 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-o3: Deep Nested Omnimodal Deduction for Deliberative Audio-Visual Reasoning
Apr 27, 2026Omnimodal understanding entails a massive, highly redundant search space of cross-modal interactions, demanding focused and deliberative reasoning. Current reasoning paradigms rely on either sequential step-by-step generation or parallel sample-by-sample rollouts, leading to isolated reasoning trajectories. This inability to share promising intermediate paths severely limits exploration efficiency and causes compounding errors in complex audio-visual tasks. To break this bottleneck, we introduce Omni-o3, a novel framework driven by a deep nested deduction policy. By formulating reasoning as a dynamic recursive search, Omni-o3 inherently shares reasoning prefixes across branches, enabling the iterative execution of four atomic cognitive actions: expansion, selection, simulation, and backpropagation. To empower this framework, we propose a robust two-stage training paradigm: (1) cold-start supervised fine-tuning on 101K high-quality, long-chain trajectories distilled from 3.5M diverse omnimodal samples, enabling necessary recursive search patterns; and (2) nested group rollout-driven exploratory reinforcement learning on 18K complex multi-turn samples, explicitly guided by a novel multi-step reward model to stimulate deep nested reasoning. Extensive experiments demonstrate that Omni-o3 achieves competitive performance across 11 benchmarks, unlocking advanced capabilities in comprehensive audio-visual, visual-centric, and audio-centric reasoning tasks.
TRAIL: Transferable Robust Adversarial Images via Latent diffusion
May 22, 2025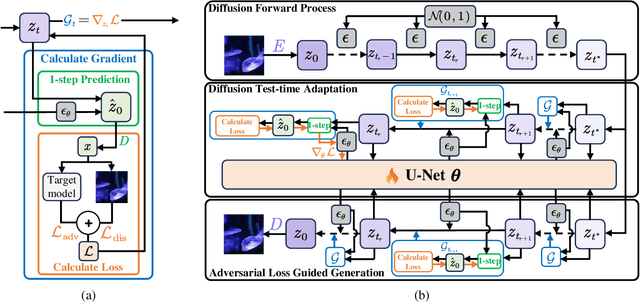
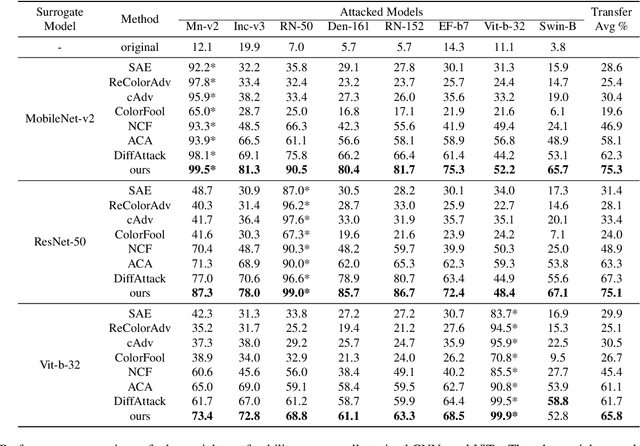
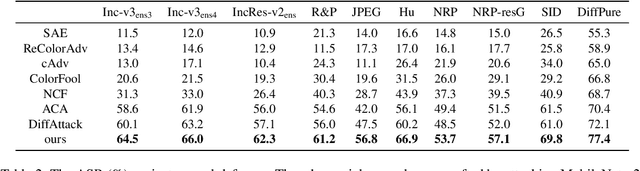

Adversarial attacks exploiting unrestricted natural perturbations present severe security risks to deep learning systems, yet their transferability across models remains limited due to distribution mismatches between generated adversarial features and real-world data. While recent works utilize pre-trained diffusion models as adversarial priors, they still encounter challenges due to the distribution shift between the distribution of ideal adversarial samples and the natural image distribution learned by the diffusion model. To address the challenge, we propose Transferable Robust Adversarial Images via Latent Diffusion (TRAIL), a test-time adaptation framework that enables the model to generate images from a distribution of images with adversarial features and closely resembles the target images. To mitigate the distribution shift, during attacks, TRAIL updates the diffusion U-Net's weights by combining adversarial objectives (to mislead victim models) and perceptual constraints (to preserve image realism). The adapted model then generates adversarial samples through iterative noise injection and denoising guided by these objectives. Experiments demonstrate that TRAIL significantly outperforms state-of-the-art methods in cross-model attack transferability, validating that distribution-aligned adversarial feature synthesis is critical for practical black-box attacks.