 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Grokking Worthwhile? Functional Analysis and Transferability of Generalization Circuits in Transformers
Jan 14, 2026While Large Language Models (LLMs) excel at factual retrieval, they often struggle with the "curse of two-hop reasoning" in compositional tasks. Recent research suggests that parameter-sharing transformers can bridge this gap by forming a "Generalization Circuit" during a prolonged "grokking" phase. A fundamental question arises: Is a grokked model superior to its non-grokked counterparts on downstream tasks? Furthermore, is the extensive computational cost of waiting for the grokking phase worthwhile? In this work, we conduct a mechanistic study to evaluate the Generalization Circuit's role in knowledge assimilation and transfer. We demonstrate that: (i) The inference paths established by non-grokked and grokked models for in-distribution compositional queries are identical. This suggests that the "Generalization Circuit" does not represent the sudden acquisition of a new reasoning paradigm. Instead, we argue that grokking is the process of integrating memorized atomic facts into an naturally established reasoning path. (ii) Achieving high accuracy on unseen cases after prolonged training and the formation of a certain reasoning path are not bound; they can occur independently under specific data regimes. (iii) Even a mature circuit exhibits limited transferability when integrating new knowledge, suggesting that "grokked" Transformers do not achieve a full mastery of compositional logic.
HiPRAG: Hierarchical Process Rewards for Efficient Agentic Retrieval Augmented Generation
Oct 09, 2025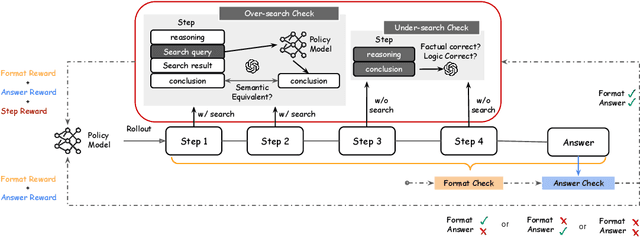
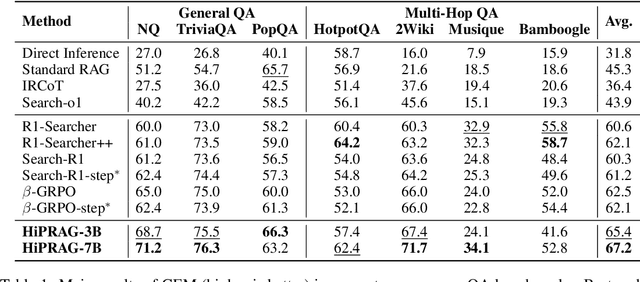
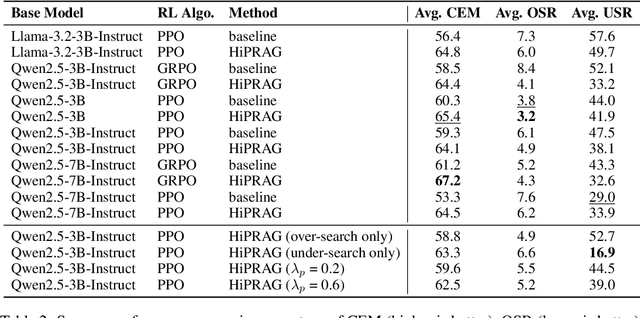
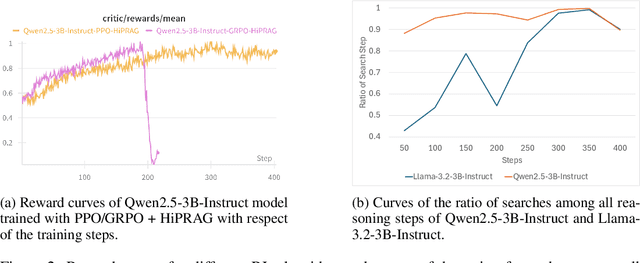
Agentic RAG is a powerful technique for incorporating external information that LLMs lack, enabling better problem solving and question answering. However, suboptimal search behaviors exist widely, such as over-search (retrieving information already known) and under-search (failing to search when necessary), which leads to unnecessary overhead and unreliable outputs. Current training methods, which typically rely on outcome-based rewards in a RL framework, lack the fine-grained control needed to address these inefficiencies. To overcome this, we introduce Hierarchical Process Rewards for Efficient agentic RAG (HiPRAG), a training methodology that incorporates a fine-grained, knowledge-grounded process reward into the RL training. Our approach evaluates the necessity of each search decision on-the-fly by decomposing the agent's reasoning trajectory into discrete, parsable steps. We then apply a hierarchical reward function that provides an additional bonus based on the proportion of optimal search and non-search steps, on top of commonly used outcome and format rewards. Experiments on the Qwen2.5 and Llama-3.2 models across seven diverse QA benchmarks show that our method achieves average accuracies of 65.4% (3B) and 67.2% (7B). This is accomplished while improving search efficiency, reducing the over-search rate to just 2.3% and concurrently lowering the under-search rate. These results demonstrate the efficacy of optimizing the reasoning process itself, not just the final outcome. Further experiments and analysis demonstrate that HiPRAG shows good generalizability across a wide range of RL algorithms, model families, sizes, and types. This work demonstrates the importance and potential of fine-grained control through RL, for improving the efficiency and optimality of reasoning for search agents.
From Reasoning to Learning: A Survey on Hypothesis Discovery and Rule Learning with Large Language Models
May 28, 2025Since the advent of Large Language Models (LLMs), efforts have largely focused on improving their instruction-following and deductive reasoning abilities, leaving open the question of whether these models can truly discover new knowledge. In pursuit of artificial general intelligence (AGI), there is a growing need for models that not only execute commands or retrieve information but also learn, reason, and generate new knowledge by formulating novel hypotheses and theories that deepen our understanding of the world. Guided by Peirce's framework of abduction, deduction, and induction, this survey offers a structured lens to examine LLM-based hypothesis discovery. We synthesize existing work in hypothesis generation, application, and validation, identifying both key achievements and critical gaps. By unifying these threads, we illuminate how LLMs might evolve from mere ``information executors'' into engines of genuine innovation, potentially transforming research, science, and real-world problem solving.
Semantic Pivots Enable Cross-Lingual Transfer in Large Language Models
May 22, 2025Large language models (LLMs) demonstrate remarkable ability in cross-lingual tasks. Understanding how LLMs acquire this ability is crucial for their interpretability. To quantify the cross-lingual ability of LLMs accurately, we propose a Word-Level Cross-Lingual Translation Task. To find how LLMs learn cross-lingual ability, we trace the outputs of LLMs' intermediate layers in the word translation task. We identify and distinguish two distinct behaviors in the forward pass of LLMs: co-occurrence behavior and semantic pivot behavior. We attribute LLMs' two distinct behaviors to the co-occurrence frequency of words and find the semantic pivot from the pre-training dataset. Finally, to apply our findings to improve the cross-lingual ability of LLMs, we reconstruct a semantic pivot-aware pre-training dataset using documents with a high proportion of semantic pivots. Our experiments validate the effectiveness of our approach in enhancing cross-lingual ability. Our research contributes insights into the interpretability of LLMs and offers a method for improving LLMs' cross-lingual ability.
IDEA: Enhancing the rule learning ability of language agent through Induction, DEuction, and Abduction
Aug 19, 2024While large language models (LLMs) have been thoroughly evaluated for deductive and inductive reasoning, their proficiency in abductive reasoning and holistic rule learning in interactive environments remains less explored. This work introduces RULEARN, a novel benchmark specifically designed to assess the rule-learning ability of LLMs in interactive settings. In RULEARN, agents interact with the environment to gather observations and discern patterns, using these insights to solve problems. To further enhance the rule-learning capabilities of LLM agents within this benchmark, we propose IDEA agent, which integrates Induction, Deduction, and Abduction processes. IDEA agent refines this approach by leveraging a structured reasoning sequence: generating hypotheses through abduction, testing them via deduction, and refining them based on induction feedback. This sequence enables agents to dynamically establish and apply rules, mimicking human-like reasoning processes. Our evaluation of five representative LLMs indicates that while these models can generate plausible initial hypotheses, they often struggle with strategic interaction within the environment, effective incorporation of feedback, and adaptive refinement of their hypotheses. IDEA agent demonstrates significantly improved performance on the RULEARN benchmark, offering valuable insights for the development of agents capable of human-like rule-learning in real-world scenarios. We will release our code and data.