 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Autonomous Navigation and Locomotion for Wheeled-Legged Robots
May 03, 2024Autonomous wheeled-legged robots have the potential to transform logistics systems, improving operational efficiency and adaptability in urban environments. Navigating urban environments, however, poses unique challenges for robots, necessitating innovative solutions for locomotion and navigation. These challenges include the need for adaptive locomotion across varied terrains and the ability to navigate efficiently around complex dynamic obstacles. This work introduces a fully integrated system comprising adaptive locomotion control, mobility-aware local navigation planning, and large-scale path planning within the city. Using model-free reinforcement learning (RL) techniques and privileged learning, we develop a versatile locomotion controller. This controller achieves efficient and robust locomotion over various rough terrains, facilitated by smooth transitions between walking and driving modes. It is tightly integrated with a learned navigation controller through a hierarchical RL framework, enabling effective navigation through challenging terrain and various obstacles at high speed. Our controllers are integrated into a large-scale urban navigation system and validated by autonomous, kilometer-scale navigation missions conducted in Zurich, Switzerland, and Seville, Spain. These missions demonstrate the system's robustness and adaptability, underscoring the importance of integrated control systems in achieving seamless navigation in complex environments. Our findings support the feasibility of wheeled-legged robots and hierarchical RL for autonomous navigation, with implications for last-mile delivery and beyond.
Evaluation of Constrained Reinforcement Learning Algorithms for Legged Locomotion
Sep 27, 2023



Shifting from traditional control strategies to Deep Reinforcement Learning (RL) for legged robots poses inherent challenges, especially when addressing real-world physical constraints during training. While high-fidelity simulations provide significant benefits, they often bypass these essential physical limitations. In this paper, we experiment with the Constrained Markov Decision Process (CMDP) framework instead of the conventional unconstrained RL for robotic applications. We perform a comparative study of different constrained policy optimization algorithms to identify suitable methods for practical implementation. Our robot experiments demonstrate the critical role of incorporating physical constraints, yielding successful sim-to-real transfers, and reducing operational errors on physical systems. The CMDP formulation streamlines the training process by separately handling constraints from rewards. Our findings underscore the potential of constrained RL for the effective development and deployment of learned controllers in robotics.
Imitation Learning from MPC for Quadrupedal Multi-Gait Control
Mar 26, 2021
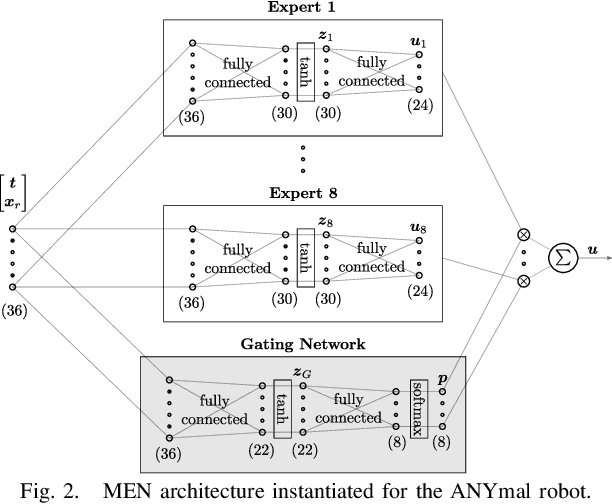
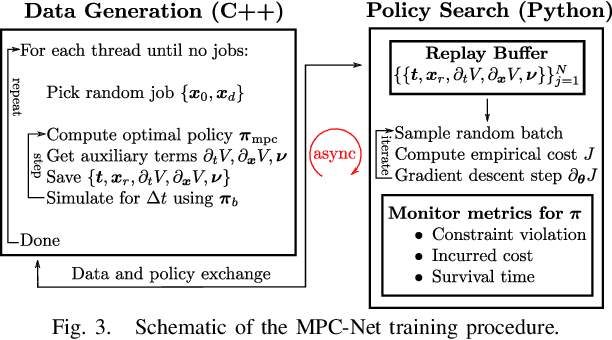
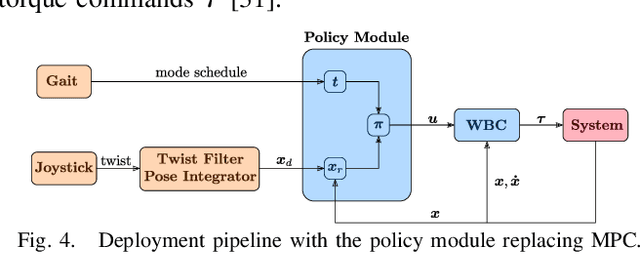
We present a learning algorithm for training a single policy that imitates multiple gaits of a walking robot. To achieve this, we use and extend MPC-Net, which is an Imitation Learning approach guided by Model Predictive Control (MPC). The strategy of MPC-Net differs from many other approaches since its objective is to minimize the control Hamiltonian, which derives from the principle of optimality. To represent the policies, we employ a mixture-of-experts network (MEN) and observe that the performance of a policy improves if each expert of a MEN specializes in controlling exactly one mode of a hybrid system, such as a walking robot. We introduce new loss functions for single- and multi-gait policies to achieve this kind of expert selection behavior. Moreover, we benchmark our algorithm against Behavioral Cloning and the original MPC implementation on various rough terrain scenarios. We validate our approach on hardware and show that a single learned policy can replace its teacher to control multiple gaits.