 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAFNet: Dynamic Auxiliary Fusion for Sequential Model Editing in Large Language Models
May 31, 2024



Recently, while large language models (LLMs) have demonstrated impressive results, they still suffer from hallucination, i.e., the generation of false information. Model editing is the task of fixing factual mistakes in LLMs; yet, most previous works treat it as a one-time task, paying little attention to ever-emerging mistakes generated by LLMs. We address the task of sequential model editing (SME) that aims to rectify mistakes continuously. A Dynamic Auxiliary Fusion Network (DAFNet) is designed to enhance the semantic interaction among the factual knowledge within the entire sequence, preventing catastrophic forgetting during the editing process of multiple knowledge triples. Specifically, (1) for semantic fusion within a relation triple, we aggregate the intra-editing attention flow into auto-regressive self-attention with token-level granularity in LLMs. We further leverage multi-layer diagonal inter-editing attention flow to update the weighted representations of the entire sequence-level granularity. (2) Considering that auxiliary parameters are required to store the knowledge for sequential editing, we construct a new dataset named \textbf{DAFSet}, fulfilling recent, popular, long-tail and robust properties to enhance the generality of sequential editing. Experiments show DAFNet significantly outperforms strong baselines in single-turn and sequential editing. The usage of DAFSet also consistently improves the performance of other auxiliary network-based methods in various scenarios
EasyAnimate: A High-Performance Long Video Generation Method based on Transformer Architecture
May 29, 2024This paper presents EasyAnimate, an advanced method for video generation that leverages the power of transformer architecture for high-performance outcomes. We have expanded the DiT framework originally designed for 2D image synthesis to accommodate the complexities of 3D video generation by incorporating a motion module block. It is used to capture temporal dynamics, thereby ensuring the production of consistent frames and seamless motion transitions. The motion module can be adapted to various DiT baseline methods to generate video with different styles. It can also generate videos with different frame rates and resolutions during both training and inference phases, suitable for both images and videos. Moreover, we introduce slice VAE, a novel approach to condense the temporal axis, facilitating the generation of long duration videos. Currently, EasyAnimate exhibits the proficiency to generate videos with 144 frames. We provide a holistic ecosystem for video production based on DiT, encompassing aspects such as data pre-processing, VAE training, DiT models training (both the baseline model and LoRA model), and end-to-end video inference. Code is available at: https://github.com/aigc-apps/EasyAnimate. We are continuously working to enhance the performance of our method.
Distilling Instruction-following Abilities of Large Language Models with Task-aware Curriculum Planning
May 22, 2024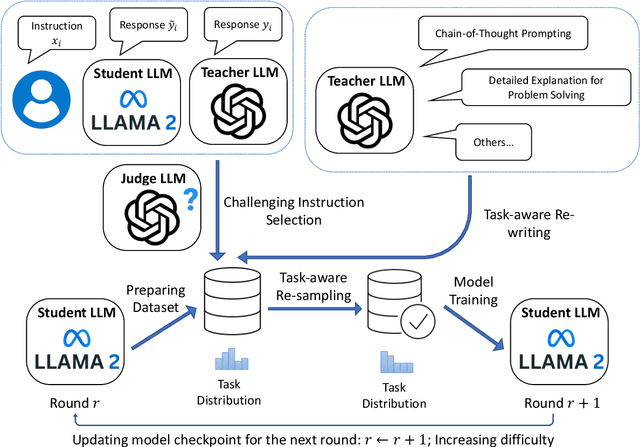

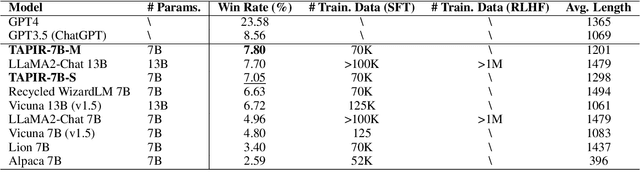
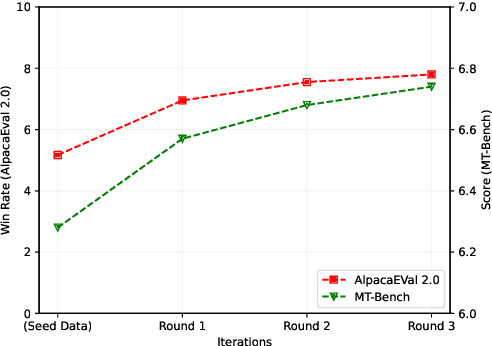
The process of instruction tuning aligns pre-trained large language models (LLMs) with open-domain instructions and human-preferred responses. While several studies have explored autonomous approaches to distilling and annotating instructions from more powerful proprietary LLMs, such as ChatGPT, they often neglect the impact of task distributions and the varying difficulty of instructions of the training sets. This oversight can lead to imbalanced knowledge capabilities and poor generalization powers of small student LLMs. To address this challenge, we introduce Task-Aware Curriculum Planning for Instruction Refinement (TAPIR), a multi-round distillation framework with balanced task distributions and dynamic difficulty adjustment. This approach utilizes an oracle LLM to select instructions that are difficult for a student LLM to follow and distill instructions with balanced task distributions. By incorporating curriculum planning, our approach systematically escalates the difficulty levels, progressively enhancing the student LLM's capabilities. We rigorously evaluate TAPIR using two widely recognized benchmarks, including AlpacaEval 2.0 and MT-Bench. The empirical results demonstrate that the student LLMs, trained with our method and less training data, outperform larger instruction-tuned models and strong distillation baselines. The improvement is particularly notable in complex tasks, such as logical reasoning and code generation.
Exploring Graph-based Knowledge: Multi-Level Feature Distillation via Channels Relational Graph
May 16, 2024



In visual tasks, large teacher models capture essential features and deep information, enhancing performance. However, distilling this information into smaller student models often leads to performance loss due to structural differences and capacity limitations. To tackle this, we propose a distillation framework based on graph knowledge, including a multi-level feature alignment strategy and an attention-guided mechanism to provide a targeted learning trajectory for the student model. We emphasize spectral embedding (SE) as a key technique in our distillation process, which merges the student's feature space with the relational knowledge and structural complexities similar to the teacher network. This method captures the teacher's understanding in a graph-based representation, enabling the student model to more accurately mimic the complex structural dependencies present in the teacher model. Compared to methods that focus only on specific distillation areas, our strategy not only considers key features within the teacher model but also endeavors to capture the relationships and interactions among feature sets, encoding these complex pieces of information into a graph structure to understand and utilize the dynamic relationships among these pieces of information from a global perspective. Experiments show that our method outperforms previous feature distillation methods on the CIFAR-100, MS-COCO, and Pascal VOC datasets, proving its efficiency and applicability.
R4: Reinforced Retriever-Reorder-Responder for Retrieval-Augmented Large Language Models
May 04, 2024Retrieval-augmented large language models (LLMs) leverage relevant content retrieved by information retrieval systems to generate correct responses, aiming to alleviate the hallucination problem. However, existing retriever-responder methods typically append relevant documents to the prompt of LLMs to perform text generation tasks without considering the interaction of fine-grained structural semantics between the retrieved documents and the LLMs. This issue is particularly important for accurate response generation as LLMs tend to ``lose in the middle'' when dealing with input prompts augmented with lengthy documents. In this work, we propose a new pipeline named ``Reinforced Retriever-Reorder-Responder'' (R$^4$) to learn document orderings for retrieval-augmented LLMs, thereby further enhancing their generation abilities while the large numbers of parameters of LLMs remain frozen. The reordering learning process is divided into two steps according to the quality of the generated responses: document order adjustment and document representation enhancement. Specifically, document order adjustment aims to organize retrieved document orderings into beginning, middle, and end positions based on graph attention learning, which maximizes the reinforced reward of response quality. Document representation enhancement further refines the representations of retrieved documents for responses of poor quality via document-level gradient adversarial learning. Extensive experiments demonstrate that our proposed pipeline achieves better factual question-answering performance on knowledge-intensive tasks compared to strong baselines across various public datasets. The source codes and trained models will be released upon paper acceptance.
Guided AbsoluteGrad: Magnitude of Gradients Matters to Explanation's Localization and Saliency
Apr 23, 2024This paper proposes a new gradient-based XAI method called Guided AbsoluteGrad for saliency map explanations. We utilize both positive and negative gradient magnitudes and employ gradient variance to distinguish the important areas for noise deduction. We also introduce a novel evaluation metric named ReCover And Predict (RCAP), which considers the Localization and Visual Noise Level objectives of the explanations. We propose two propositions for these two objectives and prove the necessity of evaluating them. We evaluate Guided AbsoluteGrad with seven gradient-based XAI methods using the RCAP metric and other SOTA metrics in three case studies: (1) ImageNet dataset with ResNet50 model; (2) International Skin Imaging Collaboration (ISIC) dataset with EfficientNet model; (3) the Places365 dataset with DenseNet161 model. Our method surpasses other gradient-based approaches, showcasing the quality of enhanced saliency map explanations through gradient magnitude.
AlphaFin: Benchmarking Financial Analysis with Retrieval-Augmented Stock-Chain Framework
Mar 19, 2024



The task of financial analysis primarily encompasses two key areas: stock trend prediction and the corresponding financial question answering. Currently, machine learning and deep learning algorithms (ML&DL) have been widely applied for stock trend predictions, leading to significant progress. However, these methods fail to provide reasons for predictions, lacking interpretability and reasoning processes. Also, they can not integrate textual information such as financial news or reports. Meanwhile, large language models (LLMs) have remarkable textual understanding and generation ability. But due to the scarcity of financial training datasets and limited integration with real-time knowledge, LLMs still suffer from hallucinations and are unable to keep up with the latest information. To tackle these challenges, we first release AlphaFin datasets, combining traditional research datasets, real-time financial data, and handwritten chain-of-thought (CoT) data. It has a positive impact on training LLMs for completing financial analysis. We then use AlphaFin datasets to benchmark a state-of-the-art method, called Stock-Chain, for effectively tackling the financial analysis task, which integrates retrieval-augmented generation (RAG) techniques. Extensive experiments are conducted to demonstrate the effectiveness of our framework on financial analysis.
TRELM: Towards Robust and Efficient Pre-training for Knowledge-Enhanced Language Models
Mar 17, 2024



KEPLMs are pre-trained models that utilize external knowledge to enhance language understanding. Previous language models facilitated knowledge acquisition by incorporating knowledge-related pre-training tasks learned from relation triples in knowledge graphs. However, these models do not prioritize learning embeddings for entity-related tokens. Moreover, updating the entire set of parameters in KEPLMs is computationally demanding. This paper introduces TRELM, a Robust and Efficient Pre-training framework for Knowledge-Enhanced Language Models. We observe that entities in text corpora usually follow the long-tail distribution, where the representations of some entities are suboptimally optimized and hinder the pre-training process for KEPLMs. To tackle this, we employ a robust approach to inject knowledge triples and employ a knowledge-augmented memory bank to capture valuable information. Furthermore, updating a small subset of neurons in the feed-forward networks (FFNs) that store factual knowledge is both sufficient and efficient. Specifically, we utilize dynamic knowledge routing to identify knowledge paths in FFNs and selectively update parameters during pre-training. Experimental results show that TRELM reduces pre-training time by at least 50% and outperforms other KEPLMs in knowledge probing tasks and multiple knowledge-aware language understanding tasks.
DiffChat: Learning to Chat with Text-to-Image Synthesis Models for Interactive Image Creation
Mar 08, 2024



We present DiffChat, a novel method to align Large Language Models (LLMs) to "chat" with prompt-as-input Text-to-Image Synthesis (TIS) models (e.g., Stable Diffusion) for interactive image creation. Given a raw prompt/image and a user-specified instruction, DiffChat can effectively make appropriate modifications and generate the target prompt, which can be leveraged to create the target image of high quality. To achieve this, we first collect an instruction-following prompt engineering dataset named InstructPE for the supervised training of DiffChat. Next, we propose a reinforcement learning framework with the feedback of three core criteria for image creation, i.e., aesthetics, user preference, and content integrity. It involves an action-space dynamic modification technique to obtain more relevant positive samples and harder negative samples during the off-policy sampling. Content integrity is also introduced into the value estimation function for further improvement of produced images. Our method can exhibit superior performance than baseline models and strong competitors based on both automatic and human evaluations, which fully demonstrates its effectiveness.
Towards Understanding Cross and Self-Attention in Stable Diffusion for Text-Guided Image Editing
Mar 06, 2024



Deep Text-to-Image Synthesis (TIS) models such as Stable Diffusion have recently gained significant popularity for creative Text-to-image generation. Yet, for domain-specific scenarios, tuning-free Text-guided Image Editing (TIE) is of greater importance for application developers, which modify objects or object properties in images by manipulating feature components in attention layers during the generation process. However, little is known about what semantic meanings these attention layers have learned and which parts of the attention maps contribute to the success of image editing. In this paper, we conduct an in-depth probing analysis and demonstrate that cross-attention maps in Stable Diffusion often contain object attribution information that can result in editing failures. In contrast, self-attention maps play a crucial role in preserving the geometric and shape details of the source image during the transformation to the target image. Our analysis offers valuable insights into understanding cross and self-attention maps in diffusion models. Moreover, based on our findings, we simplify popular image editing methods and propose a more straightforward yet more stable and efficient tuning-free procedure that only modifies self-attention maps of the specified attention layers during the denoising process. Experimental results show that our simplified method consistently surpasses the performance of popular approaches on multiple datasets.