 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSINA: Improving Subgraph Extraction for Graph Invariant Learning via Graph Sinkhorn Attention
Feb 11, 2024Graph invariant learning (GIL) has been an effective approach to discovering the invariant relationships between graph data and its labels for different graph learning tasks under various distribution shifts. Many recent endeavors of GIL focus on extracting the invariant subgraph from the input graph for prediction as a regularization strategy to improve the generalization performance of graph learning. Despite their success, such methods also have various limitations in obtaining their invariant subgraphs. In this paper, we provide in-depth analyses of the drawbacks of existing works and propose corresponding principles of our invariant subgraph extraction: 1) the sparsity, to filter out the variant features, 2) the softness, for a broader solution space, and 3) the differentiability, for a soundly end-to-end optimization. To meet these principles in one shot, we leverage the Optimal Transport (OT) theory and propose a novel graph attention mechanism called Graph Sinkhorn Attention (GSINA). This novel approach serves as a powerful regularization method for GIL tasks. By GSINA, we are able to obtain meaningful, differentiable invariant subgraphs with controllable sparsity and softness. Moreover, GSINA is a general graph learning framework that could handle GIL tasks of multiple data grain levels. Extensive experiments on both synthetic and real-world datasets validate the superiority of our GSINA, which outperforms the state-of-the-art GIL methods by large margins on both graph-level tasks and node-level tasks. Our code is publicly available at \url{https://github.com/dingfangyu/GSINA}.
Cross-Task Linearity Emerges in the Pretraining-Finetuning Paradigm
Feb 06, 2024



The pretraining-finetuning paradigm has become the prevailing trend in modern deep learning. In this work, we discover an intriguing linear phenomenon in models that are initialized from a common pretrained checkpoint and finetuned on different tasks, termed as Cross-Task Linearity (CTL). Specifically, if we linearly interpolate the weights of two finetuned models, the features in the weight-interpolated model are approximately equal to the linear interpolation of features in two finetuned models at each layer. Such cross-task linearity has not been noted in peer literature. We provide comprehensive empirical evidence supporting that CTL consistently occurs for finetuned models that start from the same pretrained checkpoint. We conjecture that in the pretraining-finetuning paradigm, neural networks essentially function as linear maps, mapping from the parameter space to the feature space. Based on this viewpoint, our study unveils novel insights into explaining model merging/editing, particularly by translating operations from the parameter space to the feature space. Furthermore, we delve deeper into the underlying factors for the emergence of CTL, emphasizing the impact of pretraining.
Poisson Process for Bayesian Optimization
Feb 05, 2024



BayesianOptimization(BO) is a sample-efficient black-box optimizer, and extensive methods have been proposed to build the absolute function response of the black-box function through a probabilistic surrogate model, including Tree-structured Parzen Estimator (TPE), random forest (SMAC), and Gaussian process (GP). However, few methods have been explored to estimate the relative rankings of candidates, which can be more robust to noise and have better practicality than absolute function responses, especially when the function responses are intractable but preferences can be acquired. To this end, we propose a novel ranking-based surrogate model based on the Poisson process and introduce an efficient BO framework, namely Poisson Process Bayesian Optimization (PoPBO). Two tailored acquisition functions are further derived from classic LCB and EI to accommodate it. Compared to the classic GP-BO method, our PoPBO has lower computation costs and better robustness to noise, which is verified by abundant experiments. The results on both simulated and real-world benchmarks, including hyperparameter optimization (HPO) and neural architecture search (NAS), show the effectiveness of PoPBO.
ViTree: Single-path Neural Tree for Step-wise Interpretable Fine-grained Visual Categorization
Jan 30, 2024



As computer vision continues to advance and finds widespread applications across various domains, the need for interpretability in deep learning models becomes paramount. Existing methods often resort to post-hoc techniques or prototypes to explain the decision-making process, which can be indirect and lack intrinsic illustration. In this research, we introduce ViTree, a novel approach for fine-grained visual categorization that combines the popular vision transformer as a feature extraction backbone with neural decision trees. By traversing the tree paths, ViTree effectively selects patches from transformer-processed features to highlight informative local regions, thereby refining representations in a step-wise manner. Unlike previous tree-based models that rely on soft distributions or ensembles of paths, ViTree selects a single tree path, offering a clearer and simpler decision-making process. This patch and path selectivity enhances model interpretability of ViTree, enabling better insights into the model's inner workings. Remarkably, extensive experimentation validates that this streamlined approach surpasses various strong competitors and achieves state-of-the-art performance while maintaining exceptional interpretability which is proved by multi-perspective methods. Code can be found at https://github.com/SJTU-DeepVisionLab/ViTree.
Continuous-Multiple Image Outpainting in One-Step via Positional Query and A Diffusion-based Approach
Jan 28, 2024Image outpainting aims to generate the content of an input sub-image beyond its original boundaries. It is an important task in content generation yet remains an open problem for generative models. This paper pushes the technical frontier of image outpainting in two directions that have not been resolved in literature: 1) outpainting with arbitrary and continuous multiples (without restriction), and 2) outpainting in a single step (even for large expansion multiples). Moreover, we develop a method that does not depend on a pre-trained backbone network, which is in contrast commonly required by the previous SOTA outpainting methods. The arbitrary multiple outpainting is achieved by utilizing randomly cropped views from the same image during training to capture arbitrary relative positional information. Specifically, by feeding one view and positional embeddings as queries, we can reconstruct another view. At inference, we generate images with arbitrary expansion multiples by inputting an anchor image and its corresponding positional embeddings. The one-step outpainting ability here is particularly noteworthy in contrast to previous methods that need to be performed for $N$ times to obtain a final multiple which is $N$ times of its basic and fixed multiple. We evaluate the proposed approach (called PQDiff as we adopt a diffusion-based generator as our embodiment, under our proposed \textbf{P}ositional \textbf{Q}uery scheme) on public benchmarks, demonstrating its superior performance over state-of-the-art approaches. Specifically, PQDiff achieves state-of-the-art FID scores on the Scenery (\textbf{21.512}), Building Facades (\textbf{25.310}), and WikiArts (\textbf{36.212}) datasets. Furthermore, under the 2.25x, 5x and 11.7x outpainting settings, PQDiff only takes \textbf{40.6\%}, \textbf{20.3\%} and \textbf{10.2\%} of the time of the benchmark state-of-the-art (SOTA) method.
Knowledge Graph Supported Benchmark and Video Captioning for Basketball
Jan 25, 2024



Despite the recent emergence of video captioning models, how to generate the text description with specific entity names and fine-grained actions is far from being solved, which however has great applications such as basketball live text broadcast. In this paper, a new multimodal knowledge supported basketball benchmark for video captioning is proposed. Specifically, we construct a Multimodal Basketball Game Knowledge Graph (MbgKG) to provide knowledge beyond videos. Then, a Multimodal Basketball Game Video Captioning (MbgVC) dataset that contains 9 types of fine-grained shooting events and 286 players' knowledge (i.e., images and names) is constructed based on MbgKG. We develop a novel framework in the encoder-decoder form named Entity-Aware Captioner (EAC) for basketball live text broadcast. The temporal information in video is encoded by introducing the bi-directional GRU (Bi-GRU) module. And the multi-head self-attention module is utilized to model the relationships among the players and select the key players. Besides, we propose a new performance evaluation metric named Game Description Score (GDS), which measures not only the linguistic performance but also the accuracy of the names prediction. Extensive experiments on MbgVC dataset demonstrate that EAC effectively leverages external knowledge and outperforms advanced video captioning models. The proposed benchmark and corresponding codes will be publicly available soon.
Double-Bounded Optimal Transport for Advanced Clustering and Classification
Jan 21, 2024Optimal transport (OT) is attracting increasing attention in machine learning. It aims to transport a source distribution to a target one at minimal cost. In its vanilla form, the source and target distributions are predetermined, which contracts to the real-world case involving undetermined targets. In this paper, we propose Doubly Bounded Optimal Transport (DB-OT), which assumes that the target distribution is restricted within two boundaries instead of a fixed one, thus giving more freedom for the transport to find solutions. Based on the entropic regularization of DB-OT, three scaling-based algorithms are devised for calculating the optimal solution. We also show that our DB-OT is helpful for barycenter-based clustering, which can avoid the excessive concentration of samples in a single cluster. Then we further develop DB-OT techniques for long-tailed classification which is an emerging and open problem. We first propose a connection between OT and classification, that is, in the classification task, training involves optimizing the Inverse OT to learn the representations, while testing involves optimizing the OT for predictions. With this OT perspective, we first apply DB-OT to improve the loss, and the Balanced Softmax is shown as a special case. Then we apply DB-OT for inference in the testing process. Even with vanilla Softmax trained features, our extensive experimental results show that our method can achieve good results with our improved inference scheme in the testing stage.
Machine Learning Insides OptVerse AI Solver: Design Principles and Applications
Jan 17, 2024



In an era of digital ubiquity, efficient resource management and decision-making are paramount across numerous industries. To this end, we present a comprehensive study on the integration of machine learning (ML) techniques into Huawei Cloud's OptVerse AI Solver, which aims to mitigate the scarcity of real-world mathematical programming instances, and to surpass the capabilities of traditional optimization techniques. We showcase our methods for generating complex SAT and MILP instances utilizing generative models that mirror multifaceted structures of real-world problem. Furthermore, we introduce a training framework leveraging augmentation policies to maintain solvers' utility in dynamic environments. Besides the data generation and augmentation, our proposed approaches also include novel ML-driven policies for personalized solver strategies, with an emphasis on applications like graph convolutional networks for initial basis selection and reinforcement learning for advanced presolving and cut selection. Additionally, we detail the incorporation of state-of-the-art parameter tuning algorithms which markedly elevate solver performance. Compared with traditional solvers such as Cplex and SCIP, our ML-augmented OptVerse AI Solver demonstrates superior speed and precision across both established benchmarks and real-world scenarios, reinforcing the practical imperative and effectiveness of machine learning techniques in mathematical programming solvers.
A Synchronized Layer-by-layer Growing Approach for Plausible Neuronal Morphology Generation
Jan 17, 2024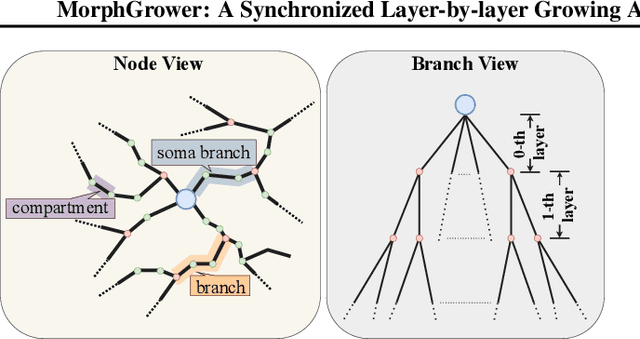
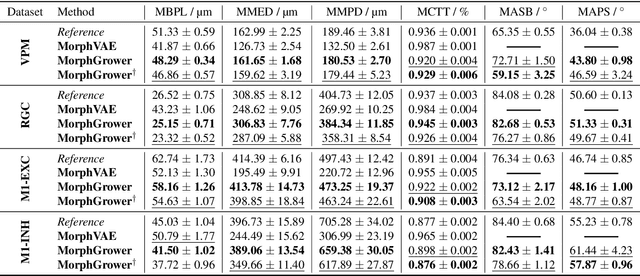
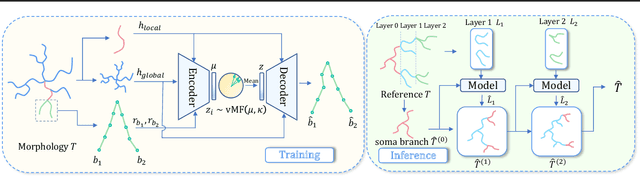

Neuronal morphology is essential for studying brain functioning and understanding neurodegenerative disorders. As the acquiring of real-world morphology data is expensive, computational approaches especially learning-based ones e.g. MorphVAE for morphology generation were recently studied, which are often conducted in a way of randomly augmenting a given authentic morphology to achieve plausibility. Under such a setting, this paper proposes \textbf{MorphGrower} which aims to generate more plausible morphology samples by mimicking the natural growth mechanism instead of a one-shot treatment as done in MorphVAE. Specifically, MorphGrower generates morphologies layer by layer synchronously and chooses a pair of sibling branches as the basic generation block, and the generation of each layer is conditioned on the morphological structure of previous layers and then generate morphologies via a conditional variational autoencoder with spherical latent space. Extensive experimental results on four real-world datasets demonstrate that MorphGrower outperforms MorphVAE by a notable margin. Our code will be publicly available to facilitate future research.
LaneSegNet: Map Learning with Lane Segment Perception for Autonomous Driving
Dec 26, 2023A map, as crucial information for downstream applications of an autonomous driving system, is usually represented in lanelines or centerlines. However, existing literature on map learning primarily focuses on either detecting geometry-based lanelines or perceiving topology relationships of centerlines. Both of these methods ignore the intrinsic relationship of lanelines and centerlines, that lanelines bind centerlines. While simply predicting both types of lane in one model is mutually excluded in learning objective, we advocate lane segment as a new representation that seamlessly incorporates both geometry and topology information. Thus, we introduce LaneSegNet, the first end-to-end mapping network generating lane segments to obtain a complete representation of the road structure. Our algorithm features two key modifications. One is a lane attention module to capture pivotal region details within the long-range feature space. Another is an identical initialization strategy for reference points, which enhances the learning of positional priors for lane attention. On the OpenLane-V2 dataset, LaneSegNet outperforms previous counterparts by a substantial gain across three tasks, \textit{i.e.}, map element detection (+4.8 mAP), centerline perception (+6.9 DET$_l$), and the newly defined one, lane segment perception (+5.6 mAP). Furthermore, it obtains a real-time inference speed of 14.7 FPS. Code is accessible at https://github.com/OpenDriveLab/LaneSegNet.