 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mechanism-Learning Deeply Coupled Model for Remote Sensing Retrieval of Global Land Surface Temperature
Apr 10, 2025Land surface temperature (LST) retrieval from remote sensing data is pivotal for analyzing climate processes and surface energy budgets. However, LST retrieval is an ill-posed inverse problem, which becomes particularly severe when only a single band is available. In this paper, we propose a deeply coupled framework integrating mechanistic modeling and machine learning to enhance the accuracy and generalizability of single-channel LST retrieval. Training samples are generated using a physically-based radiative transfer model and a global collection of 5810 atmospheric profiles. A physics-informed machine learning framework is proposed to systematically incorporate the first principles from classical physical inversion models into the learning workflow, with optimization constrained by radiative transfer equations. Global validation demonstrated a 30% reduction in root-mean-square error versus standalone methods. Under extreme humidity, the mean absolute error decreased from 4.87 K to 2.29 K (53% improvement). Continental-scale tests across five continents confirmed the superior generalizability of this model.
MedSAM2: Segment Anything in 3D Medical Images and Videos
Apr 04, 2025Medical image and video segmentation is a critical task for precision medicine, which has witnessed considerable progress in developing task or modality-specific and generalist models for 2D images. However, there have been limited studies on building general-purpose models for 3D images and videos with comprehensive user studies. Here, we present MedSAM2, a promptable segmentation foundation model for 3D image and video segmentation. The model is developed by fine-tuning the Segment Anything Model 2 on a large medical dataset with over 455,000 3D image-mask pairs and 76,000 frames, outperforming previous models across a wide range of organs, lesions, and imaging modalities. Furthermore, we implement a human-in-the-loop pipeline to facilitate the creation of large-scale datasets resulting in, to the best of our knowledge, the most extensive user study to date, involving the annotation of 5,000 CT lesions, 3,984 liver MRI lesions, and 251,550 echocardiogram video frames, demonstrating that MedSAM2 can reduce manual costs by more than 85%. MedSAM2 is also integrated into widely used platforms with user-friendly interfaces for local and cloud deployment, making it a practical tool for supporting efficient, scalable, and high-quality segmentation in both research and healthcare environments.
Semi-SD: Semi-Supervised Metric Depth Estimation via Surrounding Cameras for Autonomous Driving
Mar 25, 2025In this paper, we introduce Semi-SD, a novel metric depth estimation framework tailored for surrounding cameras equipment in autonomous driving. In this work, the input data consists of adjacent surrounding frames and camera parameters. We propose a unified spatial-temporal-semantic fusion module to construct the visual fused features. Cross-attention components for surrounding cameras and adjacent frames are utilized to focus on metric scale information refinement and temporal feature matching. Building on this, we propose a pose estimation framework using surrounding cameras, their corresponding estimated depths, and extrinsic parameters, which effectively address the scale ambiguity in multi-camera setups. Moreover, semantic world model and monocular depth estimation world model are integrated to supervised the depth estimation, which improve the quality of depth estimation. We evaluate our algorithm on DDAD and nuScenes datasets, and the results demonstrate that our method achieves state-of-the-art performance in terms of surrounding camera based depth estimation quality. The source code will be available on https://github.com/xieyuser/Semi-SD.
AKF-LIO: LiDAR-Inertial Odometry with Gaussian Map by Adaptive Kalman Filter
Mar 10, 2025Existing LiDAR-Inertial Odometry (LIO) systems typically use sensor-specific or environment-dependent measurement covariances during state estimation, leading to laborious parameter tuning and suboptimal performance in challenging conditions (e.g., sensor degeneracy and noisy observations). Therefore, we propose an Adaptive Kalman Filter (AKF) framework that dynamically estimates time-varying noise covariances of LiDAR and Inertial Measurement Unit (IMU) measurements, enabling context-aware confidence weighting between sensors. During LiDAR degeneracy, the system prioritizes IMU data while suppressing contributions from unreliable inputs like moving objects or noisy point clouds. Furthermore, a compact Gaussian-based map representation is introduced to model environmental planarity and spatial noise. A correlated registration strategy ensures accurate plane normal estimation via pseudo-merge, even in unstructured environments like forests. Extensive experiments validate the robustness of the proposed system across diverse environments, including dynamic scenes and geometrically degraded scenarios. Our method achieves reliable localization results across all MARS-LVIG sequences and ranks 8th on the KITTI Odometry Benchmark. The code will be released at https://github.com/xpxie/AKF-LIO.git.
Occlusion-Aware Consistent Model Predictive Control for Robot Navigation in Occluded Obstacle-Dense Environments
Mar 06, 2025



Ensuring safety and motion consistency for robot navigation in occluded, obstacle-dense environments is a critical challenge. In this context, this study presents an occlusion-aware Consistent Model Predictive Control (CMPC) strategy. To account for the occluded obstacles, it incorporates adjustable risk regions that represent their potential future locations. Subsequently, dynamic risk boundary constraints are developed online to ensure safety. The CMPC then constructs multiple locally optimal trajectory branches (each tailored to different risk regions) to balance between exploitation and exploration. A shared consensus trunk is generated to ensure smooth transitions between branches without significant velocity fluctuations, further preserving motion consistency. To facilitate high computational efficiency and ensure coordination across local trajectories, we use the alternating direction method of multipliers (ADMM) to decompose the CMPC into manageable sub-problems for parallel solving. The proposed strategy is validated through simulation and real-world experiments on an Ackermann-steering robot platform. The results demonstrate the effectiveness of the proposed CMPC strategy through comparisons with baseline approaches in occluded, obstacle-dense environments.
Fair Play in the Fast Lane: Integrating Sportsmanship into Autonomous Racing Systems
Mar 04, 2025Autonomous racing has gained significant attention as a platform for high-speed decision-making and motion control. While existing methods primarily focus on trajectory planning and overtaking strategies, the role of sportsmanship in ensuring fair competition remains largely unexplored. In human racing, rules such as the one-motion rule and the enough-space rule prevent dangerous and unsportsmanlike behavior. However, autonomous racing systems often lack mechanisms to enforce these principles, potentially leading to unsafe maneuvers. This paper introduces a bi-level game-theoretic framework to integrate sportsmanship (SPS) into versus racing. At the high level, we model racing intentions using a Stackelberg game, where Monte Carlo Tree Search (MCTS) is employed to derive optimal strategies. At the low level, vehicle interactions are formulated as a Generalized Nash Equilibrium Problem (GNEP), ensuring that all agents follow sportsmanship constraints while optimizing their trajectories. Simulation results demonstrate the effectiveness of the proposed approach in enforcing sportsmanship rules while maintaining competitive performance. We analyze different scenarios where attackers and defenders adhere to or disregard sportsmanship rules and show how knowledge of these constraints influences strategic decision-making. This work highlights the importance of balancing competition and fairness in autonomous racing and provides a foundation for developing ethical and safe AI-driven racing systems.
Unlocking a New Rust Programming Experience: Fast and Slow Thinking with LLMs to Conquer Undefined Behaviors
Mar 04, 2025



To provide flexibility and low-level interaction capabilities, the unsafe tag in Rust is essential in many projects, but undermines memory safety and introduces Undefined Behaviors (UBs) that reduce safety. Eliminating these UBs requires a deep understanding of Rust's safety rules and strong typing. Traditional methods require depth analysis of code, which is laborious and depends on knowledge design. The powerful semantic understanding capabilities of LLM offer new opportunities to solve this problem. Although existing large model debugging frameworks excel in semantic tasks, limited by fixed processes and lack adaptive and dynamic adjustment capabilities. Inspired by the dual process theory of decision-making (Fast and Slow Thinking), we present a LLM-based framework called RustBrain that automatically and flexibly minimizes UBs in Rust projects. Fast thinking extracts features to generate solutions, while slow thinking decomposes, verifies, and generalizes them abstractly. To apply verification and generalization results to solution generation, enabling dynamic adjustments and precise outputs, RustBrain integrates two thinking through a feedback mechanism. Experimental results on Miri dataset show a 94.3% pass rate and 80.4% execution rate, improving flexibility and Rust projects safety.
Accelerating Vision-Language-Action Model Integrated with Action Chunking via Parallel Decoding
Mar 04, 2025Vision-Language-Action (VLA) models demonstrate remarkable potential for generalizable robotic manipulation. The performance of VLA models can be improved by integrating with action chunking, a critical technique for effective control. However, action chunking linearly scales up action dimensions in VLA models with increased chunking sizes. This reduces the inference efficiency. To tackle this problem, we propose PD-VLA, the first parallel decoding framework for VLA models integrated with action chunking. Our framework reformulates autoregressive decoding as a nonlinear system solved by parallel fixed-point iterations. This approach preserves model performance with mathematical guarantees while significantly improving decoding speed. In addition, it enables training-free acceleration without architectural changes, as well as seamless synergy with existing acceleration techniques. Extensive simulations validate that our PD-VLA maintains competitive success rates while achieving 2.52 times execution frequency on manipulators (with 7 degrees of freedom) compared with the fundamental VLA model. Furthermore, we experimentally identify the most effective settings for acceleration. Finally, real-world experiments validate its high applicability across different tasks.
DifIISR: A Diffusion Model with Gradient Guidance for Infrared Image Super-Resolution
Mar 03, 2025



Infrared imaging is essential for autonomous driving and robotic operations as a supportive modality due to its reliable performance in challenging environments. Despite its popularity, the limitations of infrared cameras, such as low spatial resolution and complex degradations, consistently challenge imaging quality and subsequent visual tasks. Hence, infrared image super-resolution (IISR) has been developed to address this challenge. While recent developments in diffusion models have greatly advanced this field, current methods to solve it either ignore the unique modal characteristics of infrared imaging or overlook the machine perception requirements. To bridge these gaps, we propose DifIISR, an infrared image super-resolution diffusion model optimized for visual quality and perceptual performance. Our approach achieves task-based guidance for diffusion by injecting gradients derived from visual and perceptual priors into the noise during the reverse process. Specifically, we introduce an infrared thermal spectrum distribution regulation to preserve visual fidelity, ensuring that the reconstructed infrared images closely align with high-resolution images by matching their frequency components. Subsequently, we incorporate various visual foundational models as the perceptual guidance for downstream visual tasks, infusing generalizable perceptual features beneficial for detection and segmentation. As a result, our approach gains superior visual results while attaining State-Of-The-Art downstream task performance. Code is available at https://github.com/zirui0625/DifIISR
RoboDexVLM: Visual Language Model-Enabled Task Planning and Motion Control for Dexterous Robot Manipulation
Mar 03, 2025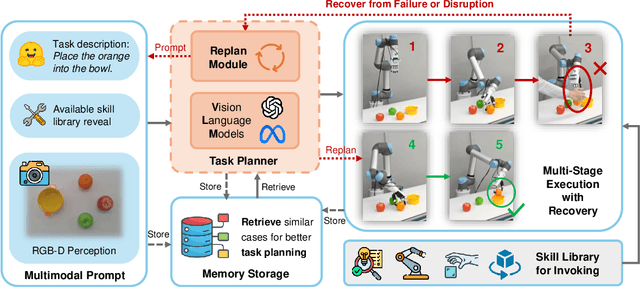
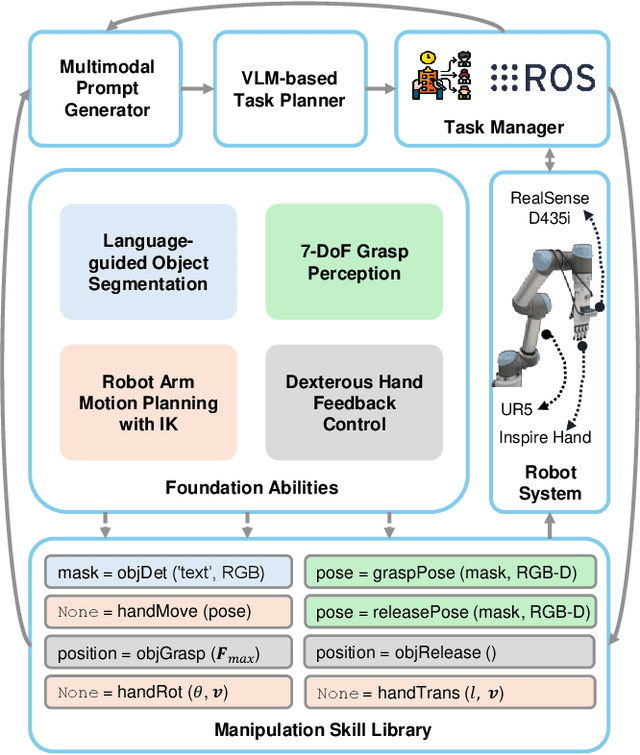
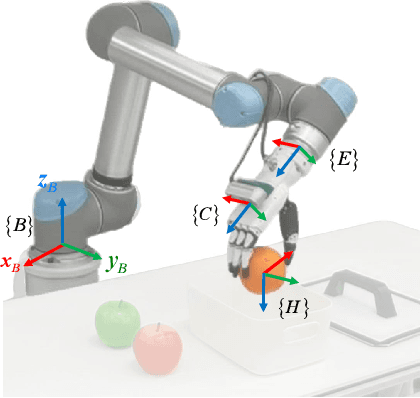

This paper introduces RoboDexVLM, an innovative framework for robot task planning and grasp detection tailored for a collaborative manipulator equipped with a dexterous hand. Previous methods focus on simplified and limited manipulation tasks, which often neglect the complexities associated with grasping a diverse array of objects in a long-horizon manner. In contrast, our proposed framework utilizes a dexterous hand capable of grasping objects of varying shapes and sizes while executing tasks based on natural language commands. The proposed approach has the following core components: First, a robust task planner with a task-level recovery mechanism that leverages vision-language models (VLMs) is designed, which enables the system to interpret and execute open-vocabulary commands for long sequence tasks. Second, a language-guided dexterous grasp perception algorithm is presented based on robot kinematics and formal methods, tailored for zero-shot dexterous manipulation with diverse objects and commands. Comprehensive experimental results validate the effectiveness, adaptability, and robustness of RoboDexVLM in handling long-horizon scenarios and performing dexterous grasping. These results highlight the framework's ability to operate in complex environments, showcasing its potential for open-vocabulary dexterous manipulation. Our open-source project page can be found at https://henryhcliu.github.io/robodexvlm.