 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Aggregate and Personalize 3D Face from In-the-Wild Photo Collection
Jun 15, 2021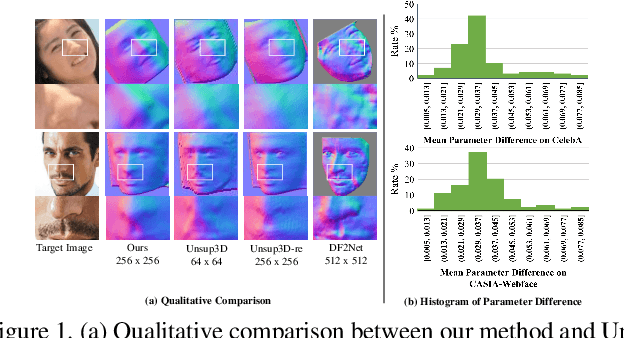
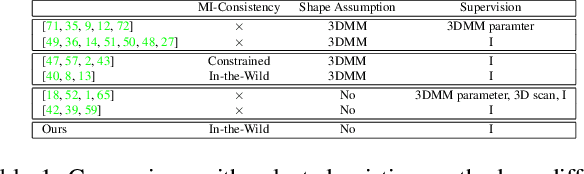
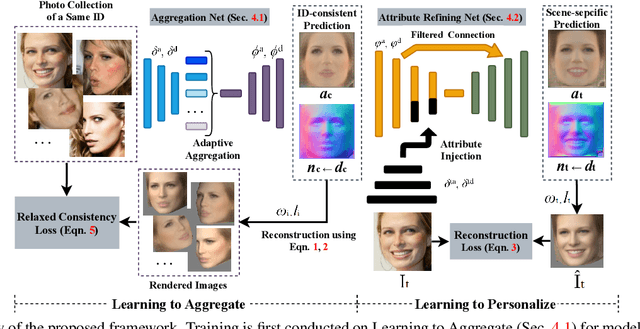
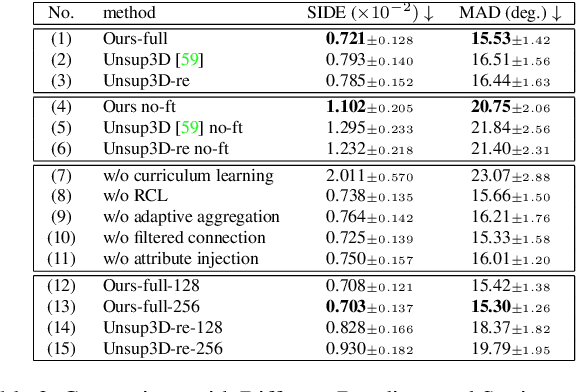
Non-parametric face modeling aims to reconstruct 3D face only from images without shape assumptions. While plausible facial details are predicted, the models tend to over-depend on local color appearance and suffer from ambiguous noise. To address such problem, this paper presents a novel Learning to Aggregate and Personalize (LAP) framework for unsupervised robust 3D face modeling. Instead of using controlled environment, the proposed method implicitly disentangles ID-consistent and scene-specific face from unconstrained photo set. Specifically, to learn ID-consistent face, LAP adaptively aggregates intrinsic face factors of an identity based on a novel curriculum learning approach with relaxed consistency loss. To adapt the face for a personalized scene, we propose a novel attribute-refining network to modify ID-consistent face with target attribute and details. Based on the proposed method, we make unsupervised 3D face modeling benefit from meaningful image facial structure and possibly higher resolutions. Extensive experiments on benchmarks show LAP recovers superior or competitive face shape and texture, compared with state-of-the-art (SOTA) methods with or without prior and supervision.
Consistent Instance False Positive Improves Fairness in Face Recognition
Jun 10, 2021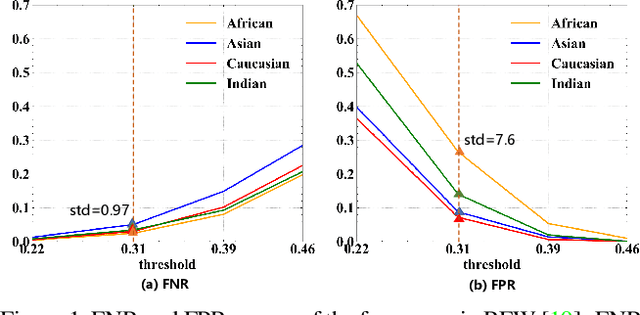
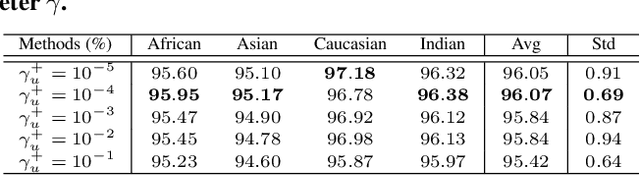
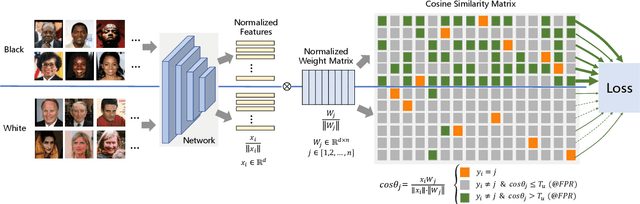
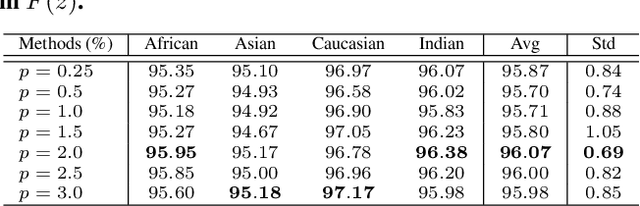
Demographic bias is a significant challenge in practical face recognition systems. Existing methods heavily rely on accurate demographic annotations. However, such annotations are usually unavailable in real scenarios. Moreover, these methods are typically designed for a specific demographic group and are not general enough. In this paper, we propose a false positive rate penalty loss, which mitigates face recognition bias by increasing the consistency of instance False Positive Rate (FPR). Specifically, we first define the instance FPR as the ratio between the number of the non-target similarities above a unified threshold and the total number of the non-target similarities. The unified threshold is estimated for a given total FPR. Then, an additional penalty term, which is in proportion to the ratio of instance FPR overall FPR, is introduced into the denominator of the softmax-based loss. The larger the instance FPR, the larger the penalty. By such unequal penalties, the instance FPRs are supposed to be consistent. Compared with the previous debiasing methods, our method requires no demographic annotations. Thus, it can mitigate the bias among demographic groups divided by various attributes, and these attributes are not needed to be previously predefined during training. Extensive experimental results on popular benchmarks demonstrate the superiority of our method over state-of-the-art competitors. Code and trained models are available at https://github.com/Tencent/TFace.
Adv-Makeup: A New Imperceptible and Transferable Attack on Face Recognition
May 07, 2021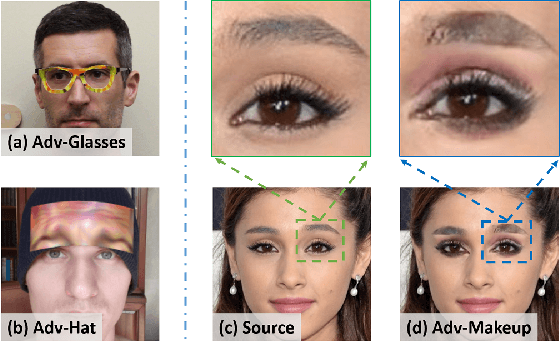
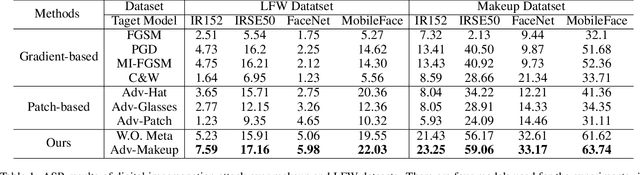
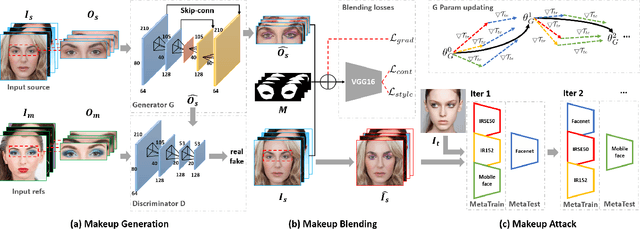
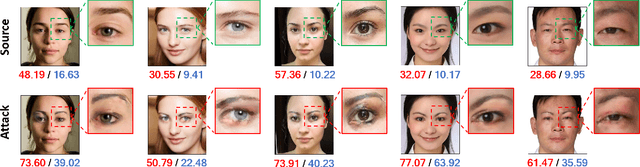
Deep neural networks, particularly face recognition models, have been shown to be vulnerable to both digital and physical adversarial examples. However, existing adversarial examples against face recognition systems either lack transferability to black-box models, or fail to be implemented in practice. In this paper, we propose a unified adversarial face generation method - Adv-Makeup, which can realize imperceptible and transferable attack under black-box setting. Adv-Makeup develops a task-driven makeup generation method with the blending module to synthesize imperceptible eye shadow over the orbital region on faces. And to achieve transferability, Adv-Makeup implements a fine-grained meta-learning adversarial attack strategy to learn more general attack features from various models. Compared to existing techniques, sufficient visualization results demonstrate that Adv-Makeup is capable to generate much more imperceptible attacks under both digital and physical scenarios. Meanwhile, extensive quantitative experiments show that Adv-Makeup can significantly improve the attack success rate under black-box setting, even attacking commercial systems.
Local Relation Learning for Face Forgery Detection
May 06, 2021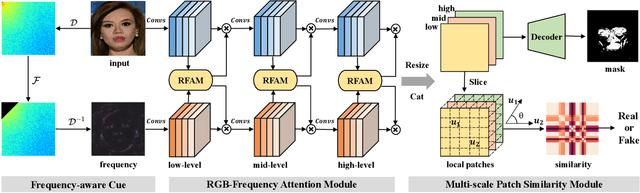
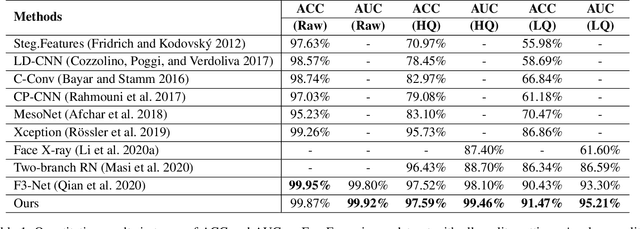
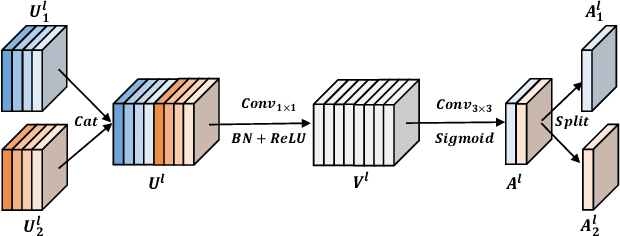
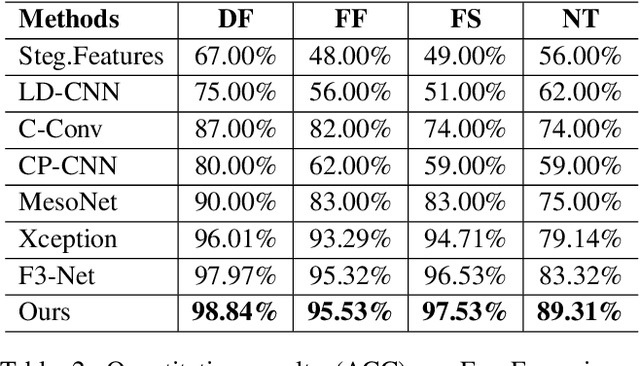
With the rapid development of facial manipulation techniques, face forgery detection has received considerable attention in digital media forensics due to security concerns. Most existing methods formulate face forgery detection as a classification problem and utilize binary labels or manipulated region masks as supervision. However, without considering the correlation between local regions, these global supervisions are insufficient to learn a generalized feature and prone to overfitting. To address this issue, we propose a novel perspective of face forgery detection via local relation learning. Specifically, we propose a Multi-scale Patch Similarity Module (MPSM), which measures the similarity between features of local regions and forms a robust and generalized similarity pattern. Moreover, we propose an RGB-Frequency Attention Module (RFAM) to fuse information in both RGB and frequency domains for more comprehensive local feature representation, which further improves the reliability of the similarity pattern. Extensive experiments show that the proposed method consistently outperforms the state-of-the-arts on widely-used benchmarks. Furthermore, detailed visualization shows the robustness and interpretability of our method.
Generalizable Representation Learning for Mixture Domain Face Anti-Spoofing
May 06, 2021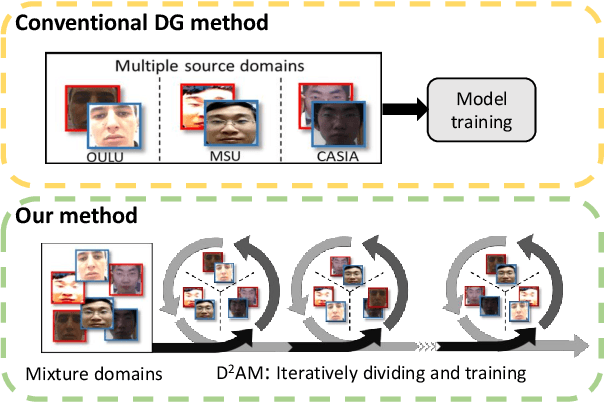
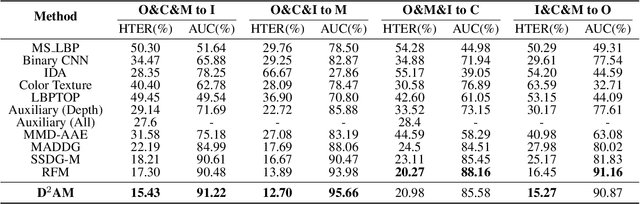
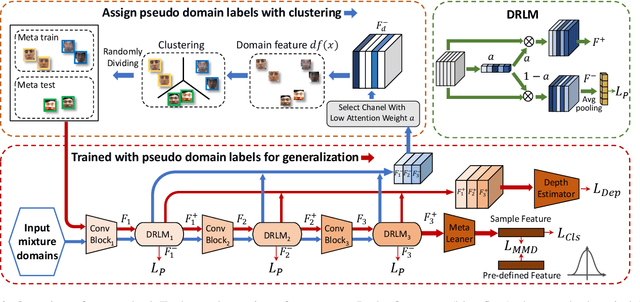
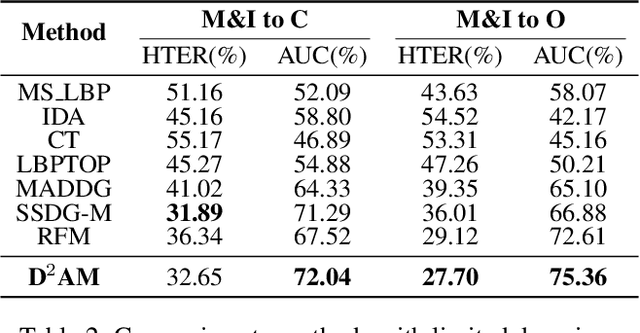
Face anti-spoofing approach based on domain generalization(DG) has drawn growing attention due to its robustness forunseen scenarios. Existing DG methods assume that the do-main label is known.However, in real-world applications, thecollected dataset always contains mixture domains, where thedomain label is unknown. In this case, most of existing meth-ods may not work. Further, even if we can obtain the domainlabel as existing methods, we think this is just a sub-optimalpartition. To overcome the limitation, we propose domain dy-namic adjustment meta-learning (D2AM) without using do-main labels, which iteratively divides mixture domains viadiscriminative domain representation and trains a generaliz-able face anti-spoofing with meta-learning. Specifically, wedesign a domain feature based on Instance Normalization(IN) and propose a domain representation learning module(DRLM) to extract discriminative domain features for cluster-ing. Moreover, to reduce the side effect of outliers on cluster-ing performance, we additionally utilize maximum mean dis-crepancy (MMD) to align the distribution of sample featuresto a prior distribution, which improves the reliability of clus tering. Extensive experiments show that the proposed methodoutperforms conventional DG-based face anti-spoofing meth-ods, including those utilizing domain labels. Furthermore, weenhance the interpretability through visualizatio
Delving into Data: Effectively Substitute Training for Black-box Attack
Apr 26, 2021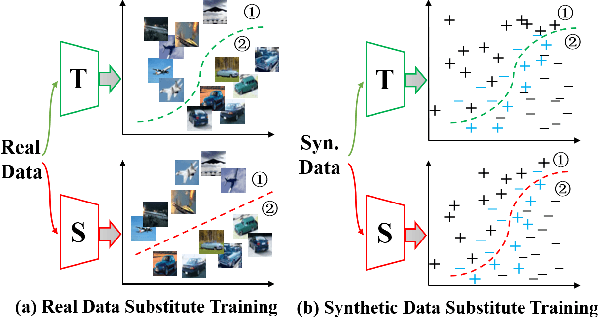
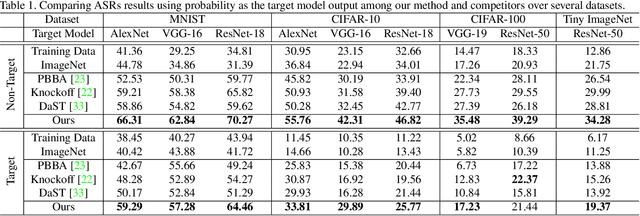
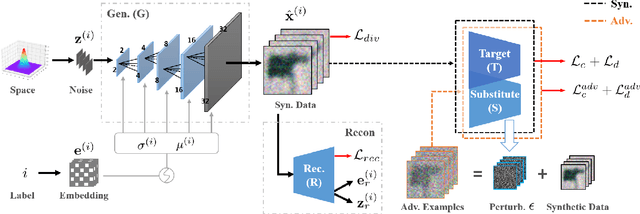
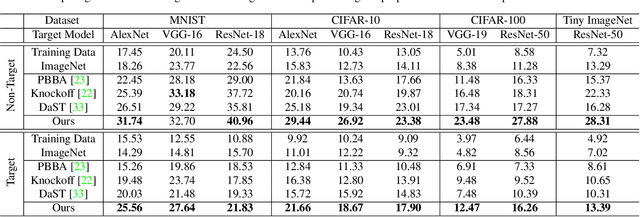
Deep models have shown their vulnerability when processing adversarial samples. As for the black-box attack, without access to the architecture and weights of the attacked model, training a substitute model for adversarial attacks has attracted wide attention. Previous substitute training approaches focus on stealing the knowledge of the target model based on real training data or synthetic data, without exploring what kind of data can further improve the transferability between the substitute and target models. In this paper, we propose a novel perspective substitute training that focuses on designing the distribution of data used in the knowledge stealing process. More specifically, a diverse data generation module is proposed to synthesize large-scale data with wide distribution. And adversarial substitute training strategy is introduced to focus on the data distributed near the decision boundary. The combination of these two modules can further boost the consistency of the substitute model and target model, which greatly improves the effectiveness of adversarial attack. Extensive experiments demonstrate the efficacy of our method against state-of-the-art competitors under non-target and target attack settings. Detailed visualization and analysis are also provided to help understand the advantage of our method.
Learning Dynamic Alignment via Meta-filter for Few-shot Learning
Mar 25, 2021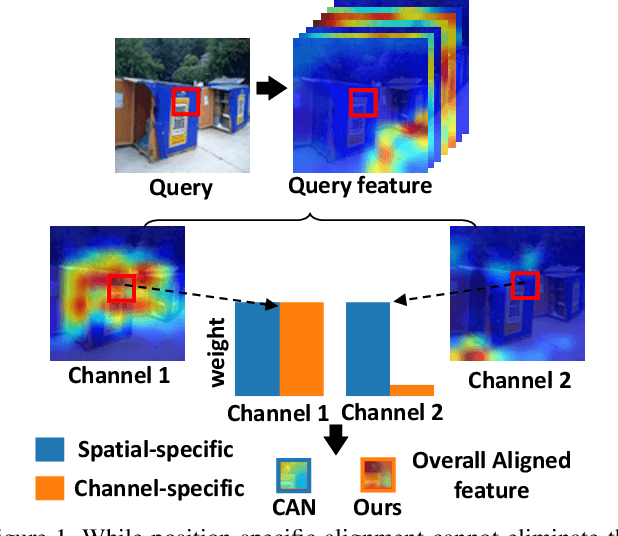
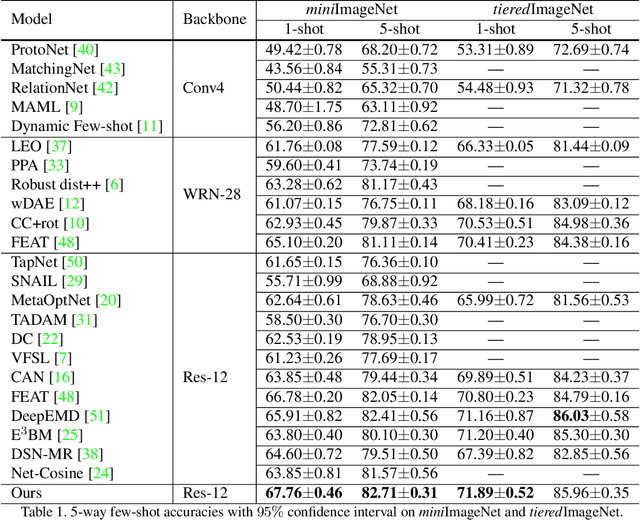
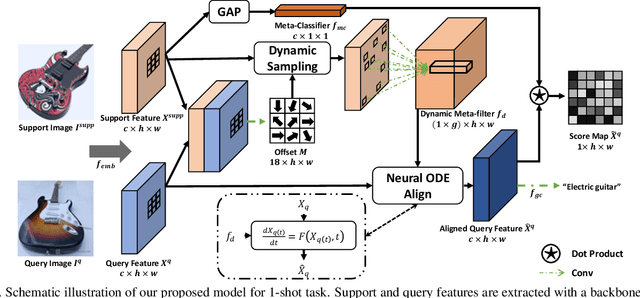

Few-shot learning (FSL), which aims to recognise new classes by adapting the learned knowledge with extremely limited few-shot (support) examples, remains an important open problem in computer vision. Most of the existing methods for feature alignment in few-shot learning only consider image-level or spatial-level alignment while omitting the channel disparity. Our insight is that these methods would lead to poor adaptation with redundant matching, and leveraging channel-wise adjustment is the key to well adapting the learned knowledge to new classes. Therefore, in this paper, we propose to learn a dynamic alignment, which can effectively highlight both query regions and channels according to different local support information. Specifically, this is achieved by first dynamically sampling the neighbourhood of the feature position conditioned on the input few shot, based on which we further predict a both position-dependent and channel-dependent Dynamic Meta-filter. The filter is used to align the query feature with position-specific and channel-specific knowledge. Moreover, we adopt Neural Ordinary Differential Equation (ODE) to enable a more accurate control of the alignment. In such a sense our model is able to better capture fine-grained semantic context of the few-shot example and thus facilitates dynamical knowledge adaptation for few-shot learning. The resulting framework establishes the new state-of-the-arts on major few-shot visual recognition benchmarks, including miniImageNet and tieredImageNet.
Learning Salient Boundary Feature for Anchor-free Temporal Action Localization
Mar 24, 2021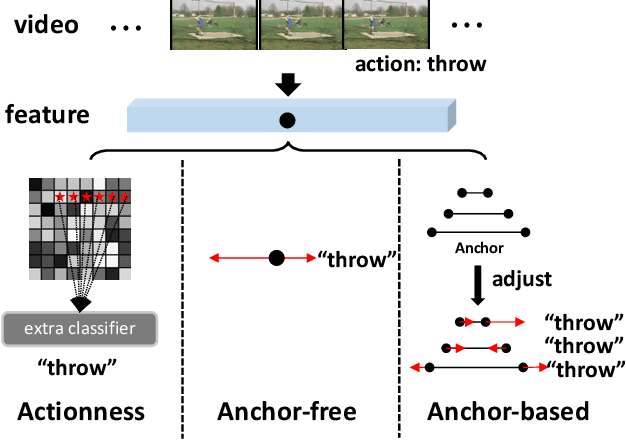
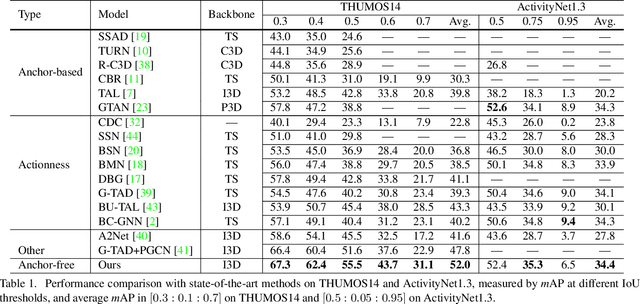


Temporal action localization is an important yet challenging task in video understanding. Typically, such a task aims at inferring both the action category and localization of the start and end frame for each action instance in a long, untrimmed video.While most current models achieve good results by using pre-defined anchors and numerous actionness, such methods could be bothered with both large number of outputs and heavy tuning of locations and sizes corresponding to different anchors. Instead, anchor-free methods is lighter, getting rid of redundant hyper-parameters, but gains few attention. In this paper, we propose the first purely anchor-free temporal localization method, which is both efficient and effective. Our model includes (i) an end-to-end trainable basic predictor, (ii) a saliency-based refinement module to gather more valuable boundary features for each proposal with a novel boundary pooling, and (iii) several consistency constraints to make sure our model can find the accurate boundary given arbitrary proposals. Extensive experiments show that our method beats all anchor-based and actionness-guided methods with a remarkable margin on THUMOS14, achieving state-of-the-art results, and comparable ones on ActivityNet v1.3. Code is available at https://github.com/TencentYoutuResearch/ActionDetection-AFSD.
Learning Comprehensive Motion Representation for Action Recognition
Mar 23, 2021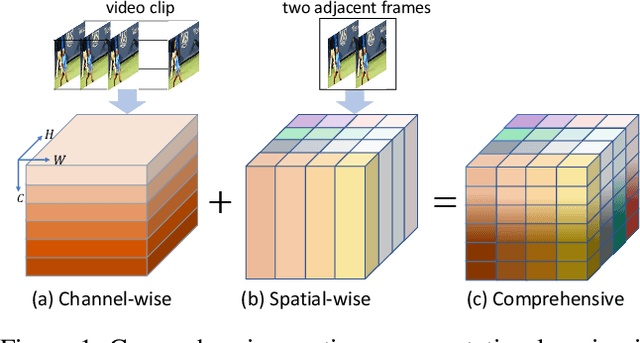
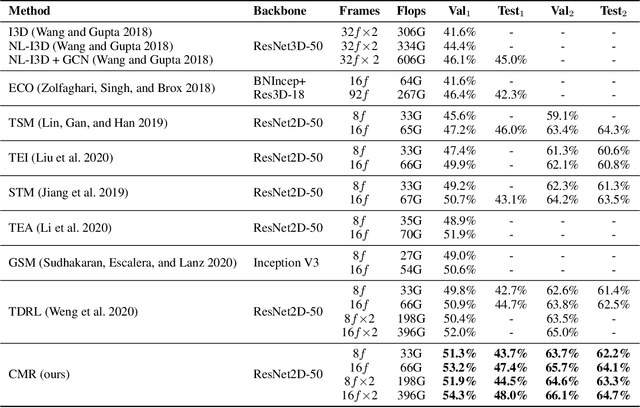
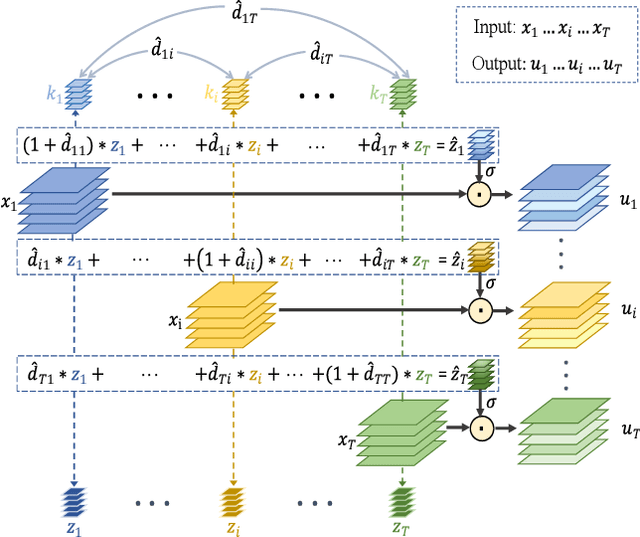
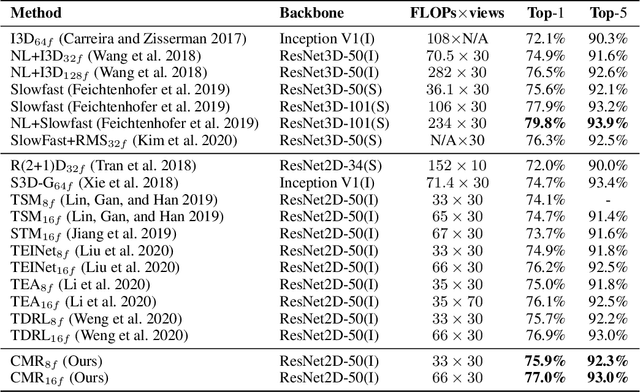
For action recognition learning, 2D CNN-based methods are efficient but may yield redundant features due to applying the same 2D convolution kernel to each frame. Recent efforts attempt to capture motion information by establishing inter-frame connections while still suffering the limited temporal receptive field or high latency. Moreover, the feature enhancement is often only performed by channel or space dimension in action recognition. To address these issues, we first devise a Channel-wise Motion Enhancement (CME) module to adaptively emphasize the channels related to dynamic information with a channel-wise gate vector. The channel gates generated by CME incorporate the information from all the other frames in the video. We further propose a Spatial-wise Motion Enhancement (SME) module to focus on the regions with the critical target in motion, according to the point-to-point similarity between adjacent feature maps. The intuition is that the change of background is typically slower than the motion area. Both CME and SME have clear physical meaning in capturing action clues. By integrating the two modules into the off-the-shelf 2D network, we finally obtain a Comprehensive Motion Representation (CMR) learning method for action recognition, which achieves competitive performance on Something-Something V1 & V2 and Kinetics-400. On the temporal reasoning datasets Something-Something V1 and V2, our method outperforms the current state-of-the-art by 2.3% and 1.9% when using 16 frames as input, respectively.
SDD-FIQA: Unsupervised Face Image Quality Assessment with Similarity Distribution Distance
Mar 10, 2021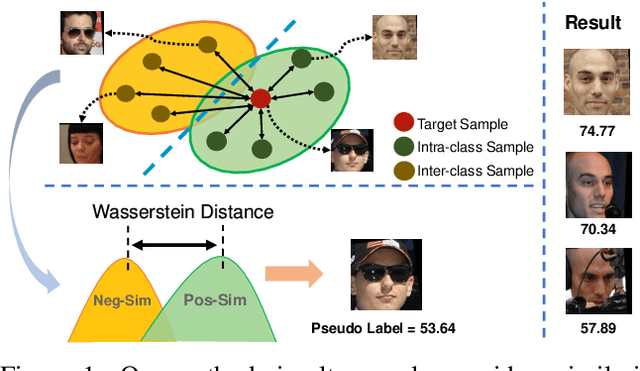
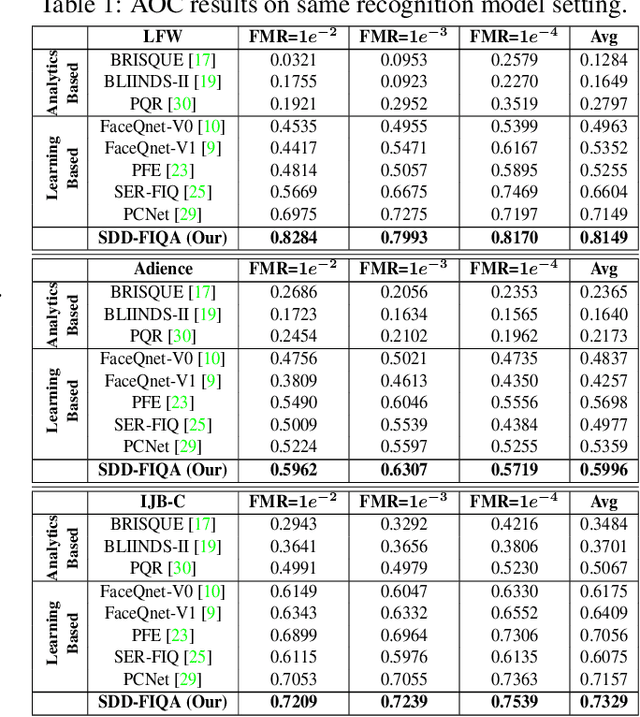
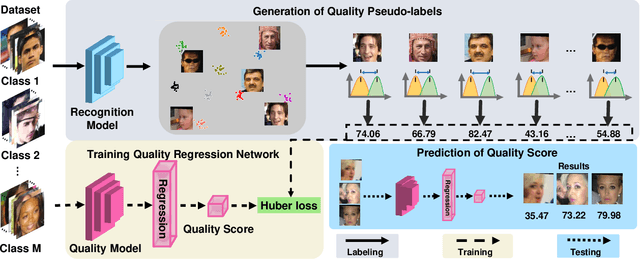
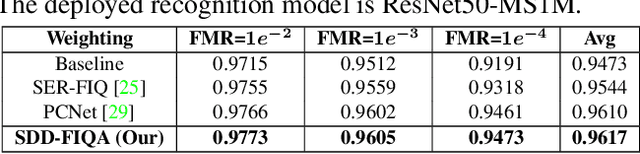
In recent years, Face Image Quality Assessment (FIQA) has become an indispensable part of the face recognition system to guarantee the stability and reliability of recognition performance in an unconstrained scenario. For this purpose, the FIQA method should consider both the intrinsic property and the recognizability of the face image. Most previous works aim to estimate the sample-wise embedding uncertainty or pair-wise similarity as the quality score, which only considers the information from partial intra-class. However, these methods ignore the valuable information from the inter-class, which is for estimating to the recognizability of face image. In this work, we argue that a high-quality face image should be similar to its intra-class samples and dissimilar to its inter-class samples. Thus, we propose a novel unsupervised FIQA method that incorporates Similarity Distribution Distance for Face Image Quality Assessment (SDD-FIQA). Our method generates quality pseudo-labels by calculating the Wasserstein Distance (WD) between the intra-class similarity distributions and inter-class similarity distributions. With these quality pseudo-labels, we are capable of training a regression network for quality prediction. Extensive experiments on benchmark datasets demonstrate that the proposed SDD-FIQA surpasses the state-of-the-arts by an impressive margin. Meanwhile, our method shows good generalization across different recognition systems.