual Prediction for Document Image Pre-training
Mar 01, 2023



In this paper, we present StrucTexTv2, an effective document image pre-training framework, by performing masked visual-textual prediction. It consists of two self-supervised pre-training tasks: masked image modeling and masked language modeling, based on text region-level image masking. The proposed method randomly masks some image regions according to the bounding box coordinates of text words. The objectives of our pre-training tasks are reconstructing the pixels of masked image regions and the corresponding masked tokens simultaneously. Hence the pre-trained encoder can capture more textual semantics in comparison to the masked image modeling that usually predicts the masked image patches. Compared to the masked multi-modal modeling methods for document image understanding that rely on both the image and text modalities, StrucTexTv2 models image-only input and potentially deals with more application scenarios free from OCR pre-processing. Extensive experiments on mainstream benchmarks of document image understanding demonstrate the effectiveness of StrucTexTv2. It achieves competitive or even new state-of-the-art performance in various downstream tasks such as image classification, layout analysis, table structure recognition, document OCR, and information extraction under the end-to-end scenario.
Multi-Modal Sarcasm Detection Based on Contrastive Attention Mechanism
Sep 30, 2021

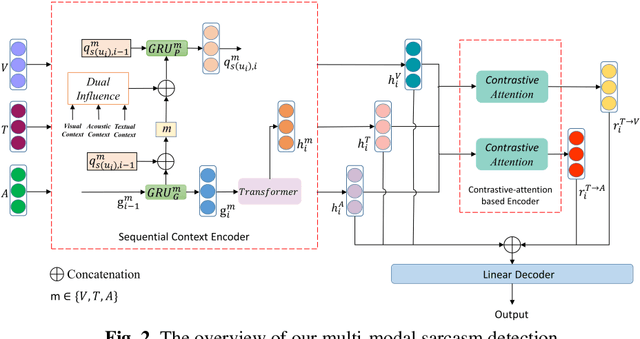
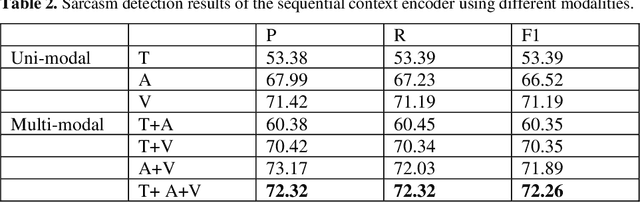
In the past decade, sarcasm detection has been intensively conducted in a textual scenario. With the popularization of video communication, the analysis in multi-modal scenarios has received much attention in recent years. Therefore, multi-modal sarcasm detection, which aims at detecting sarcasm in video conversations, becomes increasingly hot in both the natural language processing community and the multi-modal analysis community. In this paper, considering that sarcasm is often conveyed through incongruity between modalities (e.g., text expressing a compliment while acoustic tone indicating a grumble), we construct a Contras-tive-Attention-based Sarcasm Detection (ConAttSD) model, which uses an inter-modality contrastive attention mechanism to extract several contrastive features for an utterance. A contrastive feature represents the incongruity of information between two modalities. Our experiments on MUStARD, a benchmark multi-modal sarcasm dataset, demonstrate the effectiveness of the proposed ConAttSD model.
PGNet: Real-time Arbitrarily-Shaped Text Spotting with Point Gathering Network
Apr 12, 2021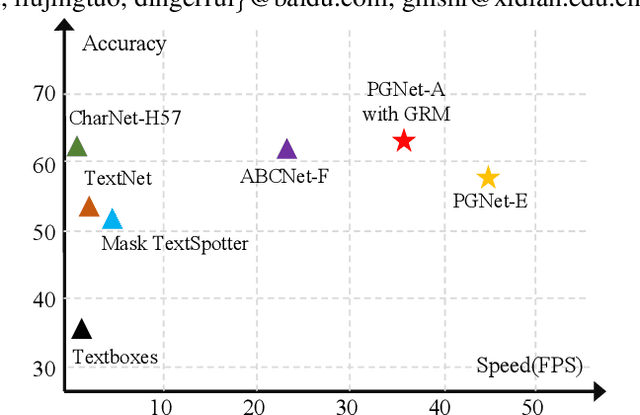
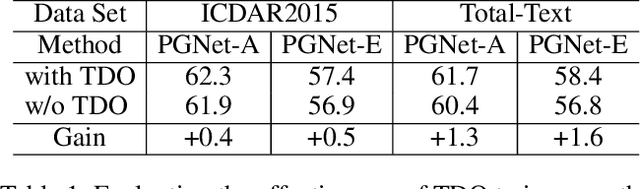
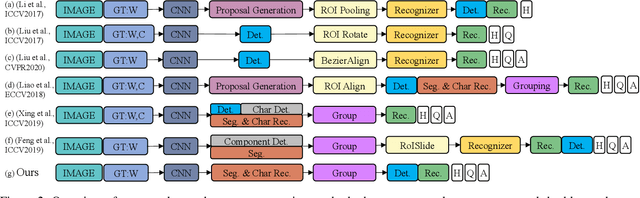
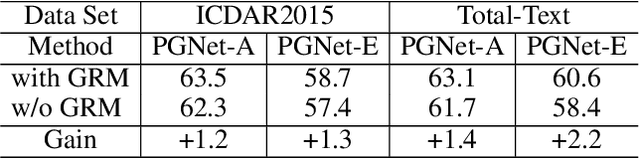
The reading of arbitrarily-shaped text has received increasing research attention. However, existing text spotters are mostly built on two-stage frameworks or character-based methods, which suffer from either Non-Maximum Suppression (NMS), Region-of-Interest (RoI) operations, or character-level annotations. In this paper, to address the above problems, we propose a novel fully convolutional Point Gathering Network (PGNet) for reading arbitrarily-shaped text in real-time. The PGNet is a single-shot text spotter, where the pixel-level character classification map is learned with proposed PG-CTC loss avoiding the usage of character-level annotations. With a PG-CTC decoder, we gather high-level character classification vectors from two-dimensional space and decode them into text symbols without NMS and RoI operations involved, which guarantees high efficiency. Additionally, reasoning the relations between each character and its neighbors, a graph refinement module (GRM) is proposed to optimize the coarse recognition and improve the end-to-end performance. Experiments prove that the proposed method achieves competitive accuracy, meanwhile significantly improving the running speed. In particular, in Total-Text, it runs at 46.7 FPS, surpassing the previous spotters with a large margin.
Hyperspectral Image Dataset for Benchmarking on Salient Object Detection
Jul 02, 2018


Many works have been done on salient object detection using supervised or unsupervised approaches on colour images. Recently, a few studies demonstrated that efficient salient object detection can also be implemented by using spectral features in visible spectrum of hyperspectral images from natural scenes. However, these models on hyperspectral salient object detection were tested with a very few number of data selected from various online public dataset, which are not specifically created for object detection purposes. Therefore, here, we aim to contribute to the field by releasing a hyperspectral salient object detection dataset with a collection of 60 hyperspectral images with their respective ground-truth binary images and representative rendered colour images (sRGB). We took several aspects in consideration during the data collection such as variation in object size, number of objects, foreground-background contrast, object position on the image, and etc. Then, we prepared ground truth binary images for each hyperspectral data, where salient objects are labelled on the images. Finally, we did performance evaluation using Area Under Curve (AUC) metric on some existing hyperspectral saliency detection models in literature.