 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward-SQL: Boosting Text-to-SQL via Stepwise Reasoning and Process-Supervised Rewards
Paper and Code
May 07, 2025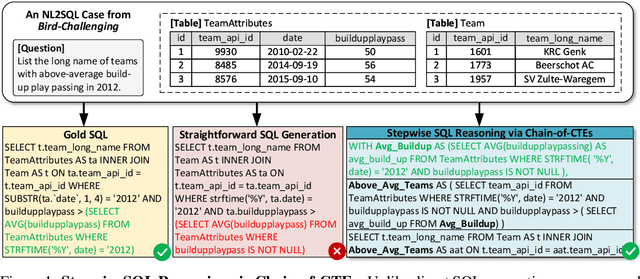
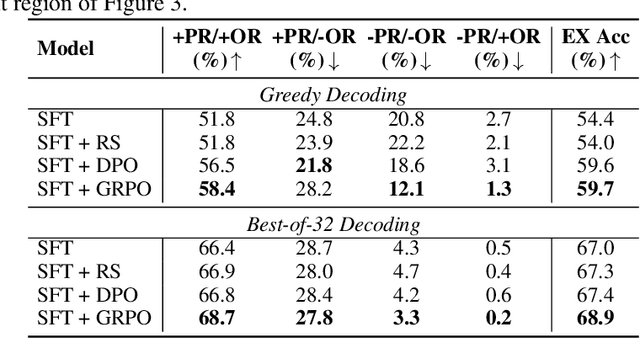
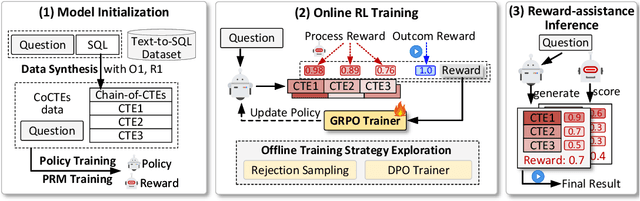
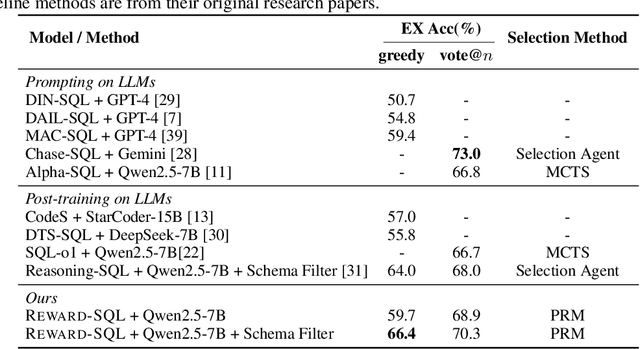
Recent advances in large language models (LLMs) have significantly improved performance on the Text-to-SQL task by leveraging their powerful reasoning capabilities. To enhance accuracy during the reasoning process, external Process Reward Models (PRMs) can be introduced during training and inference to provide fine-grained supervision. However, if misused, PRMs may distort the reasoning trajectory and lead to suboptimal or incorrect SQL generation.To address this challenge, we propose Reward-SQL, a framework that systematically explores how to incorporate PRMs into the Text-to-SQL reasoning process effectively. Our approach follows a "cold start, then PRM supervision" paradigm. Specifically, we first train the model to decompose SQL queries into structured stepwise reasoning chains using common table expressions (Chain-of-CTEs), establishing a strong and interpretable reasoning baseline. Then, we investigate four strategies for integrating PRMs, and find that combining PRM as an online training signal (GRPO) with PRM-guided inference (e.g., best-of-N sampling) yields the best results. Empirically, on the BIRD benchmark, Reward-SQL enables models supervised by a 7B PRM to achieve a 13.1% performance gain across various guidance strategies. Notably, our GRPO-aligned policy model based on Qwen2.5-Coder-7B-Instruct achieves 68.9% accuracy on the BIRD development set, outperforming all baseline methods under the same model size. These results demonstrate the effectiveness of Reward-SQL in leveraging reward-based supervision for Text-to-SQL reasoning. Our code is publicly available.