 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartPhotoCrafter: Unified Reasoning, Generation and Optimization for Automatic Photographic Image Editing
Apr 21, 2026Traditional photographic image editing typically requires users to possess sufficient aesthetic understanding to provide appropriate instructions for adjusting image quality and camera parameters. However, this paradigm relies on explicit human instruction of aesthetic intent, which is often ambiguous, incomplete, or inaccessible to non-expert users. In this work, we propose SmartPhotoCrafter, an automatic photographic image editing method which formulates image editing as a tightly coupled reasoning-to-generation process. The proposed model first performs image quality comprehension and identifies deficiencies by the Image Critic module, and then the Photographic Artist module realizes targeted edits to enhance image appeal, eliminating the need for explicit human instructions. A multi-stage training pipeline is adopted: (i) Foundation pretraining to establish basic aesthetic understanding and editing capabilities, (ii) Adaptation with reasoning-guided multi-edit supervision to incorporate rich semantic guidance, and (iii) Coordinated reasoning-to generation reinforcement learning to jointly optimize reasoning and generation. During training, SmartPhotoCrafter emphasizes photo-realistic image generation, while supporting both image restoration and retouching tasks with consistent adherence to color- and tone-related semantics. We also construct a stage-specific dataset, which progressively builds reasoning and controllable generation, effective cross-module collaboration, and ultimately high-quality photographic enhancement. Experiments demonstrate that SmartPhotoCrafter outperforms existing generative models on the task of automatic photographic enhancement, achieving photo-realistic results while exhibiting higher tonal sensitivity to retouching instructions. Project page: https://github.com/vivoCameraResearch/SmartPhotoCrafter.
CyIN: Cyclic Informative Latent Space for Bridging Complete and Incomplete Multimodal Learning
Feb 04, 2026Multimodal machine learning, mimicking the human brain's ability to integrate various modalities has seen rapid growth. Most previous multimodal models are trained on perfectly paired multimodal input to reach optimal performance. In real-world deployments, however, the presence of modality is highly variable and unpredictable, causing the pre-trained models in suffering significant performance drops and fail to remain robust with dynamic missing modalities circumstances. In this paper, we present a novel Cyclic INformative Learning framework (CyIN) to bridge the gap between complete and incomplete multimodal learning. Specifically, we firstly build an informative latent space by adopting token- and label-level Information Bottleneck (IB) cyclically among various modalities. Capturing task-related features with variational approximation, the informative bottleneck latents are purified for more efficient cross-modal interaction and multimodal fusion. Moreover, to supplement the missing information caused by incomplete multimodal input, we propose cross-modal cyclic translation by reconstruct the missing modalities with the remained ones through forward and reverse propagation process. With the help of the extracted and reconstructed informative latents, CyIN succeeds in jointly optimizing complete and incomplete multimodal learning in one unified model. Extensive experiments on 4 multimodal datasets demonstrate the superior performance of our method in both complete and diverse incomplete scenarios.
TeachBench: A Syllabus-Grounded Framework for Evaluating Teaching Ability in Large Language Models
Jan 29, 2026Large language models (LLMs) show promise as teaching assistants, yet their teaching capability remains insufficiently evaluated. Existing benchmarks mainly focus on problem-solving or problem-level guidance, leaving knowledge-centered teaching underexplored. We propose a syllabus-grounded evaluation framework that measures LLM teaching capability via student performance improvement after multi-turn instruction. By restricting teacher agents to structured knowledge points and example problems, the framework avoids information leakage and enables reuse of existing benchmarks. We instantiate the framework on Gaokao data across multiple subjects. Experiments reveal substantial variation in teaching effectiveness across models and domains: some models perform well in mathematics, while teaching remains challenging in physics and chemistry. We also find that incorporating example problems does not necessarily improve teaching, as models often shift toward example-specific error correction. Overall, our results highlight teaching ability as a distinct and measurable dimension of LLM behavior.
Meta-Learn Unimodal Signals with Weak Supervision for Multimodal Sentiment Analysis
Aug 28, 2024



Multimodal sentiment analysis aims to effectively integrate information from various sources to infer sentiment, where in many cases there are no annotations for unimodal labels. Therefore, most works rely on multimodal labels for training. However, there exists the noisy label problem for the learning of unimodal signals as multimodal annotations are not always the ideal substitutes for the unimodal ones, failing to achieve finer optimization for individual modalities. In this paper, we explore the learning of unimodal labels under the weak supervision from the annotated multimodal labels. Specifically, we propose a novel meta uni-label generation (MUG) framework to address the above problem, which leverages the available multimodal labels to learn the corresponding unimodal labels by the meta uni-label correction network (MUCN). We first design a contrastive-based projection module to bridge the gap between unimodal and multimodal representations, so as to use multimodal annotations to guide the learning of MUCN. Afterwards, we propose unimodal and multimodal denoising tasks to train MUCN with explicit supervision via a bi-level optimization strategy. We then jointly train unimodal and multimodal learning tasks to extract discriminative unimodal features for multimodal inference. Experimental results suggest that MUG outperforms competitive baselines and can learn accurate unimodal labels.
End-to-end Semantic-centric Video-based Multimodal Affective Computing
Aug 14, 2024In the pathway toward Artificial General Intelligence (AGI), understanding human's affection is essential to enhance machine's cognition abilities. For achieving more sensual human-AI interaction, Multimodal Affective Computing (MAC) in human-spoken videos has attracted increasing attention. However, previous methods are mainly devoted to designing multimodal fusion algorithms, suffering from two issues: semantic imbalance caused by diverse pre-processing operations and semantic mismatch raised by inconsistent affection content contained in different modalities comparing with the multimodal ground truth. Besides, the usage of manual features extractors make they fail in building end-to-end pipeline for multiple MAC downstream tasks. To address above challenges, we propose a novel end-to-end framework named SemanticMAC to compute multimodal semantic-centric affection for human-spoken videos. We firstly employ pre-trained Transformer model in multimodal data pre-processing and design Affective Perceiver module to capture unimodal affective information. Moreover, we present a semantic-centric approach to unify multimodal representation learning in three ways, including gated feature interaction, multi-task pseudo label generation, and intra-/inter-sample contrastive learning. Finally, SemanticMAC effectively learn specific- and shared-semantic representations in the guidance of semantic-centric labels. Extensive experimental results demonstrate that our approach surpass the state-of-the-art methods on 7 public datasets in four MAC downstream tasks.
ChatRadio-Valuer: A Chat Large Language Model for Generalizable Radiology Report Generation Based on Multi-institution and Multi-system Data
Oct 10, 2023



Radiology report generation, as a key step in medical image analysis, is critical to the quantitative analysis of clinically informed decision-making levels. However, complex and diverse radiology reports with cross-source heterogeneity pose a huge generalizability challenge to the current methods under massive data volume, mainly because the style and normativity of radiology reports are obviously distinctive among institutions, body regions inspected and radiologists. Recently, the advent of large language models (LLM) offers great potential for recognizing signs of health conditions. To resolve the above problem, we collaborate with the Second Xiangya Hospital in China and propose ChatRadio-Valuer based on the LLM, a tailored model for automatic radiology report generation that learns generalizable representations and provides a basis pattern for model adaptation in sophisticated analysts' cases. Specifically, ChatRadio-Valuer is trained based on the radiology reports from a single institution by means of supervised fine-tuning, and then adapted to disease diagnosis tasks for human multi-system evaluation (i.e., chest, abdomen, muscle-skeleton, head, and maxillofacial $\&$ neck) from six different institutions in clinical-level events. The clinical dataset utilized in this study encompasses a remarkable total of \textbf{332,673} observations. From the comprehensive results on engineering indicators, clinical efficacy and deployment cost metrics, it can be shown that ChatRadio-Valuer consistently outperforms state-of-the-art models, especially ChatGPT (GPT-3.5-Turbo) and GPT-4 et al., in terms of the diseases diagnosis from radiology reports. ChatRadio-Valuer provides an effective avenue to boost model generalization performance and alleviate the annotation workload of experts to enable the promotion of clinical AI applications in radiology reports.
ARS-DETR: Aspect Ratio Sensitive Oriented Object Detection with Transformer
Mar 09, 2023Existing oriented object detection methods commonly use metric AP$_{50}$ to measure the performance of the model. We argue that AP$_{50}$ is inherently unsuitable for oriented object detection due to its large tolerance in angle deviation. Therefore, we advocate using high-precision metric, e.g. AP$_{75}$, to measure the performance of models. In this paper, we propose an Aspect Ratio Sensitive Oriented Object Detector with Transformer, termed ARS-DETR, which exhibits a competitive performance in high-precision oriented object detection. Specifically, a new angle classification method, calling Aspect Ratio aware Circle Smooth Label (AR-CSL), is proposed to smooth the angle label in a more reasonable way and discard the hyperparameter that introduced by previous work (e.g. CSL). Then, a rotated deformable attention module is designed to rotate the sampling points with the corresponding angles and eliminate the misalignment between region features and sampling points. Moreover, a dynamic weight coefficient according to the aspect ratio is adopted to calculate the angle loss. Comprehensive experiments on several challenging datasets show that our method achieves competitive performance on the high-precision oriented object detection task.
Multimodal Information Bottleneck: Learning Minimal Sufficient Unimodal and Multimodal Representations
Nov 12, 2022Learning effective joint embedding for cross-modal data has always been a focus in the field of multimodal machine learning. We argue that during multimodal fusion, the generated multimodal embedding may be redundant, and the discriminative unimodal information may be ignored, which often interferes with accurate prediction and leads to a higher risk of overfitting. Moreover, unimodal representations also contain noisy information that negatively influences the learning of cross-modal dynamics. To this end, we introduce the multimodal information bottleneck (MIB), aiming to learn a powerful and sufficient multimodal representation that is free of redundancy and to filter out noisy information in unimodal representations. Specifically, inheriting from the general information bottleneck (IB), MIB aims to learn the minimal sufficient representation for a given task by maximizing the mutual information between the representation and the target and simultaneously constraining the mutual information between the representation and the input data. Different from general IB, our MIB regularizes both the multimodal and unimodal representations, which is a comprehensive and flexible framework that is compatible with any fusion methods. We develop three MIB variants, namely, early-fusion MIB, late-fusion MIB, and complete MIB, to focus on different perspectives of information constraints. Experimental results suggest that the proposed method reaches state-of-the-art performance on the tasks of multimodal sentiment analysis and multimodal emotion recognition across three widely used datasets. The codes are available at \url{https://github.com/TmacMai/Multimodal-Information-Bottleneck}.
Which is Making the Contribution: Modulating Unimodal and Cross-modal Dynamics for Multimodal Sentiment Analysis
Nov 10, 2021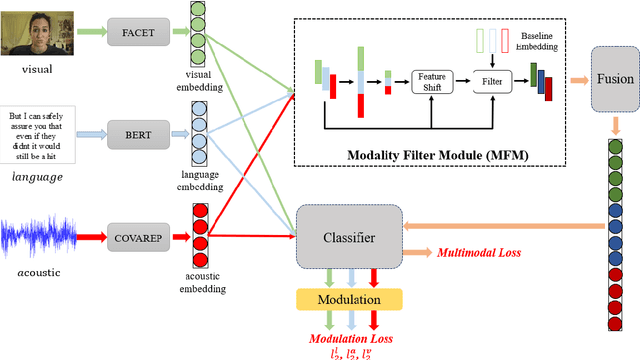
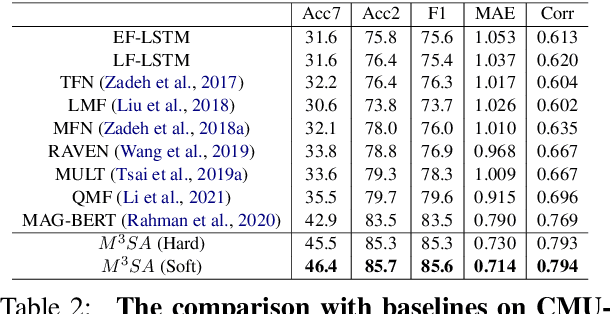
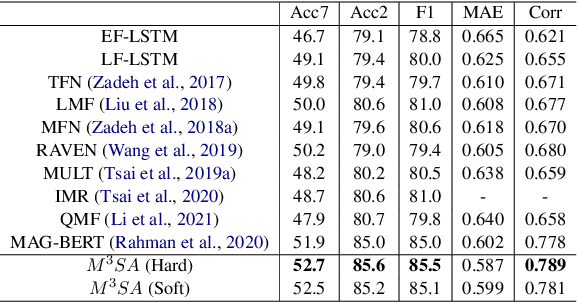
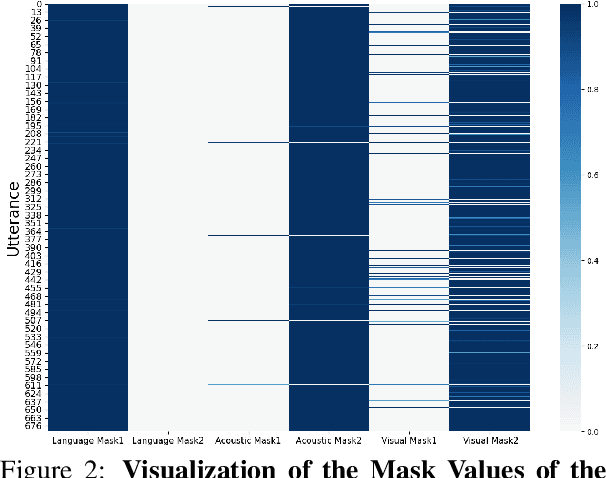
Multimodal sentiment analysis (MSA) draws increasing attention with the availability of multimodal data. The boost in performance of MSA models is mainly hindered by two problems. On the one hand, recent MSA works mostly focus on learning cross-modal dynamics, but neglect to explore an optimal solution for unimodal networks, which determines the lower limit of MSA models. On the other hand, noisy information hidden in each modality interferes the learning of correct cross-modal dynamics. To address the above-mentioned problems, we propose a novel MSA framework \textbf{M}odulation \textbf{M}odel for \textbf{M}ultimodal \textbf{S}entiment \textbf{A}nalysis ({$ M^3SA $}) to identify the contribution of modalities and reduce the impact of noisy information, so as to better learn unimodal and cross-modal dynamics. Specifically, modulation loss is designed to modulate the loss contribution based on the confidence of individual modalities in each utterance, so as to explore an optimal update solution for each unimodal network. Besides, contrary to most existing works which fail to explicitly filter out noisy information, we devise a modality filter module to identify and filter out modality noise for the learning of correct cross-modal embedding. Extensive experiments on publicly datasets demonstrate that our approach achieves state-of-the-art performance.
Hybrid Contrastive Learning of Tri-Modal Representation for Multimodal Sentiment Analysis
Sep 04, 2021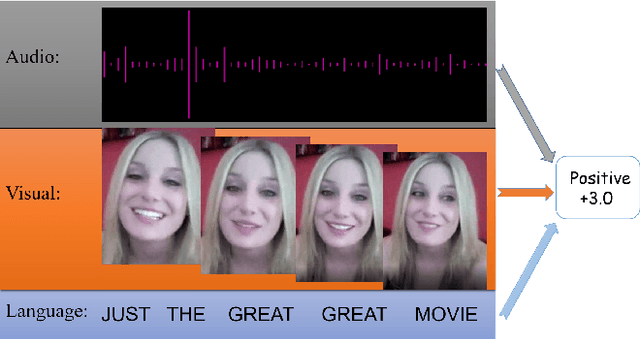
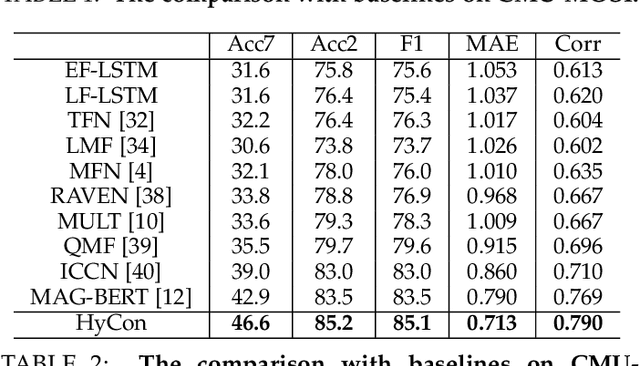
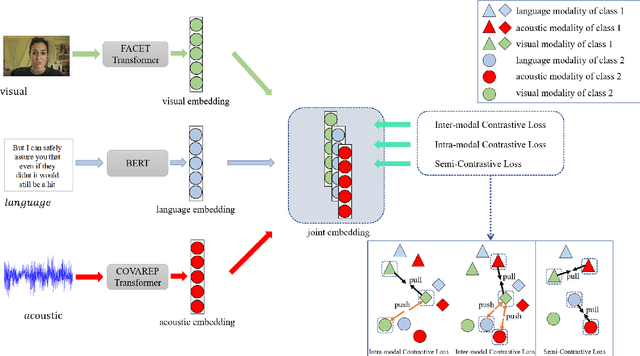
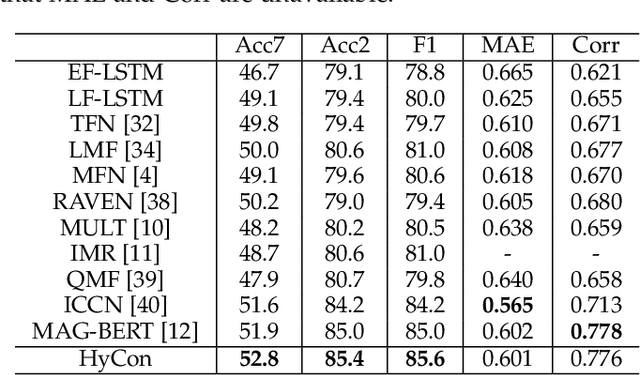
The wide application of smart devices enables the availability of multimodal data, which can be utilized in many tasks. In the field of multimodal sentiment analysis (MSA), most previous works focus on exploring intra- and inter-modal interactions. However, training a network with cross-modal information (language, visual, audio) is still challenging due to the modality gap, and existing methods still cannot ensure to sufficiently learn intra-/inter-modal dynamics. Besides, while learning dynamics within each sample draws great attention, the learning of inter-class relationships is neglected. Moreover, the size of datasets limits the generalization ability of existing methods. To address the afore-mentioned issues, we propose a novel framework HyCon for hybrid contrastive learning of tri-modal representation. Specifically, we simultaneously perform intra-/inter-modal contrastive learning and semi-contrastive learning (that is why we call it hybrid contrastive learning), with which the model can fully explore cross-modal interactions, preserve inter-class relationships and reduce the modality gap. Besides, a refinement term is devised to prevent the model falling into a sub-optimal solution. Moreover, HyCon can naturally generate a large amount of training pairs for better generalization and reduce the negative effect of limited datasets. Extensive experiments on public datasets demonstrate that our proposed method outperforms existing works.