 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing Trustworthy LLM Evaluation via Shortcut Neuron Analysis
Jun 04, 2025The development of large language models (LLMs) depends on trustworthy evaluation. However, most current evaluations rely on public benchmarks, which are prone to data contamination issues that significantly compromise fairness. Previous researches have focused on constructing dynamic benchmarks to address contamination. However, continuously building new benchmarks is costly and cyclical. In this work, we aim to tackle contamination by analyzing the mechanisms of contaminated models themselves. Through our experiments, we discover that the overestimation of contaminated models is likely due to parameters acquiring shortcut solutions in training. We further propose a novel method for identifying shortcut neurons through comparative and causal analysis. Building on this, we introduce an evaluation method called shortcut neuron patching to suppress shortcut neurons. Experiments validate the effectiveness of our approach in mitigating contamination. Additionally, our evaluation results exhibit a strong linear correlation with MixEval, a recently released trustworthy benchmark, achieving a Spearman coefficient ($\rho$) exceeding 0.95. This high correlation indicates that our method closely reveals true capabilities of the models and is trustworthy. We conduct further experiments to demonstrate the generalizability of our method across various benchmarks and hyperparameter settings. Code: https://github.com/GaryStack/Trustworthy-Evaluation
Socratic-PRMBench: Benchmarking Process Reward Models with Systematic Reasoning Patterns
May 29, 2025Process Reward Models (PRMs) are crucial in complex reasoning and problem-solving tasks (e.g., LLM agents with long-horizon decision-making) by verifying the correctness of each intermediate reasoning step. In real-world scenarios, LLMs may apply various reasoning patterns (e.g., decomposition) to solve a problem, potentially suffering from errors under various reasoning patterns. Therefore, PRMs are required to identify errors under various reasoning patterns during the reasoning process. However, existing benchmarks mainly focus on evaluating PRMs with stepwise correctness, ignoring a systematic evaluation of PRMs under various reasoning patterns. To mitigate this gap, we introduce Socratic-PRMBench, a new benchmark to evaluate PRMs systematically under six reasoning patterns, including Transformation, Decomposition, Regather, Deduction, Verification, and Integration. Socratic-PRMBench}comprises 2995 reasoning paths with flaws within the aforementioned six reasoning patterns. Through our experiments on both PRMs and LLMs prompted as critic models, we identify notable deficiencies in existing PRMs. These observations underscore the significant weakness of current PRMs in conducting evaluations on reasoning steps under various reasoning patterns. We hope Socratic-PRMBench can serve as a comprehensive testbed for systematic evaluation of PRMs under diverse reasoning patterns and pave the way for future development of PRMs.
Large Language Models for Planning: A Comprehensive and Systematic Survey
May 26, 2025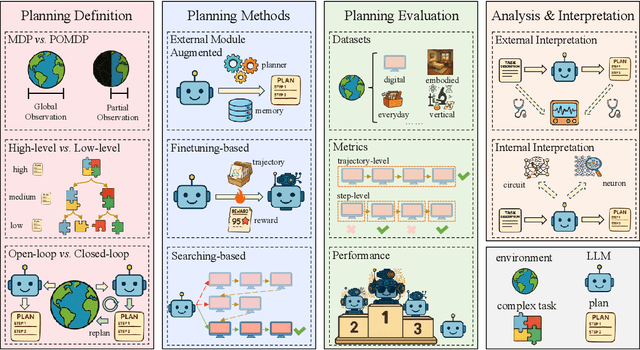
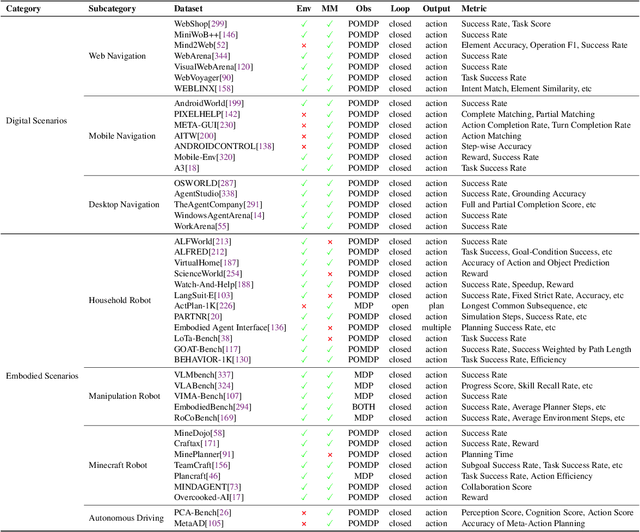
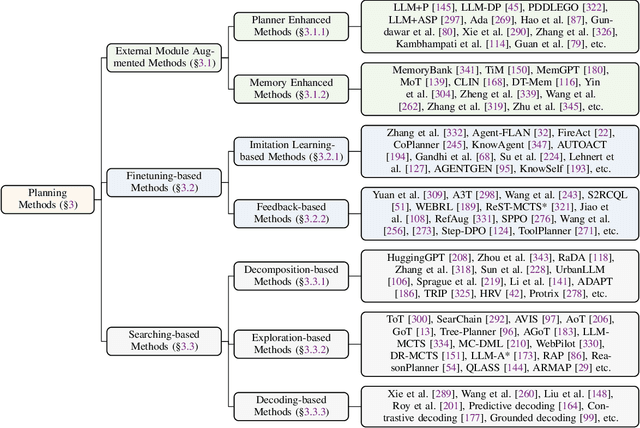
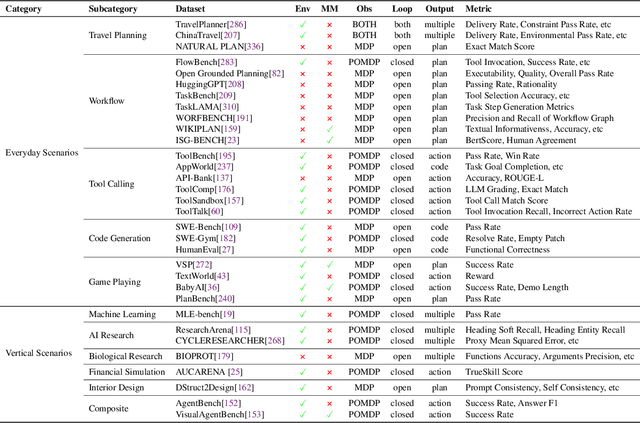
Planning represents a fundamental capability of intelligent agents, requiring comprehensive environmental understanding, rigorous logical reasoning, and effective sequential decision-making. While Large Language Models (LLMs) have demonstrated remarkable performance on certain planning tasks, their broader application in this domain warrants systematic investigation. This paper presents a comprehensive review of LLM-based planning. Specifically, this survey is structured as follows: First, we establish the theoretical foundations by introducing essential definitions and categories about automated planning. Next, we provide a detailed taxonomy and analysis of contemporary LLM-based planning methodologies, categorizing them into three principal approaches: 1) External Module Augmented Methods that combine LLMs with additional components for planning, 2) Finetuning-based Methods that involve using trajectory data and feedback signals to adjust LLMs in order to improve their planning abilities, and 3) Searching-based Methods that break down complex tasks into simpler components, navigate the planning space, or enhance decoding strategies to find the best solutions. Subsequently, we systematically summarize existing evaluation frameworks, including benchmark datasets, evaluation metrics and performance comparisons between representative planning methods. Finally, we discuss the underlying mechanisms enabling LLM-based planning and outline promising research directions for this rapidly evolving field. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this field.
Amplify Adjacent Token Differences: Enhancing Long Chain-of-Thought Reasoning with Shift-FFN
May 22, 2025Recently, models such as OpenAI-o1 and DeepSeek-R1 have demonstrated remarkable performance on complex reasoning tasks through Long Chain-of-Thought (Long-CoT) reasoning. Although distilling this capability into student models significantly enhances their performance, this paper finds that fine-tuning LLMs with full parameters or LoRA with a low rank on long CoT data often leads to Cyclical Reasoning, where models repeatedly reiterate previous inference steps until the maximum length limit. Further analysis reveals that smaller differences in representations between adjacent tokens correlates with a higher tendency toward Cyclical Reasoning. To mitigate this issue, this paper proposes Shift Feedforward Networks (Shift-FFN), a novel approach that edits the current token's representation with the previous one before inputting it to FFN. This architecture dynamically amplifies the representation differences between adjacent tokens. Extensive experiments on multiple mathematical reasoning tasks demonstrate that LoRA combined with Shift-FFN achieves higher accuracy and a lower rate of Cyclical Reasoning across various data sizes compared to full fine-tuning and standard LoRA. Our data and code are available at https://anonymous.4open.science/r/Shift-FFN
Semantic Pivots Enable Cross-Lingual Transfer in Large Language Models
May 22, 2025Large language models (LLMs) demonstrate remarkable ability in cross-lingual tasks. Understanding how LLMs acquire this ability is crucial for their interpretability. To quantify the cross-lingual ability of LLMs accurately, we propose a Word-Level Cross-Lingual Translation Task. To find how LLMs learn cross-lingual ability, we trace the outputs of LLMs' intermediate layers in the word translation task. We identify and distinguish two distinct behaviors in the forward pass of LLMs: co-occurrence behavior and semantic pivot behavior. We attribute LLMs' two distinct behaviors to the co-occurrence frequency of words and find the semantic pivot from the pre-training dataset. Finally, to apply our findings to improve the cross-lingual ability of LLMs, we reconstruct a semantic pivot-aware pre-training dataset using documents with a high proportion of semantic pivots. Our experiments validate the effectiveness of our approach in enhancing cross-lingual ability. Our research contributes insights into the interpretability of LLMs and offers a method for improving LLMs' cross-lingual ability.
Beyond Hard and Soft: Hybrid Context Compression for Balancing Local and Global Information Retention
May 21, 2025Large Language Models (LLMs) encounter significant challenges in long-sequence inference due to computational inefficiency and redundant processing, driving interest in context compression techniques. Existing methods often rely on token importance to perform hard local compression or encode context into latent representations for soft global compression. However, the uneven distribution of textual content relevance and the diversity of demands for user instructions mean these approaches frequently lead to the loss of potentially valuable information. To address this, we propose $\textbf{Hy}$brid $\textbf{Co}$ntext $\textbf{Co}$mpression (HyCo$_2$) for LLMs, which integrates both global and local perspectives to guide context compression while retaining both the essential semantics and critical details for task completion. Specifically, we employ a hybrid adapter to refine global semantics with the global view, based on the observation that different adapters excel at different tasks. Then we incorporate a classification layer that assigns a retention probability to each context token based on the local view, determining whether it should be retained or discarded. To foster a balanced integration of global and local compression, we introduce auxiliary paraphrasing and completion pretraining before instruction tuning. This promotes a synergistic integration that emphasizes instruction-relevant information while preserving essential local details, ultimately balancing local and global information retention in context compression. Experiments show that our HyCo$_2$ method significantly enhances long-text reasoning while reducing token usage. It improves the performance of various LLM series by an average of 13.1\% across seven knowledge-intensive QA benchmarks. Moreover, HyCo$_2$ matches the performance of uncompressed methods while reducing token consumption by 88.8\%.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Code2Logic: Game-Code-Driven Data Synthesis for Enhancing VLMs General Reasoning
May 20, 2025Visual-language Chain-of-Thought (CoT) data resources are relatively scarce compared to text-only counterparts, limiting the improvement of reasoning capabilities in Vision Language Models (VLMs). However, high-quality vision-language reasoning data is expensive and labor-intensive to annotate. To address this issue, we leverage a promising resource: game code, which naturally contains logical structures and state transition processes. Therefore, we propose Code2Logic, a novel game-code-driven approach for multimodal reasoning data synthesis. Our approach leverages Large Language Models (LLMs) to adapt game code, enabling automatic acquisition of reasoning processes and results through code execution. Using the Code2Logic approach, we developed the GameQA dataset to train and evaluate VLMs. GameQA is cost-effective and scalable to produce, challenging for state-of-the-art models, and diverse with 30 games and 158 tasks. Surprisingly, despite training solely on game data, VLMs demonstrated out of domain generalization, specifically Qwen2.5-VL-7B improving performance by 2.33\% across 7 diverse vision-language benchmarks. Our code and dataset are available at https://github.com/tongjingqi/Code2Logic.
Neural Incompatibility: The Unbridgeable Gap of Cross-Scale Parametric Knowledge Transfer in Large Language Models
May 20, 2025



Large Language Models (LLMs) offer a transparent brain with accessible parameters that encode extensive knowledge, which can be analyzed, located and transferred. Consequently, a key research challenge is to transcend traditional knowledge transfer paradigms rooted in symbolic language and achieve genuine Parametric Knowledge Transfer (PKT). Significantly, exploring effective methods for transferring knowledge across LLMs of different scales through parameters presents an intriguing and valuable research direction. In this paper, we first demonstrate $\textbf{Alignment}$ in parametric space is the fundamental prerequisite to achieve successful cross-scale PKT. We redefine the previously explored knowledge transfer as Post-Align PKT (PostPKT), which utilizes extracted parameters for LoRA initialization and requires subsequent fine-tune for alignment. Hence, to reduce cost for further fine-tuning, we introduce a novel Pre-Align PKT (PrePKT) paradigm and propose a solution called $\textbf{LaTen}$ ($\textbf{L}$oc$\textbf{a}$te-$\textbf{T}$h$\textbf{e}$n-Alig$\textbf{n}$) that aligns the parametric spaces of LLMs across scales only using several training steps without following training. Comprehensive experiments on four benchmarks demonstrate that both PostPKT and PrePKT face challenges in achieving consistently stable transfer. Through in-depth analysis, we identify $\textbf{Neural Incompatibility}$ as the ethological and parametric structural differences between LLMs of varying scales, presenting fundamental challenges to achieving effective PKT. These findings provide fresh insights into the parametric architectures of LLMs and highlight promising directions for future research on efficient PKT. Our code is available at https://github.com/Trae1ounG/Neural_Incompatibility.
Revealing the Deceptiveness of Knowledge Editing: A Mechanistic Analysis of Superficial Editing
May 19, 2025Knowledge editing, which aims to update the knowledge encoded in language models, can be deceptive. Despite the fact that many existing knowledge editing algorithms achieve near-perfect performance on conventional metrics, the models edited by them are still prone to generating original knowledge. This paper introduces the concept of "superficial editing" to describe this phenomenon. Our comprehensive evaluation reveals that this issue presents a significant challenge to existing algorithms. Through systematic investigation, we identify and validate two key factors contributing to this issue: (1) the residual stream at the last subject position in earlier layers and (2) specific attention modules in later layers. Notably, certain attention heads in later layers, along with specific left singular vectors in their output matrices, encapsulate the original knowledge and exhibit a causal relationship with superficial editing. Furthermore, we extend our analysis to the task of superficial unlearning, where we observe consistent patterns in the behavior of specific attention heads and their corresponding left singular vectors, thereby demonstrating the robustness and broader applicability of our methodology and conclusions. Our code is available here.