 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniIntervene: Agentic Intervention for Efficient Real-World Reinforcement Learning
Jun 10, 2026Human-in-the-loop reinforcement learning (HiL-RL) has emerged as an effective paradigm for real-world robotic manipulation, enabling online policy improvement with human guidance. However, current HiL-RL frameworks remain intervention-intensive, relying on frequent human corrections to redirect the policy out of unproductive exploration, which incurs high labor cost and limits real-world scalability. To address this, we propose UniIntervene, an agentic intervention model that detects unproductive exploration and autonomously recovers the policy toward high-value states, taking over the bulk of interventions from human operators. Specifically, UniIntervene first performs future-conditioned action-value estimation, predicting the latent consequence of the current action and evaluating its induced value, which provides a more stable progress signal. Building on this, a temporal value-risk critic aggregates recent value dynamics and triggers intervention when the estimated value exhibits sustained stagnation or degradation. When intervention is required, UniIntervene retrieves a high-value recovery target from a memory of past intervention episodes and produces executable corrective actions through a goal-conditioned recovery policy. In this way, UniIntervene turns intervention from passive human correction into a value-aware recovery process for efficient real-world RL. Extensive experiments on diverse real-world manipulation tasks demonstrate that UniIntervene improves the average success rate by 8.6% while reducing human interventions by 57% relative to state-of-the-art HiL-RL baselines.
RoCo Challenge at AAAI 2026: Benchmarking Robotic Collaborative Manipulation for Assembly Towards Industrial Automation
Mar 16, 2026Embodied Artificial Intelligence (EAI) is rapidly developing, gradually subverting previous autonomous systems' paradigms from isolated perception to integrated, continuous action. This transition is highly significant for industrial robotic manipulation, promising to free human workers from repetitive, dangerous daily labor. To benchmark and advance this capability, we introduce the Robotic Collaborative Assembly Assistance (RoCo) Challenge with a dataset towards simulation and real-world assembly manipulation. Set against the backdrop of human-centered manufacturing, this challenge focuses on a high-precision planetary gearbox assembly task, a demanding yet highly representative operation in modern industry. Built upon a self-developed data collection, training, and evaluation system in Isaac Sim, and utilizing a dual-arm robot for real-world deployment, the challenge operates in two phases. The Simulation Round defines fine-grained task phases for step-wise scoring to handle the long-horizon nature of the assembly. The Real-World Round mirrors this evaluation with physical gearbox components and high-quality teleoperated datasets. The core tasks require assembling an epicyclic gearbox from scratch, including mounting three planet gears, a sun gear, and a ring gear. Attracting over 60 teams and 170+ participants from more than 10 countries, the challenge yielded highly effective solutions, most notably ARC-VLA and RoboCola. Results demonstrate that a dual-model framework for long-horizon multi-task learning is highly effective, and the strategic utilization of recovery-from-failure curriculum data is a critical insight for successful deployment. This report outlines the competition setup, evaluation approach, key findings, and future directions for industrial EAI. Our dataset, CAD files, code, and evaluation results can be found at: https://rocochallenge.github.io/RoCo2026/.
MoE-ACT: Scaling Multi-Task Bimanual Manipulation with Sparse Language-Conditioned Mixture-of-Experts Transformers
Mar 16, 2026The ability of robots to handle multiple tasks under a unified policy is critical for deploying embodied intelligence in real-world household and industrial applications. However, out-of-distribution variation across tasks often causes severe task interference and negative transfer when training general robotic policies. To address this challenge, we propose a lightweight multi-task imitation learning framework for bimanual manipulation, termed Mixture-of-Experts-Enhanced Action Chunking Transformer (MoE-ACT), which integrates sparse Mixture-of-Experts (MoE) modules into the Transformer encoder of ACT. The MoE layer decomposes a unified task policy into independently invoked expert components. Through adaptive activation, it naturally decouples multi-task action distributions in latent space. During decoding, Feature-wise Linear Modulation (FiLM) dynamically modulates action tokens to improve consistency between action generation and task instructions. In parallel, multi-scale cross-attention enables the policy to simultaneously focus on both low-level and high-level semantic features, providing rich visual information for robotic manipulation. We further incorporate textual information, transitioning the framework from a purely vision-based model to a vision-centric, language-conditioned action generation system. Experimental validation in both simulation and a real-world dual-arm setup shows that MoE-ACT substantially improves multi-task performance. Specifically, MoE-ACT outperforms vanilla ACT by an average of 33% in success rate. These results indicate that MoE-ACT provides stronger robustness and generalization in complex multi-task bimanual manipulation environments. Our open-source project page can be found at https://j3k7.github.io/MoE-ACT/.
SpecFuse: A Spectral-Temporal Fusion Predictive Control Framework for UAV Landing on Oscillating Marine Platforms
Feb 17, 2026Autonomous landing of Uncrewed Aerial Vehicles (UAVs) on oscillating marine platforms is severely constrained by wave-induced multi-frequency oscillations, wind disturbances, and prediction phase lags in motion prediction. Existing methods either treat platform motion as a general random process or lack explicit modeling of wave spectral characteristics, leading to suboptimal performance under dynamic sea conditions. To address these limitations, we propose SpecFuse: a novel spectral-temporal fusion predictive control framework that integrates frequency-domain wave decomposition with time-domain recursive state estimation for high-precision 6-DoF motion forecasting of Uncrewed Surface Vehicles (USVs). The framework explicitly models dominant wave harmonics to mitigate phase lags, refining predictions in real time via IMU data without relying on complex calibration. Additionally, we design a hierarchical control architecture featuring a sampling-based HPO-RRT* algorithm for dynamic trajectory planning under non-convex constraints and a learning-augmented predictive controller that fuses data-driven disturbance compensation with optimization-based execution. Extensive validations (2,000 simulations + 8 lake experiments) show our approach achieves a 3.2 cm prediction error, 4.46 cm landing deviation, 98.7% / 87.5% success rates (simulation / real-world), and 82 ms latency on embedded hardware, outperforming state-of-the-art methods by 44%-48% in accuracy. Its robustness to wave-wind coupling disturbances supports critical maritime missions such as search and rescue and environmental monitoring. All code, experimental configurations, and datasets will be released as open-source to facilitate reproducibility.
UniManip: General-Purpose Zero-Shot Robotic Manipulation with Agentic Operational Graph
Feb 13, 2026Achieving general-purpose robotic manipulation requires robots to seamlessly bridge high-level semantic intent with low-level physical interaction in unstructured environments. However, existing approaches falter in zero-shot generalization: end-to-end Vision-Language-Action (VLA) models often lack the precision required for long-horizon tasks, while traditional hierarchical planners suffer from semantic rigidity when facing open-world variations. To address this, we present UniManip, a framework grounded in a Bi-level Agentic Operational Graph (AOG) that unifies semantic reasoning and physical grounding. By coupling a high-level Agentic Layer for task orchestration with a low-level Scene Layer for dynamic state representation, the system continuously aligns abstract planning with geometric constraints, enabling robust zero-shot execution. Unlike static pipelines, UniManip operates as a dynamic agentic loop: it actively instantiates object-centric scene graphs from unstructured perception, parameterizes these representations into collision-free trajectories via a safety-aware local planner, and exploits structured memory to autonomously diagnose and recover from execution failures. Extensive experiments validate the system's robust zero-shot capability on unseen objects and tasks, demonstrating a 22.5% and 25.0% higher success rate compared to state-of-the-art VLA and hierarchical baselines, respectively. Notably, the system enables direct zero-shot transfer from fixed-base setups to mobile manipulation without fine-tuning or reconfiguration. Our open-source project page can be found at https://henryhcliu.github.io/unimanip.
An Intention-driven Lane Change Framework Considering Heterogeneous Dynamic Cooperation in Mixed-traffic Environment
Sep 26, 2025



In mixed-traffic environments, where autonomous vehicles (AVs) interact with diverse human-driven vehicles (HVs), unpredictable intentions and heterogeneous behaviors make safe and efficient lane change maneuvers highly challenging. Existing methods often oversimplify these interactions by assuming uniform patterns. We propose an intention-driven lane change framework that integrates driving-style recognition, cooperation-aware decision-making, and coordinated motion planning. A deep learning classifier trained on the NGSIM dataset identifies human driving styles in real time. A cooperation score with intrinsic and interactive components estimates surrounding drivers' intentions and quantifies their willingness to cooperate with the ego vehicle. Decision-making combines behavior cloning with inverse reinforcement learning to determine whether a lane change should be initiated. For trajectory generation, model predictive control is integrated with IRL-based intention inference to produce collision-free and socially compliant maneuvers. Experiments show that the proposed model achieves 94.2\% accuracy and 94.3\% F1-score, outperforming rule-based and learning-based baselines by 4-15\% in lane change recognition. These results highlight the benefit of modeling inter-driver heterogeneity and demonstrate the potential of the framework to advance context-aware and human-like autonomous driving in complex traffic environments.
RoboDexVLM: Visual Language Model-Enabled Task Planning and Motion Control for Dexterous Robot Manipulation
Mar 03, 2025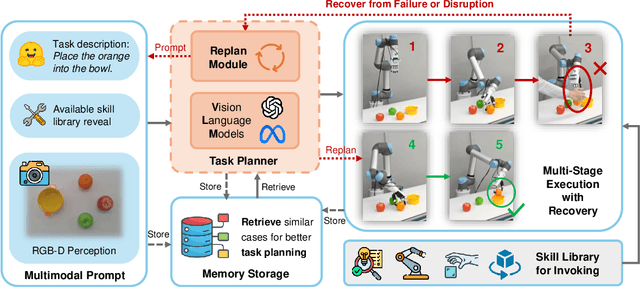
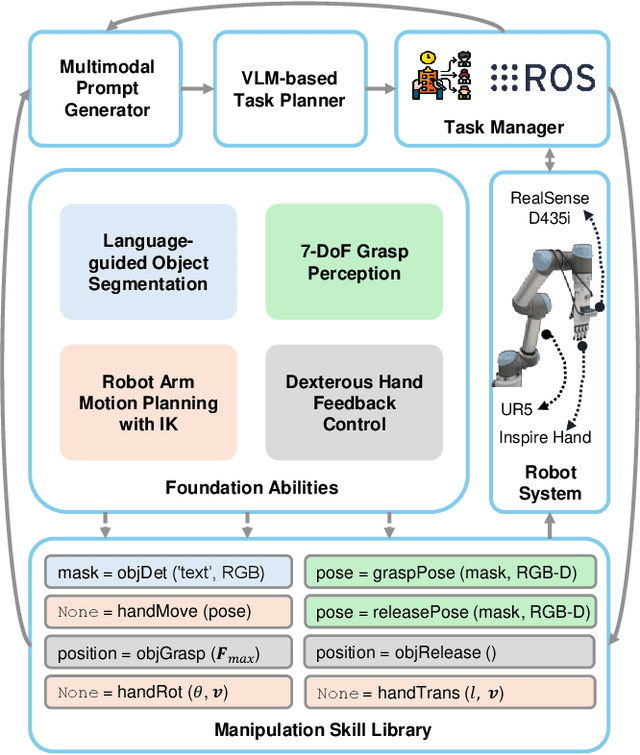
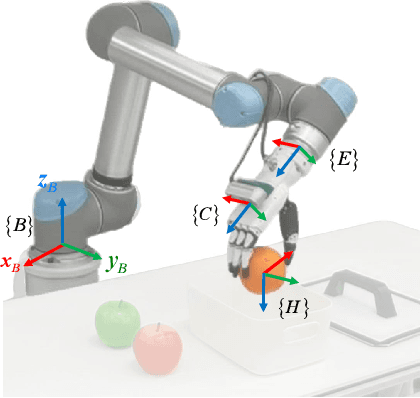

This paper introduces RoboDexVLM, an innovative framework for robot task planning and grasp detection tailored for a collaborative manipulator equipped with a dexterous hand. Previous methods focus on simplified and limited manipulation tasks, which often neglect the complexities associated with grasping a diverse array of objects in a long-horizon manner. In contrast, our proposed framework utilizes a dexterous hand capable of grasping objects of varying shapes and sizes while executing tasks based on natural language commands. The proposed approach has the following core components: First, a robust task planner with a task-level recovery mechanism that leverages vision-language models (VLMs) is designed, which enables the system to interpret and execute open-vocabulary commands for long sequence tasks. Second, a language-guided dexterous grasp perception algorithm is presented based on robot kinematics and formal methods, tailored for zero-shot dexterous manipulation with diverse objects and commands. Comprehensive experimental results validate the effectiveness, adaptability, and robustness of RoboDexVLM in handling long-horizon scenarios and performing dexterous grasping. These results highlight the framework's ability to operate in complex environments, showcasing its potential for open-vocabulary dexterous manipulation. Our open-source project page can be found at https://henryhcliu.github.io/robodexvlm.
VLM-E2E: Enhancing End-to-End Autonomous Driving with Multimodal Driver Attention Fusion
Feb 25, 2025



Human drivers adeptly navigate complex scenarios by utilizing rich attentional semantics, but the current autonomous systems struggle to replicate this ability, as they often lose critical semantic information when converting 2D observations into 3D space. In this sense, it hinders their effective deployment in dynamic and complex environments. Leveraging the superior scene understanding and reasoning abilities of Vision-Language Models (VLMs), we propose VLM-E2E, a novel framework that uses the VLMs to enhance training by providing attentional cues. Our method integrates textual representations into Bird's-Eye-View (BEV) features for semantic supervision, which enables the model to learn richer feature representations that explicitly capture the driver's attentional semantics. By focusing on attentional semantics, VLM-E2E better aligns with human-like driving behavior, which is critical for navigating dynamic and complex environments. Furthermore, we introduce a BEV-Text learnable weighted fusion strategy to address the issue of modality importance imbalance in fusing multimodal information. This approach dynamically balances the contributions of BEV and text features, ensuring that the complementary information from visual and textual modality is effectively utilized. By explicitly addressing the imbalance in multimodal fusion, our method facilitates a more holistic and robust representation of driving environments. We evaluate VLM-E2E on the nuScenes dataset and demonstrate its superiority over state-of-the-art approaches, showcasing significant improvements in performance.
CoDriveVLM: VLM-Enhanced Urban Cooperative Dispatching and Motion Planning for Future Autonomous Mobility on Demand Systems
Jan 10, 2025



The increasing demand for flexible and efficient urban transportation solutions has spotlighted the limitations of traditional Demand Responsive Transport (DRT) systems, particularly in accommodating diverse passenger needs and dynamic urban environments. Autonomous Mobility-on-Demand (AMoD) systems have emerged as a promising alternative, leveraging connected and autonomous vehicles (CAVs) to provide responsive and adaptable services. However, existing methods primarily focus on either vehicle scheduling or path planning, which often simplify complex urban layouts and neglect the necessity for simultaneous coordination and mutual avoidance among CAVs. This oversimplification poses significant challenges to the deployment of AMoD systems in real-world scenarios. To address these gaps, we propose CoDriveVLM, a novel framework that integrates high-fidelity simultaneous dispatching and cooperative motion planning for future AMoD systems. Our method harnesses Vision-Language Models (VLMs) to enhance multi-modality information processing, and this enables comprehensive dispatching and collision risk evaluation. The VLM-enhanced CAV dispatching coordinator is introduced to effectively manage complex and unforeseen AMoD conditions, thus supporting efficient scheduling decision-making. Furthermore, we propose a scalable decentralized cooperative motion planning method via consensus alternating direction method of multipliers (ADMM) focusing on collision risk evaluation and decentralized trajectory optimization. Simulation results demonstrate the feasibility and robustness of CoDriveVLM in various traffic conditions, showcasing its potential to significantly improve the fidelity and effectiveness of AMoD systems in future urban transportation networks. The code is available at https://github.com/henryhcliu/CoDriveVLM.git.
UDMC: Unified Decision-Making and Control Framework for Urban Autonomous Driving with Motion Prediction of Traffic Participants
Jan 05, 2025



Current autonomous driving systems often struggle to balance decision-making and motion control while ensuring safety and traffic rule compliance, especially in complex urban environments. Existing methods may fall short due to separate handling of these functionalities, leading to inefficiencies and safety compromises. To address these challenges, we introduce UDMC, an interpretable and unified Level 4 autonomous driving framework. UDMC integrates decision-making and motion control into a single optimal control problem (OCP), considering the dynamic interactions with surrounding vehicles, pedestrians, road lanes, and traffic signals. By employing innovative potential functions to model traffic participants and regulations, and incorporating a specialized motion prediction module, our framework enhances on-road safety and rule adherence. The integrated design allows for real-time execution of flexible maneuvers suited to diverse driving scenarios. High-fidelity simulations conducted in CARLA exemplify the framework's computational efficiency, robustness, and safety, resulting in superior driving performance when compared against various baseline models. Our open-source project is available at https://github.com/henryhcliu/udmc_carla.git.