 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegaStyle: Constructing Diverse and Scalable Style Dataset via Consistent Text-to-Image Style Mapping
Apr 09, 2026In this paper, we introduce MegaStyle, a novel and scalable data curation pipeline that constructs an intra-style consistent, inter-style diverse and high-quality style dataset. We achieve this by leveraging the consistent text-to-image style mapping capability of current large generative models, which can generate images in the same style from a given style description. Building on this foundation, we curate a diverse and balanced prompt gallery with 170K style prompts and 400K content prompts, and generate a large-scale style dataset MegaStyle-1.4M via content-style prompt combinations. With MegaStyle-1.4M, we propose style-supervised contrastive learning to fine-tune a style encoder MegaStyle-Encoder for extracting expressive, style-specific representations, and we also train a FLUX-based style transfer model MegaStyle-FLUX. Extensive experiments demonstrate the importance of maintaining intra-style consistency, inter-style diversity and high-quality for style dataset, as well as the effectiveness of the proposed MegaStyle-1.4M. Moreover, when trained on MegaStyle-1.4M, MegaStyle-Encoder and MegaStyle-FLUX provide reliable style similarity measurement and generalizable style transfer, making a significant contribution to the style transfer community. More results are available at our project website https://jeoyal.github.io/MegaStyle/.
Trade in Minutes! Rationality-Driven Agentic System for Quantitative Financial Trading
Oct 06, 2025



Recent advancements in large language models (LLMs) and agentic systems have shown exceptional decision-making capabilities, revealing significant potential for autonomic finance. Current financial trading agents predominantly simulate anthropomorphic roles that inadvertently introduce emotional biases and rely on peripheral information, while being constrained by the necessity for continuous inference during deployment. In this paper, we pioneer the harmonization of strategic depth in agents with the mechanical rationality essential for quantitative trading. Consequently, we present TiMi (Trade in Minutes), a rationality-driven multi-agent system that architecturally decouples strategy development from minute-level deployment. TiMi leverages specialized LLM capabilities of semantic analysis, code programming, and mathematical reasoning within a comprehensive policy-optimization-deployment chain. Specifically, we propose a two-tier analytical paradigm from macro patterns to micro customization, layered programming design for trading bot implementation, and closed-loop optimization driven by mathematical reflection. Extensive evaluations across 200+ trading pairs in stock and cryptocurrency markets empirically validate the efficacy of TiMi in stable profitability, action efficiency, and risk control under volatile market dynamics.
CharacterShot: Controllable and Consistent 4D Character Animation
Aug 10, 2025In this paper, we propose \textbf{CharacterShot}, a controllable and consistent 4D character animation framework that enables any individual designer to create dynamic 3D characters (i.e., 4D character animation) from a single reference character image and a 2D pose sequence. We begin by pretraining a powerful 2D character animation model based on a cutting-edge DiT-based image-to-video model, which allows for any 2D pose sequnce as controllable signal. We then lift the animation model from 2D to 3D through introducing dual-attention module together with camera prior to generate multi-view videos with spatial-temporal and spatial-view consistency. Finally, we employ a novel neighbor-constrained 4D gaussian splatting optimization on these multi-view videos, resulting in continuous and stable 4D character representations. Moreover, to improve character-centric performance, we construct a large-scale dataset Character4D, containing 13,115 unique characters with diverse appearances and motions, rendered from multiple viewpoints. Extensive experiments on our newly constructed benchmark, CharacterBench, demonstrate that our approach outperforms current state-of-the-art methods. Code, models, and datasets will be publicly available at https://github.com/Jeoyal/CharacterShot.
One Object, Multiple Lies: A Benchmark for Cross-task Adversarial Attack on Unified Vision-Language Models
Jul 10, 2025Unified vision-language models(VLMs) have recently shown remarkable progress, enabling a single model to flexibly address diverse tasks through different instructions within a shared computational architecture. This instruction-based control mechanism creates unique security challenges, as adversarial inputs must remain effective across multiple task instructions that may be unpredictably applied to process the same malicious content. In this paper, we introduce CrossVLAD, a new benchmark dataset carefully curated from MSCOCO with GPT-4-assisted annotations for systematically evaluating cross-task adversarial attacks on unified VLMs. CrossVLAD centers on the object-change objective-consistently manipulating a target object's classification across four downstream tasks-and proposes a novel success rate metric that measures simultaneous misclassification across all tasks, providing a rigorous evaluation of adversarial transferability. To tackle this challenge, we present CRAFT (Cross-task Region-based Attack Framework with Token-alignment), an efficient region-centric attack method. Extensive experiments on Florence-2 and other popular unified VLMs demonstrate that our method outperforms existing approaches in both overall cross-task attack performance and targeted object-change success rates, highlighting its effectiveness in adversarially influencing unified VLMs across diverse tasks.
Explosive Output to Enhance Jumping Ability: A Variable Reduction Ratio Design Paradigm for Humanoid Robots Knee Joint
Jun 14, 2025Enhancing the explosive power output of the knee joints is critical for improving the agility and obstacle-crossing capabilities of humanoid robots. However, a mismatch between the knee-to-center-of-mass (CoM) transmission ratio and jumping demands, coupled with motor performance degradation at high speeds, restricts the duration of high-power output and limits jump performance. To address these problems, this paper introduces a novel knee joint design paradigm employing a dynamically decreasing reduction ratio for explosive output during jump. Analysis of motor output characteristics and knee kinematics during jumping inspired a coupling strategy in which the reduction ratio gradually decreases as the joint extends. A high initial ratio rapidly increases torque at jump initiation, while its gradual reduction minimizes motor speed increments and power losses, thereby maintaining sustained high-power output. A compact and efficient linear actuator-driven guide-rod mechanism realizes this coupling strategy, supported by parameter optimization guided by explosive jump control strategies. Experimental validation demonstrated a 63 cm vertical jump on a single-joint platform (a theoretical improvement of 28.1\% over the optimal fixed-ratio joints). Integrated into a humanoid robot, the proposed design enabled a 1.1 m long jump, a 0.5 m vertical jump, and a 0.5 m box jump.
TRAIL: Transferable Robust Adversarial Images via Latent diffusion
May 22, 2025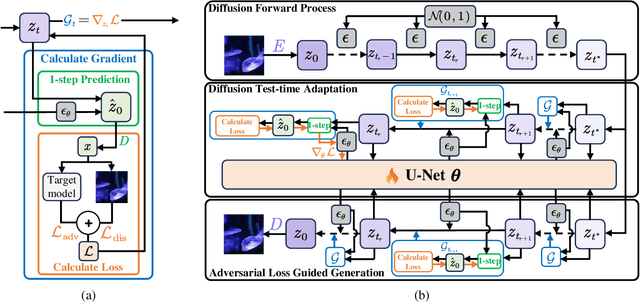
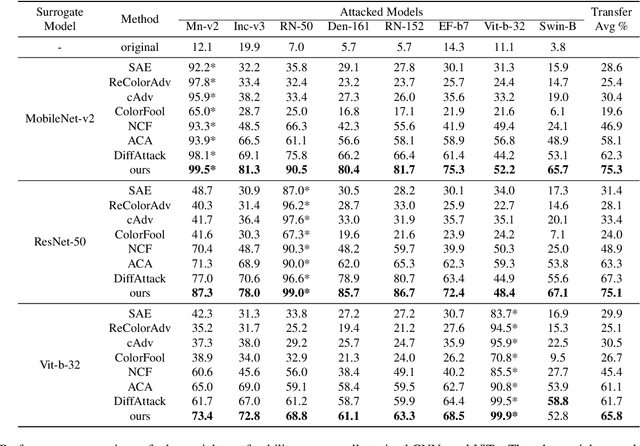
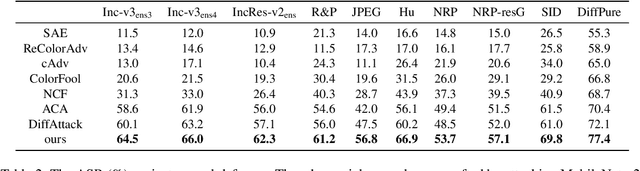

Adversarial attacks exploiting unrestricted natural perturbations present severe security risks to deep learning systems, yet their transferability across models remains limited due to distribution mismatches between generated adversarial features and real-world data. While recent works utilize pre-trained diffusion models as adversarial priors, they still encounter challenges due to the distribution shift between the distribution of ideal adversarial samples and the natural image distribution learned by the diffusion model. To address the challenge, we propose Transferable Robust Adversarial Images via Latent Diffusion (TRAIL), a test-time adaptation framework that enables the model to generate images from a distribution of images with adversarial features and closely resembles the target images. To mitigate the distribution shift, during attacks, TRAIL updates the diffusion U-Net's weights by combining adversarial objectives (to mislead victim models) and perceptual constraints (to preserve image realism). The adapted model then generates adversarial samples through iterative noise injection and denoising guided by these objectives. Experiments demonstrate that TRAIL significantly outperforms state-of-the-art methods in cross-model attack transferability, validating that distribution-aligned adversarial feature synthesis is critical for practical black-box attacks.
LEGO-Puzzles: How Good Are MLLMs at Multi-Step Spatial Reasoning?
Mar 25, 2025



Multi-step spatial reasoning entails understanding and reasoning about spatial relationships across multiple sequential steps, which is crucial for tackling complex real-world applications, such as robotic manipulation, autonomous navigation, and automated assembly. To assess how well current Multimodal Large Language Models (MLLMs) have acquired this fundamental capability, we introduce \textbf{LEGO-Puzzles}, a scalable benchmark designed to evaluate both \textbf{spatial understanding} and \textbf{sequential reasoning} in MLLMs through LEGO-based tasks. LEGO-Puzzles consists of 1,100 carefully curated visual question-answering (VQA) samples spanning 11 distinct tasks, ranging from basic spatial understanding to complex multi-step reasoning. Based on LEGO-Puzzles, we conduct a comprehensive evaluation of state-of-the-art MLLMs and uncover significant limitations in their spatial reasoning capabilities: even the most powerful MLLMs can answer only about half of the test cases, whereas human participants achieve over 90\% accuracy. In addition to VQA tasks, we evaluate MLLMs' abilities to generate LEGO images following assembly illustrations. Our experiments show that only Gemini-2.0-Flash and GPT-4o exhibit a limited ability to follow these instructions, while other MLLMs either replicate the input image or generate completely irrelevant outputs. Overall, LEGO-Puzzles exposes critical deficiencies in existing MLLMs' spatial understanding and sequential reasoning capabilities, and underscores the need for further advancements in multimodal spatial reasoning.
Long-Term TalkingFace Generation via Motion-Prior Conditional Diffusion Model
Feb 13, 2025Recent advances in conditional diffusion models have shown promise for generating realistic TalkingFace videos, yet challenges persist in achieving consistent head movement, synchronized facial expressions, and accurate lip synchronization over extended generations. To address these, we introduce the \textbf{M}otion-priors \textbf{C}onditional \textbf{D}iffusion \textbf{M}odel (\textbf{MCDM}), which utilizes both archived and current clip motion priors to enhance motion prediction and ensure temporal consistency. The model consists of three key elements: (1) an archived-clip motion-prior that incorporates historical frames and a reference frame to preserve identity and context; (2) a present-clip motion-prior diffusion model that captures multimodal causality for accurate predictions of head movements, lip sync, and expressions; and (3) a memory-efficient temporal attention mechanism that mitigates error accumulation by dynamically storing and updating motion features. We also release the \textbf{TalkingFace-Wild} dataset, a multilingual collection of over 200 hours of footage across 10 languages. Experimental results demonstrate the effectiveness of MCDM in maintaining identity and motion continuity for long-term TalkingFace generation. Code, models, and datasets will be publicly available.
DiffPano: Scalable and Consistent Text to Panorama Generation with Spherical Epipolar-Aware Diffusion
Oct 31, 2024



Diffusion-based methods have achieved remarkable achievements in 2D image or 3D object generation, however, the generation of 3D scenes and even $360^{\circ}$ images remains constrained, due to the limited number of scene datasets, the complexity of 3D scenes themselves, and the difficulty of generating consistent multi-view images. To address these issues, we first establish a large-scale panoramic video-text dataset containing millions of consecutive panoramic keyframes with corresponding panoramic depths, camera poses, and text descriptions. Then, we propose a novel text-driven panoramic generation framework, termed DiffPano, to achieve scalable, consistent, and diverse panoramic scene generation. Specifically, benefiting from the powerful generative capabilities of stable diffusion, we fine-tune a single-view text-to-panorama diffusion model with LoRA on the established panoramic video-text dataset. We further design a spherical epipolar-aware multi-view diffusion model to ensure the multi-view consistency of the generated panoramic images. Extensive experiments demonstrate that DiffPano can generate scalable, consistent, and diverse panoramic images with given unseen text descriptions and camera poses.
StyleShot: A Snapshot on Any Style
Jul 01, 2024In this paper, we show that, a good style representation is crucial and sufficient for generalized style transfer without test-time tuning. We achieve this through constructing a style-aware encoder and a well-organized style dataset called StyleGallery. With dedicated design for style learning, this style-aware encoder is trained to extract expressive style representation with decoupling training strategy, and StyleGallery enables the generalization ability. We further employ a content-fusion encoder to enhance image-driven style transfer. We highlight that, our approach, named StyleShot, is simple yet effective in mimicking various desired styles, i.e., 3D, flat, abstract or even fine-grained styles, without test-time tuning. Rigorous experiments validate that, StyleShot achieves superior performance across a wide range of styles compared to existing state-of-the-art methods. The project page is available at: https://styleshot.github.io/.