 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-based Planning with Learned Viability Filters
Feb 26, 2025Diffusion models can be used as a motion planner by sampling from a distribution of possible futures. However, the samples may not satisfy hard constraints that exist only implicitly in the training data, e.g., avoiding falls or not colliding with a wall. We propose learned viability filters that efficiently predict the future success of any given plan, i.e., diffusion sample, and thereby enforce an implicit future-success constraint. Multiple viability filters can also be composed together. We demonstrate the approach on detailed footstep planning for challenging 3D human locomotion tasks, showing the effectiveness of viability filters in performing online planning and control for box-climbing, step-over walls, and obstacle avoidance. We further show that using viability filters is significantly faster than guidance-based diffusion prediction.
CLoSD: Closing the Loop between Simulation and Diffusion for multi-task character control
Oct 04, 2024



Motion diffusion models and Reinforcement Learning (RL) based control for physics-based simulations have complementary strengths for human motion generation. The former is capable of generating a wide variety of motions, adhering to intuitive control such as text, while the latter offers physically plausible motion and direct interaction with the environment. In this work, we present a method that combines their respective strengths. CLoSD is a text-driven RL physics-based controller, guided by diffusion generation for various tasks. Our key insight is that motion diffusion can serve as an on-the-fly universal planner for a robust RL controller. To this end, CLoSD maintains a closed-loop interaction between two modules -- a Diffusion Planner (DiP), and a tracking controller. DiP is a fast-responding autoregressive diffusion model, controlled by textual prompts and target locations, and the controller is a simple and robust motion imitator that continuously receives motion plans from DiP and provides feedback from the environment. CLoSD is capable of seamlessly performing a sequence of different tasks, including navigation to a goal location, striking an object with a hand or foot as specified in a text prompt, sitting down, and getting up. https://guytevet.github.io/CLoSD-page/
Learning-based legged locomotion; state of the art and future perspectives
Jun 03, 2024Legged locomotion holds the premise of universal mobility, a critical capability for many real-world robotic applications. Both model-based and learning-based approaches have advanced the field of legged locomotion in the past three decades. In recent years, however, a number of factors have dramatically accelerated progress in learning-based methods, including the rise of deep learning, rapid progress in simulating robotic systems, and the availability of high-performance and affordable hardware. This article aims to give a brief history of the field, to summarize recent efforts in learning locomotion skills for quadrupeds, and to provide researchers new to the area with an understanding of the key issues involved. With the recent proliferation of humanoid robots, we further outline the rapid rise of analogous methods for bipedal locomotion. We conclude with a discussion of open problems as well as related societal impact.
Flexible Motion In-betweening with Diffusion Models
May 17, 2024Motion in-betweening, a fundamental task in character animation, consists of generating motion sequences that plausibly interpolate user-provided keyframe constraints. It has long been recognized as a labor-intensive and challenging process. We investigate the potential of diffusion models in generating diverse human motions guided by keyframes. Unlike previous inbetweening methods, we propose a simple unified model capable of generating precise and diverse motions that conform to a flexible range of user-specified spatial constraints, as well as text conditioning. To this end, we propose Conditional Motion Diffusion In-betweening (CondMDI) which allows for arbitrary dense-or-sparse keyframe placement and partial keyframe constraints while generating high-quality motions that are diverse and coherent with the given keyframes. We evaluate the performance of CondMDI on the text-conditioned HumanML3D dataset and demonstrate the versatility and efficacy of diffusion models for keyframe in-betweening. We further explore the use of guidance and imputation-based approaches for inference-time keyframing and compare CondMDI against these methods.
Physics-based Motion Retargeting from Sparse Inputs
Jul 04, 2023



Avatars are important to create interactive and immersive experiences in virtual worlds. One challenge in animating these characters to mimic a user's motion is that commercial AR/VR products consist only of a headset and controllers, providing very limited sensor data of the user's pose. Another challenge is that an avatar might have a different skeleton structure than a human and the mapping between them is unclear. In this work we address both of these challenges. We introduce a method to retarget motions in real-time from sparse human sensor data to characters of various morphologies. Our method uses reinforcement learning to train a policy to control characters in a physics simulator. We only require human motion capture data for training, without relying on artist-generated animations for each avatar. This allows us to use large motion capture datasets to train general policies that can track unseen users from real and sparse data in real-time. We demonstrate the feasibility of our approach on three characters with different skeleton structure: a dinosaur, a mouse-like creature and a human. We show that the avatar poses often match the user surprisingly well, despite having no sensor information of the lower body available. We discuss and ablate the important components in our framework, specifically the kinematic retargeting step, the imitation, contact and action reward as well as our asymmetric actor-critic observations. We further explore the robustness of our method in a variety of settings including unbalancing, dancing and sports motions.
Hierarchical Planning and Control for Box Loco-Manipulation
Jun 15, 2023



Humans perform everyday tasks using a combination of locomotion and manipulation skills. Building a system that can handle both skills is essential to creating virtual humans. We present a physically-simulated human capable of solving box rearrangement tasks, which requires a combination of both skills. We propose a hierarchical control architecture, where each level solves the task at a different level of abstraction, and the result is a physics-based simulated virtual human capable of rearranging boxes in a cluttered environment. The control architecture integrates a planner, diffusion models, and physics-based motion imitation of sparse motion clips using deep reinforcement learning. Boxes can vary in size, weight, shape, and placement height. Code and trained control policies are provided.
Understanding the Evolution of Linear Regions in Deep Reinforcement Learning
Oct 24, 2022



Policies produced by deep reinforcement learning are typically characterised by their learning curves, but they remain poorly understood in many other respects. ReLU-based policies result in a partitioning of the input space into piecewise linear regions. We seek to understand how observed region counts and their densities evolve during deep reinforcement learning using empirical results that span a range of continuous control tasks and policy network dimensions. Intuitively, we may expect that during training, the region density increases in the areas that are frequently visited by the policy, thereby affording fine-grained control. We use recent theoretical and empirical results for the linear regions induced by neural networks in supervised learning settings for grounding and comparison of our results. Empirically, we find that the region density increases only moderately throughout training, as measured along fixed trajectories coming from the final policy. However, the trajectories themselves also increase in length during training, and thus the region densities decrease as seen from the perspective of the current trajectory. Our findings suggest that the complexity of deep reinforcement learning policies does not principally emerge from a significant growth in the complexity of functions observed on-and-around trajectories of the policy.
OPT-Mimic: Imitation of Optimized Trajectories for Dynamic Quadruped Behaviors
Oct 03, 2022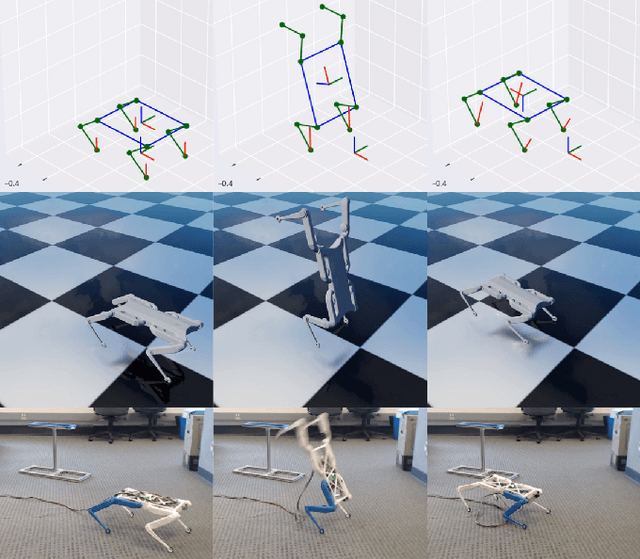
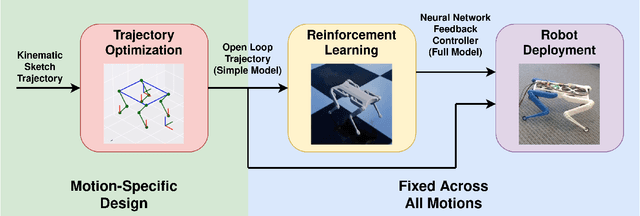
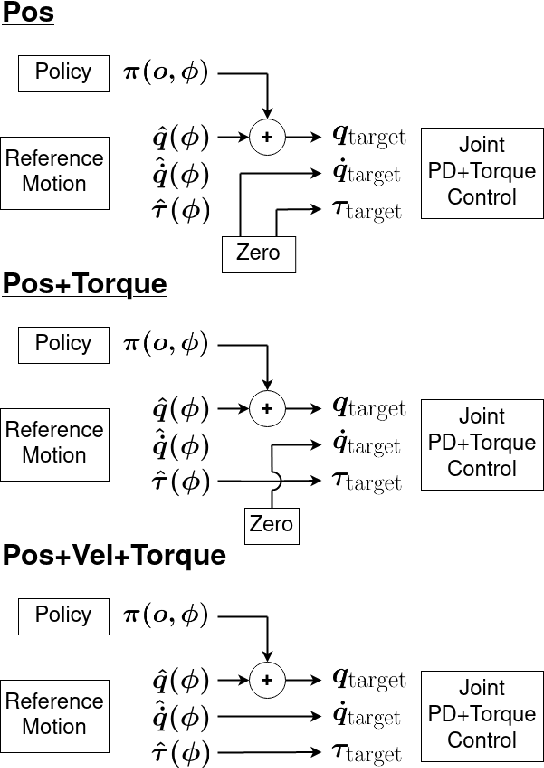
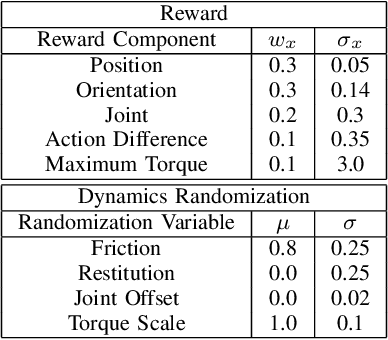
Reinforcement Learning (RL) has seen many recent successes for quadruped robot control. The imitation of reference motions provides a simple and powerful prior for guiding solutions towards desired solutions without the need for meticulous reward design. While much work uses motion capture data or hand-crafted trajectories as the reference motion, relatively little work has explored the use of reference motions coming from model-based trajectory optimization. In this work, we investigate several design considerations that arise with such a framework, as demonstrated through four dynamic behaviours: trot, front hop, 180 backflip, and biped stepping. These are trained in simulation and transferred to a physical Solo 8 quadruped robot without further adaptation. In particular, we explore the space of feed-forward designs afforded by the trajectory optimizer to understand its impact on RL learning efficiency and sim-to-real transfer. These findings contribute to the long standing goal of producing robot controllers that combine the interpretability and precision of model-based optimization with the robustness that model-free RL-based controllers offer.
Learning to Brachiate via Simplified Model Imitation
May 08, 2022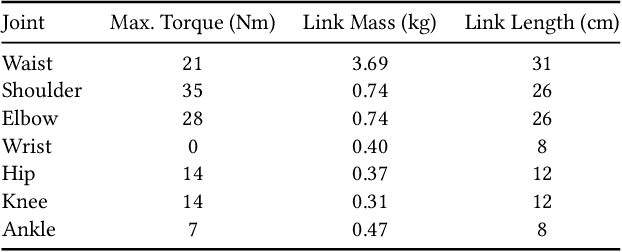
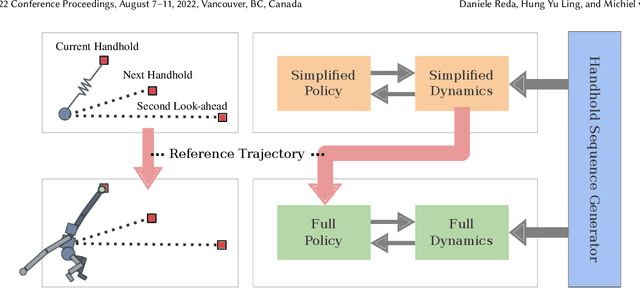

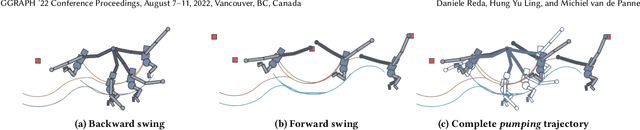
Brachiation is the primary form of locomotion for gibbons and siamangs, in which these primates swing from tree limb to tree limb using only their arms. It is challenging to control because of the limited control authority, the required advance planning, and the precision of the required grasps. We present a novel approach to this problem using reinforcement learning, and as demonstrated on a finger-less 14-link planar model that learns to brachiate across challenging handhold sequences. Key to our method is the use of a simplified model, a point mass with a virtual arm, for which we first learn a policy that can brachiate across handhold sequences with a prescribed order. This facilitates the learning of the policy for the full model, for which it provides guidance by providing an overall center-of-mass trajectory to imitate, as well as for the timing of the holds. Lastly, the simplified model can also readily be used for planning suitable sequences of handholds in a given environment. Our results demonstrate brachiation motions with a variety of durations for the flight and hold phases, as well as emergent extra back-and-forth swings when this proves useful. The system is evaluated with a variety of ablations. The method enables future work towards more general 3D brachiation, as well as using simplified model imitation in other settings.
Learning to Get Up
Apr 30, 2022
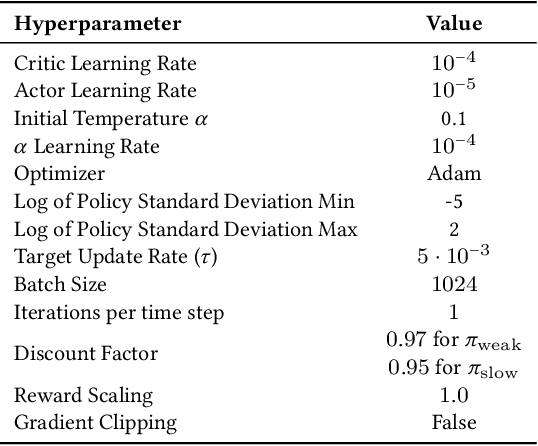
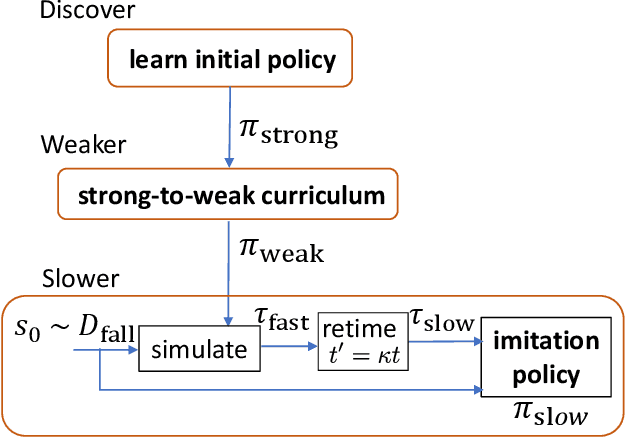
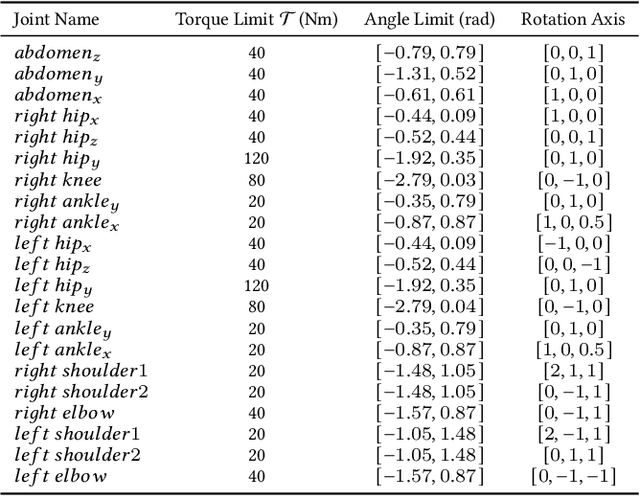
Getting up from an arbitrary fallen state is a basic human skill. Existing methods for learning this skill often generate highly dynamic and erratic get-up motions, which do not resemble human get-up strategies, or are based on tracking recorded human get-up motions. In this paper, we present a staged approach using reinforcement learning, without recourse to motion capture data. The method first takes advantage of a strong character model, which facilitates the discovery of solution modes. A second stage then learns to adapt the control policy to work with progressively weaker versions of the character. Finally, a third stage learns control policies that can reproduce the weaker get-up motions at much slower speeds. We show that across multiple runs, the method can discover a diverse variety of get-up strategies, and execute them at a variety of speeds. The results usually produce policies that use a final stand-up strategy that is common to the recovery motions seen from all initial states. However, we also find policies for which different strategies are seen for prone and supine initial fallen states. The learned get-up control strategies often have significant static stability, i.e., they can be paused at a variety of points during the get-up motion. We further test our method on novel constrained scenarios, such as having a leg and an arm in a cast.