 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCAU-Net: Differential Cross Attention and Channel-Spatial Feature Fusion for Medical Image Segmentation
Mar 10, 2026Accurate medical image segmentation requires effective modeling of both long-range dependencies and fine-grained boundary details. While transformers mitigate the issue of insufficient semantic information arising from the limited receptive field inherent in convolutional neural networks, they introduce new challenges: standard self-attention incurs quadratic computational complexity and often assigns non-negligible attention weights to irrelevant regions, diluting focus on discriminative structures and ultimately compromising segmentation accuracy. Existing attention variants, although effective in reducing computational complexity, fail to suppress redundant computation and inadvertently impair global context modeling. Furthermore, conventional fusion strategies in encoder-decoder architectures, typically based on simple concatenation or summation, can not adaptively integrate high-level semantic information with low-level spatial details. To address these limitations, we propose DCAU-Net, a novel yet efficient segmentation framework with two key ideas. First, a new Differential Cross Attention (DCA) is designed to compute the difference between two independent softmax attention maps to adaptively highlight discriminative structures. By replacing pixel-wise key and value tokens with window-level summary tokens, DCA dramatically reduces computational complexity without sacrificing precision. Second, a Channel-Spatial Feature Fusion (CSFF) strategy is introduced to adaptively recalibrate features from skip connections and up-sampling paths through using sequential channel and spatial attention, effectively suppressing redundant information and amplifying salient cues. Experiments on two public benchmarks demonstrate that DCAU-Net achieves competitive performance with enhanced segmentation accuracy and robustness.
TAP-SLF: Parameter-Efficient Adaptation of Vision Foundation Models for Multi-Task Ultrasound Image Analysis
Feb 28, 2026Executing multiple tasks simultaneously in medical image analysis, including segmentation, classification, detection, and regression, often introduces significant challenges regarding model generalizability and the optimization of shared feature representations. While Vision Foundation Models (VFMs) provide powerful general representations, full fine-tuning on limited medical data is prone to overfitting and incurs high computational costs. Moreover, existing parameter-efficient fine-tuning approaches typically adopt task-agnostic adaptation protocols, overlooking both task-specific mechanisms and the varying sensitivity of model layers during fine-tuning. In this work, we propose Task-Aware Prompting and Selective Layer Fine-Tuning (TAP-SLF), a unified framework for multi-task ultrasound image analysis. TAP-SLF incorporates task-aware soft prompts to encode task-specific priors into the input token sequence and applies LoRA to selected specific top layers of the encoder. This strategy updates only a small fraction of the VFM parameters while keeping the pre-trained backbone frozen. By combining task-aware prompts with selective high-layer fine-tuning, TAP-SLF enables efficient VFM adaptation to diverse medical tasks within a shared backbone. Results on the FMC_UIA 2026 Challenge test set, where TAP-SLF wins fifth place, combined with evaluations on the officially released training dataset using an 8:2 train-test split, demonstrate that task-aware prompting and selective layer tuning are effective strategies for efficient VFM adaptation.
Beyond Benchmarks of IUGC: Rethinking Requirements of Deep Learning Methods for Intrapartum Ultrasound Biometry from Fetal Ultrasound Videos
Feb 13, 2026A substantial proportion (45\%) of maternal deaths, neonatal deaths, and stillbirths occur during the intrapartum phase, with a particularly high burden in low- and middle-income countries. Intrapartum biometry plays a critical role in monitoring labor progression; however, the routine use of ultrasound in resource-limited settings is hindered by a shortage of trained sonographers. To address this challenge, the Intrapartum Ultrasound Grand Challenge (IUGC), co-hosted with MICCAI 2024, was launched. The IUGC introduces a clinically oriented multi-task automatic measurement framework that integrates standard plane classification, fetal head-pubic symphysis segmentation, and biometry, enabling algorithms to exploit complementary task information for more accurate estimation. Furthermore, the challenge releases the largest multi-center intrapartum ultrasound video dataset to date, comprising 774 videos (68,106 frames) collected from three hospitals, providing a robust foundation for model training and evaluation. In this study, we present a comprehensive overview of the challenge design, review the submissions from eight participating teams, and analyze their methods from five perspectives: preprocessing, data augmentation, learning strategy, model architecture, and post-processing. In addition, we perform a systematic analysis of the benchmark results to identify key bottlenecks, explore potential solutions, and highlight open challenges for future research. Although encouraging performance has been achieved, our findings indicate that the field remains at an early stage, and further in-depth investigation is required before large-scale clinical deployment. All benchmark solutions and the complete dataset have been publicly released to facilitate reproducible research and promote continued advances in automatic intrapartum ultrasound biometry.
TCSAFormer: Efficient Vision Transformer with Token Compression and Sparse Attention for Medical Image Segmentation
Aug 06, 2025In recent years, transformer-based methods have achieved remarkable progress in medical image segmentation due to their superior ability to capture long-range dependencies. However, these methods typically suffer from two major limitations. First, their computational complexity scales quadratically with the input sequences. Second, the feed-forward network (FFN) modules in vanilla Transformers typically rely on fully connected layers, which limits models' ability to capture local contextual information and multiscale features critical for precise semantic segmentation. To address these issues, we propose an efficient medical image segmentation network, named TCSAFormer. The proposed TCSAFormer adopts two key ideas. First, it incorporates a Compressed Attention (CA) module, which combines token compression and pixel-level sparse attention to dynamically focus on the most relevant key-value pairs for each query. This is achieved by pruning globally irrelevant tokens and merging redundant ones, significantly reducing computational complexity while enhancing the model's ability to capture relationships between tokens. Second, it introduces a Dual-Branch Feed-Forward Network (DBFFN) module as a replacement for the standard FFN to capture local contextual features and multiscale information, thereby strengthening the model's feature representation capability. We conduct extensive experiments on three publicly available medical image segmentation datasets: ISIC-2018, CVC-ClinicDB, and Synapse, to evaluate the segmentation performance of TCSAFormer. Experimental results demonstrate that TCSAFormer achieves superior performance compared to existing state-of-the-art (SOTA) methods, while maintaining lower computational overhead, thus achieving an optimal trade-off between efficiency and accuracy.
MedFormer: Hierarchical Medical Vision Transformer with Content-Aware Dual Sparse Selection Attention
Jul 03, 2025Medical image recognition serves as a key way to aid in clinical diagnosis, enabling more accurate and timely identification of diseases and abnormalities. Vision transformer-based approaches have proven effective in handling various medical recognition tasks. However, these methods encounter two primary challenges. First, they are often task-specific and architecture-tailored, limiting their general applicability. Second, they usually either adopt full attention to model long-range dependencies, resulting in high computational costs, or rely on handcrafted sparse attention, potentially leading to suboptimal performance. To tackle these issues, we present MedFormer, an efficient medical vision transformer with two key ideas. First, it employs a pyramid scaling structure as a versatile backbone for various medical image recognition tasks, including image classification and dense prediction tasks such as semantic segmentation and lesion detection. This structure facilitates hierarchical feature representation while reducing the computation load of feature maps, highly beneficial for boosting performance. Second, it introduces a novel Dual Sparse Selection Attention (DSSA) with content awareness to improve computational efficiency and robustness against noise while maintaining high performance. As the core building technique of MedFormer, DSSA is explicitly designed to attend to the most relevant content. In addition, a detailed theoretical analysis has been conducted, demonstrating that MedFormer has superior generality and efficiency in comparison to existing medical vision transformers. Extensive experiments on a variety of imaging modality datasets consistently show that MedFormer is highly effective in enhancing performance across all three above-mentioned medical image recognition tasks. The code is available at https://github.com/XiaZunhui/MedFormer.
DMAF-Net: An Effective Modality Rebalancing Framework for Incomplete Multi-Modal Medical Image Segmentation
Jun 13, 2025Incomplete multi-modal medical image segmentation faces critical challenges from modality imbalance, including imbalanced modality missing rates and heterogeneous modality contributions. Due to their reliance on idealized assumptions of complete modality availability, existing methods fail to dynamically balance contributions and neglect the structural relationships between modalities, resulting in suboptimal performance in real-world clinical scenarios. To address these limitations, we propose a novel model, named Dynamic Modality-Aware Fusion Network (DMAF-Net). The DMAF-Net adopts three key ideas. First, it introduces a Dynamic Modality-Aware Fusion (DMAF) module to suppress missing-modality interference by combining transformer attention with adaptive masking and weight modality contributions dynamically through attention maps. Second, it designs a synergistic Relation Distillation and Prototype Distillation framework to enforce global-local feature alignment via covariance consistency and masked graph attention, while ensuring semantic consistency through cross-modal class-specific prototype alignment. Third, it presents a Dynamic Training Monitoring (DTM) strategy to stabilize optimization under imbalanced missing rates by tracking distillation gaps in real-time, and to balance convergence speeds across modalities by adaptively reweighting losses and scaling gradients. Extensive experiments on BraTS2020 and MyoPS2020 demonstrate that DMAF-Net outperforms existing methods for incomplete multi-modal medical image segmentation. Extensive experiments on BraTS2020 and MyoPS2020 demonstrate that DMAF-Net outperforms existing methods for incomplete multi-modal medical image segmentation. Our code is available at https://github.com/violet-42/DMAF-Net.
Cross-Modal Clustering-Guided Negative Sampling for Self-Supervised Joint Learning from Medical Images and Reports
Jun 13, 2025Learning medical visual representations directly from paired images and reports through multimodal self-supervised learning has emerged as a novel and efficient approach to digital diagnosis in recent years. However, existing models suffer from several severe limitations. 1) neglecting the selection of negative samples, resulting in the scarcity of hard negatives and the inclusion of false negatives; 2) focusing on global feature extraction, but overlooking the fine-grained local details that are crucial for medical image recognition tasks; and 3) contrastive learning primarily targets high-level features but ignoring low-level details which are essential for accurate medical analysis. Motivated by these critical issues, this paper presents a Cross-Modal Cluster-Guided Negative Sampling (CM-CGNS) method with two-fold ideas. First, it extends the k-means clustering used for local text features in the single-modal domain to the multimodal domain through cross-modal attention. This improvement increases the number of negative samples and boosts the model representation capability. Second, it introduces a Cross-Modal Masked Image Reconstruction (CM-MIR) module that leverages local text-to-image features obtained via cross-modal attention to reconstruct masked local image regions. This module significantly strengthens the model's cross-modal information interaction capabilities and retains low-level image features essential for downstream tasks. By well handling the aforementioned limitations, the proposed CM-CGNS can learn effective and robust medical visual representations suitable for various recognition tasks. Extensive experimental results on classification, detection, and segmentation tasks across five downstream datasets show that our method outperforms state-of-the-art approaches on multiple metrics, verifying its superior performance.
MSLAU-Net: A Hybird CNN-Transformer Network for Medical Image Segmentation
May 24, 2025

Both CNN-based and Transformer-based methods have achieved remarkable success in medical image segmentation tasks. However, CNN-based methods struggle to effectively capture global contextual information due to the inherent limitations of convolution operations. Meanwhile, Transformer-based methods suffer from insufficient local feature modeling and face challenges related to the high computational complexity caused by the self-attention mechanism. To address these limitations, we propose a novel hybrid CNN-Transformer architecture, named MSLAU-Net, which integrates the strengths of both paradigms. The proposed MSLAU-Net incorporates two key ideas. First, it introduces Multi-Scale Linear Attention, designed to efficiently extract multi-scale features from medical images while modeling long-range dependencies with low computational complexity. Second, it adopts a top-down feature aggregation mechanism, which performs multi-level feature aggregation and restores spatial resolution using a lightweight structure. Extensive experiments conducted on benchmark datasets covering three imaging modalities demonstrate that the proposed MSLAU-Net outperforms other state-of-the-art methods on nearly all evaluation metrics, validating the superiority, effectiveness, and robustness of our approach. Our code is available at https://github.com/Monsoon49/MSLAU-Net.
KPIs 2024 Challenge: Advancing Glomerular Segmentation from Patch- to Slide-Level
Feb 11, 2025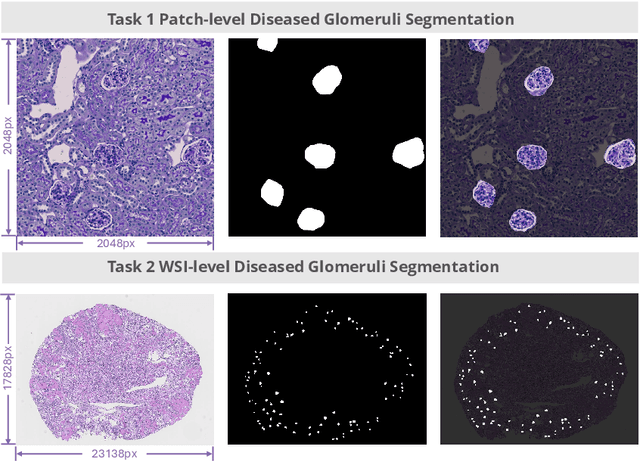

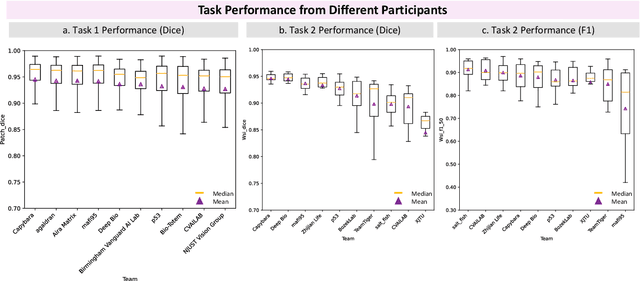

Chronic kidney disease (CKD) is a major global health issue, affecting over 10% of the population and causing significant mortality. While kidney biopsy remains the gold standard for CKD diagnosis and treatment, the lack of comprehensive benchmarks for kidney pathology segmentation hinders progress in the field. To address this, we organized the Kidney Pathology Image Segmentation (KPIs) Challenge, introducing a dataset that incorporates preclinical rodent models of CKD with over 10,000 annotated glomeruli from 60+ Periodic Acid Schiff (PAS)-stained whole slide images. The challenge includes two tasks, patch-level segmentation and whole slide image segmentation and detection, evaluated using the Dice Similarity Coefficient (DSC) and F1-score. By encouraging innovative segmentation methods that adapt to diverse CKD models and tissue conditions, the KPIs Challenge aims to advance kidney pathology analysis, establish new benchmarks, and enable precise, large-scale quantification for disease research and diagnosis.
FullTransNet: Full Transformer with Local-Global Attention for Video Summarization
Jan 01, 2025Video summarization mainly aims to produce a compact, short, informative, and representative synopsis of raw videos, which is of great importance for browsing, analyzing, and understanding video content. Dominant video summarization approaches are generally based on recurrent or convolutional neural networks, even recent encoder-only transformers. We propose using full transformer as an alternative architecture to perform video summarization. The full transformer with an encoder-decoder structure, specifically designed for handling sequence transduction problems, is naturally suitable for video summarization tasks. This work considers supervised video summarization and casts it as a sequence-to-sequence learning problem. Our key idea is to directly apply the full transformer to the video summarization task, which is intuitively sound and effective. Also, considering the efficiency problem, we replace full attention with the combination of local and global sparse attention, which enables modeling long-range dependencies while reducing computational costs. Based on this, we propose a transformer-like architecture, named FullTransNet, which has a full encoder-decoder structure with local-global sparse attention for video summarization. Specifically, both the encoder and decoder in FullTransNet are stacked the same way as ones in the vanilla transformer, and the local-global sparse attention is used only at the encoder side. Extensive experiments on two public multimedia benchmark datasets SumMe and TVSum demonstrate that our proposed model can outperform other video summarization approaches, achieving F-Measures of 54.4% on SumMe and 63.9% on TVSum with relatively lower compute and memory requirements, verifying its effectiveness and efficiency. The code and models are publicly available on GitHub.